本文主要是介绍按15分钟取数据_【数量技术宅|金融数据分析系列分享】套利策略如何神bin天降五杀,价差计算有诀窍...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

更多精彩内容,欢迎关注公众号:数量技术宅
01 价差计算的“误区”我们在测试两个或多个金融资产相互运算产生的策略信号时,免不了需要涉及将不同的价格时间序列,按照时间轴进行对齐,套利策略就是其中之一。然而,大部分介绍套利策略、统计套利类的文章,对于价差序列的生成计算,处理的十分简单,基本就是两个时间序列相减。对于较为低频的信号,这样处理问题不大,但在中高频的信号领域,直接相减,会存在着一定的问题。
这是因为,对于不同资产的价格序列,存在着交易所推送时间、以及到达时间的差异。即使我们回测时看到的两个Tick的时间戳是完全相同的,在实盘服务器接收推送行情的时候,也是按照先、后顺序达到的。我们在实际交易中发现,比如上海期货交易所某个品种的不同到期交割月的合约,交易所在切片数据的推送不是同时进行的,而是按照交割月的顺序推送的,例如按照RB2010、RB2101、RB2015,类似这样的先后顺序来进行推送的,其他品种也是如此,而对于同一个500ms的切片时间内,收到RB2010、RB2101、RB2015的Tick数据的时间戳,却是相同的。
再比如数字货币的跨交易所套利,两个交易所即使在相同时间发送的Tick数据,由于交易所服务器物理位置间跨度较大,造成的传输时间不同,到达我们策略信号计算服务器的时间大概率也会不同。02 一个典型的价格到达频率不同的例子 如果说行情数据到达时间有先后,直接相减计算价差会有一定的“滞后”或“未来函数”问题的话,价格到达频率不同,则根本就无法直接相减计算价差了。总之,我们需要一套更贴近实际交易的价差计算方式。我们来看一个价格到达频率不同的例子,即两个品种数据的推送频率是不一样的。如果我们需要对股指期货、股票ETF进行期现套利策略的设计,以IC与中证500ETF的数据为例,计算期现套利的价差。
IC股指期货的Tick数据,我们的数据源是Wind,IC对应的中金所,它的行情推送频率是每1秒2笔数据,Level1免费行情推送的是1档盘口,即只有买1、卖1的数据,数据时间是股指期货的交易时间:9:29-15:00。我们来看一下IC的Tick数据样例。
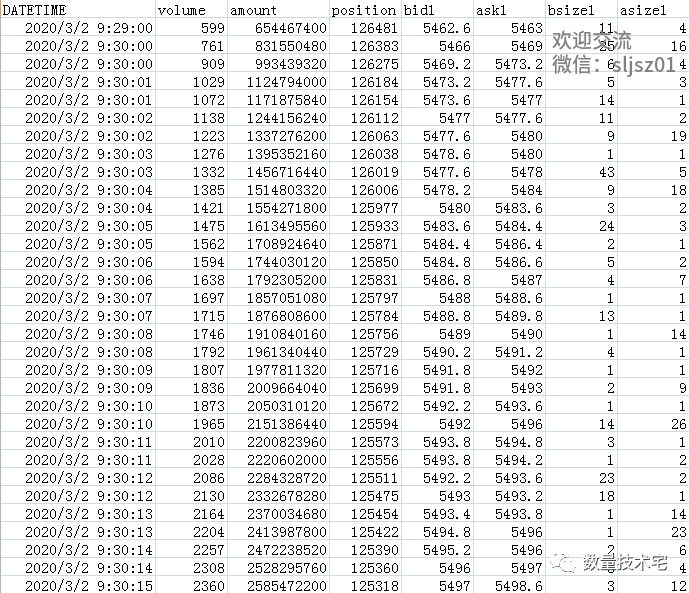
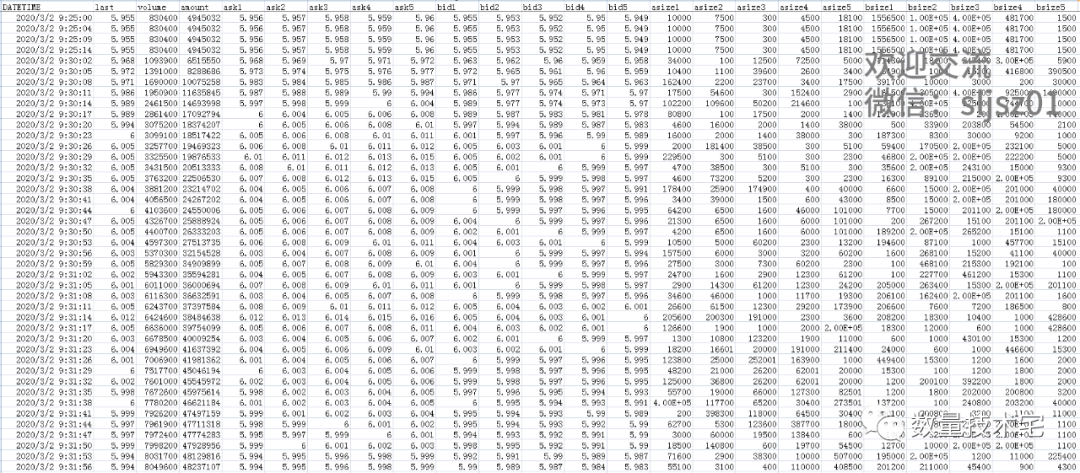
对于这样推送频率有差异、时间轴也有差异的数据,计算价差,我们就需要根据时间轴来进行合成。Python Pandas库的Merge函数,正好符合我们所需要的功能。我们简要介绍一下Merge函数。
pd.merge(left, right, how='inner', on=None, left_on=None, ... )我们在做数据合成的时候,最常用到的是前4组参数:
left: 拼接的左侧DataFrame对象
right: 拼接的右侧DataFrame对象
on: 要加入的列或索引级别名称。必须在左侧和右侧DataFrame对象中找到,对于金融时间序列,一般来说是时间轴
how: One of ‘left’, ‘right’, ‘outer’, ‘inner’,默认inner。inner是取交集,outer取并集。比如left:[‘A’,‘B’,‘C’];right[’'A,‘C’,‘D’];inner取交集的话,left中出现的A会和right中出现的买一个A进行匹配拼接,如果没有是B,在right中没有匹配到,则会丢失。'outer’取并集,出现的A会进行一一匹配,没有同时出现的会将缺失的部分添加缺失值。
而这4组参数,对于套利价差计算的预处理,how字段最重要。我们用实际的数据,来看不同how字段的取值,会对最终价差的计算,带来怎样的影响。
首先,how = “inner”,取时间轴的交集,只有两个表DATETIME列都有的时间,才会出现在最终的总表。我们展示计算得到的总表,并计算价差序列后绘图。
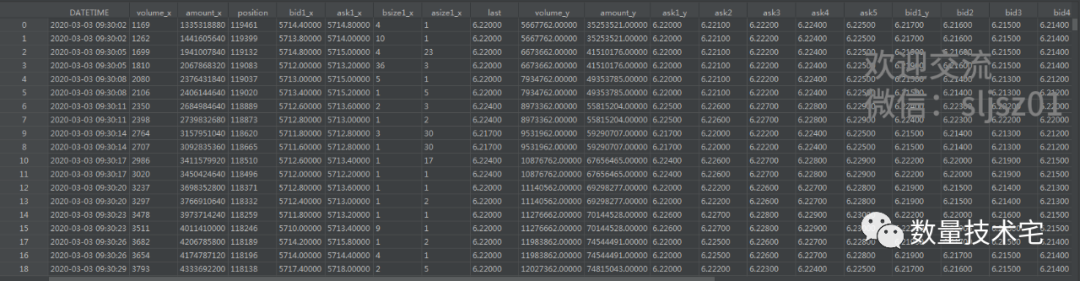
其次,how = “outer”,取时间轴的并集,只要两个表DATETIME列任意一表有的时间,都会出现在最终的总表,若另一个表没有数据,则按nan值填充。
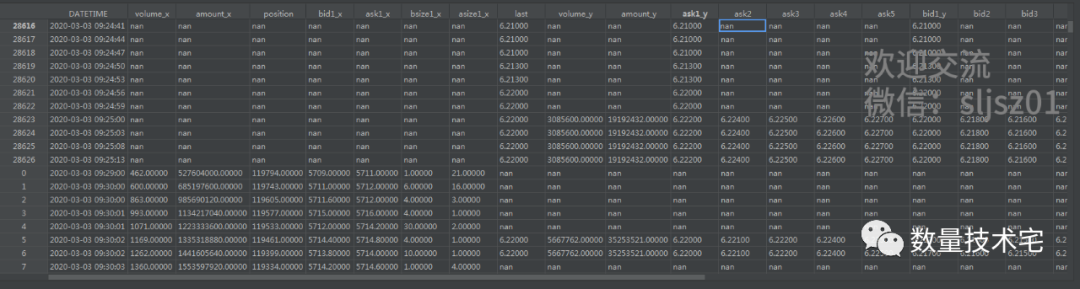
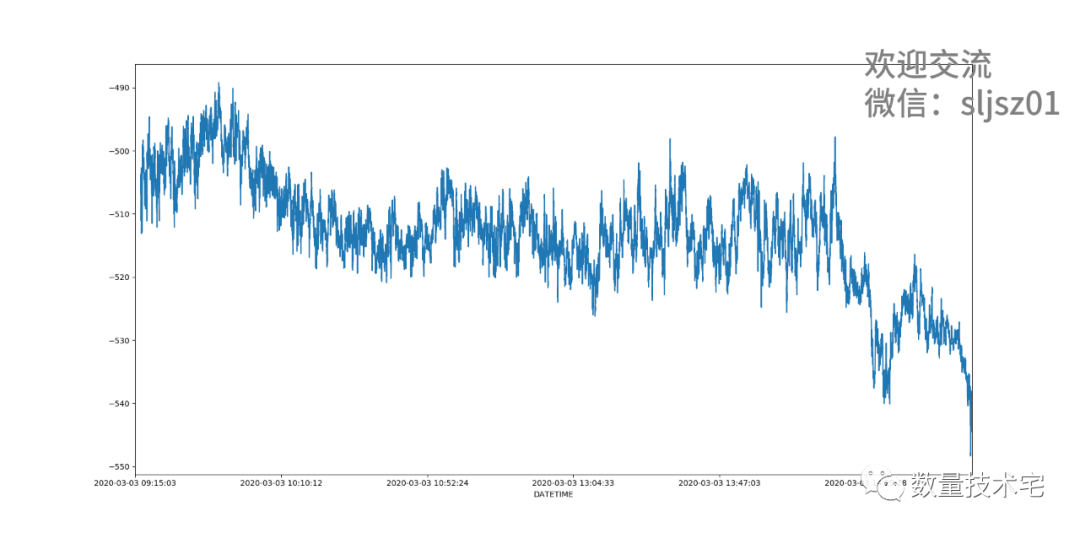
由于outer的数据处理方式,存在着大量的nan值,我们无法直接计算价差,通常的处理方式是前向填充空值数据,即将nan值用离得最近的非空值进行填充替代,再计算期现(中间价)价差,并绘图。
再次,how = 'left',按左表时间轴合并。按左表(IC)的时间轴与右表逐一匹配,左表的时间轴全部保留,右表有该时间的,则并入总表,右表没有该时间的,以nan代替。
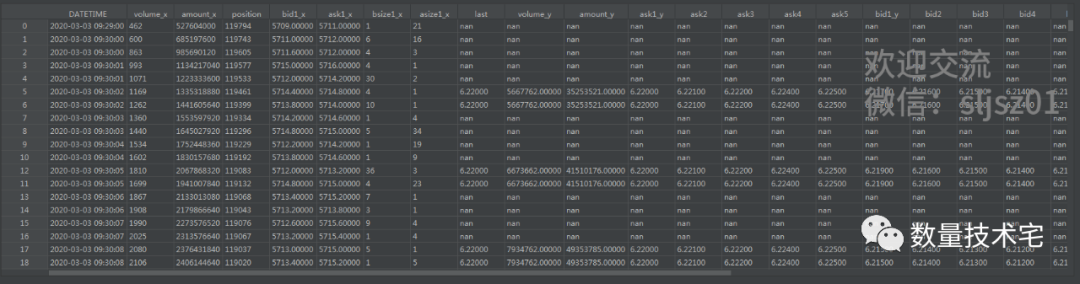
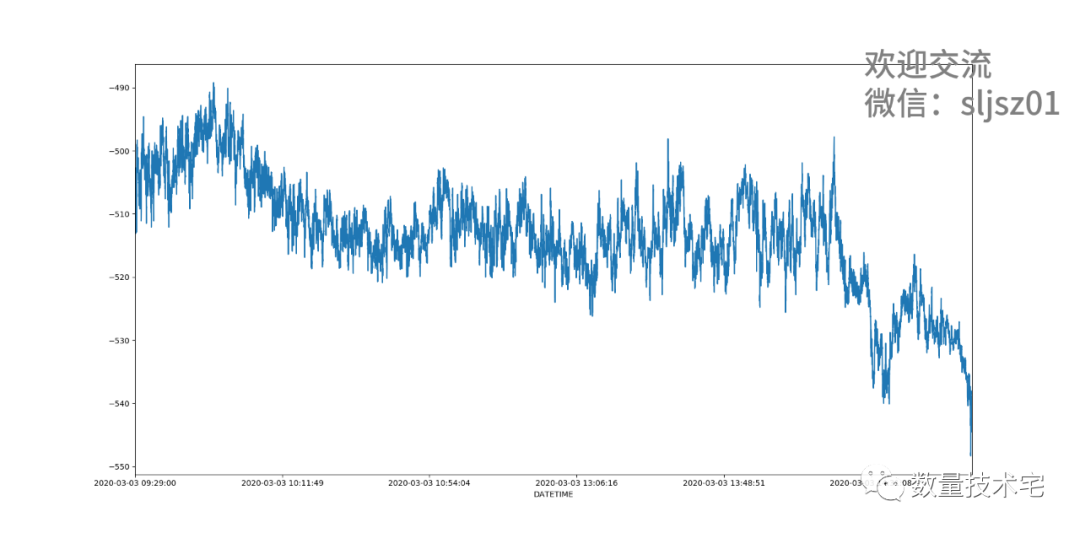
同样需要前向填充空值数据,然后才能计算期现(中间价)价差。
最后,how = 'right',按右表时间轴合并。按右表(500ETF)的时间轴与左表逐一匹配,右表的时间轴全部保留,左表有该时间的,则并入总表,左表没有改时间的,以nan代替。
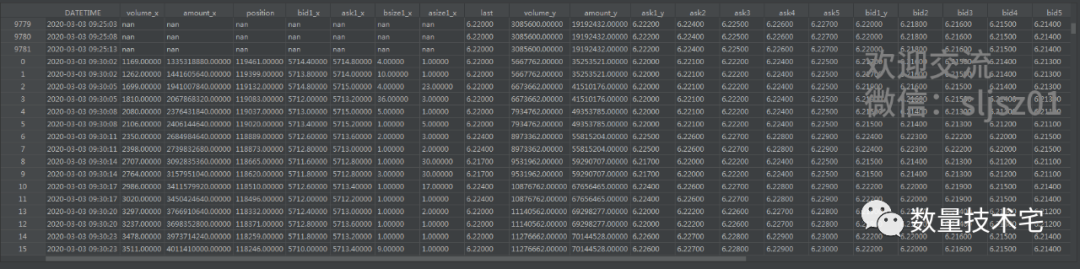
由于期货数据频率相比股票ETF更高,nan主要出现在股票比期货集合竞价更早的阶段,这部分nan数据可酌情删除。
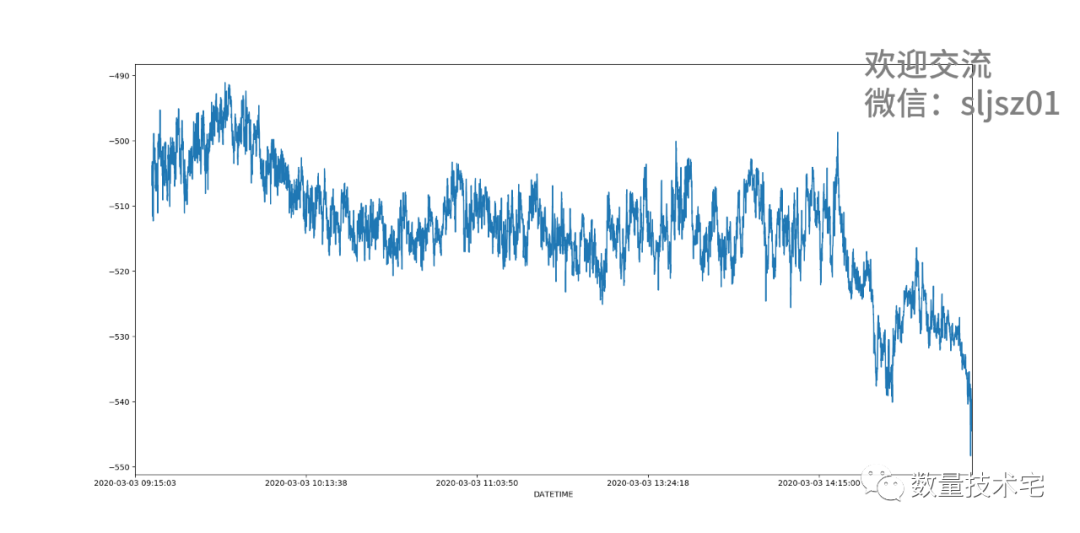
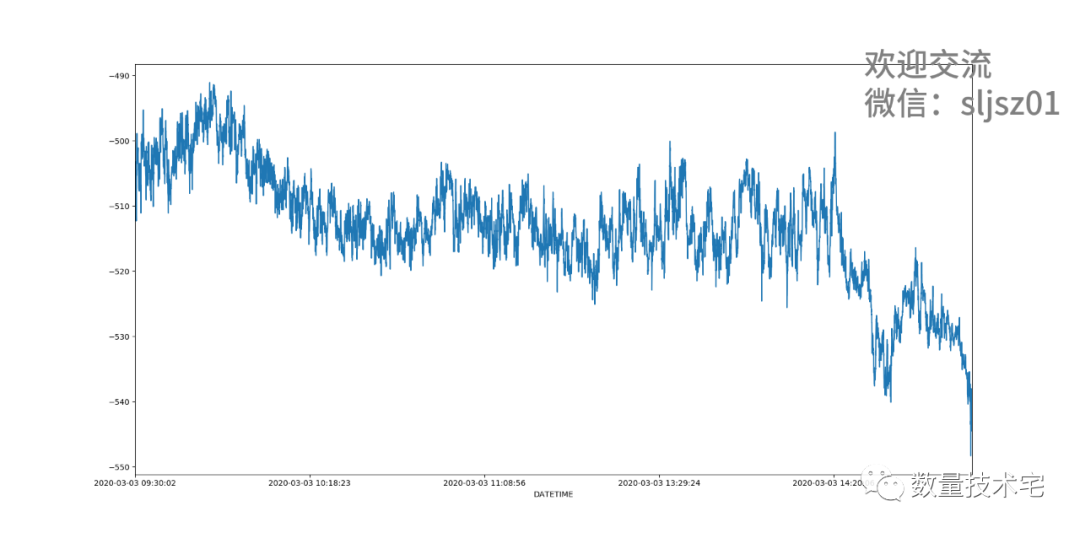
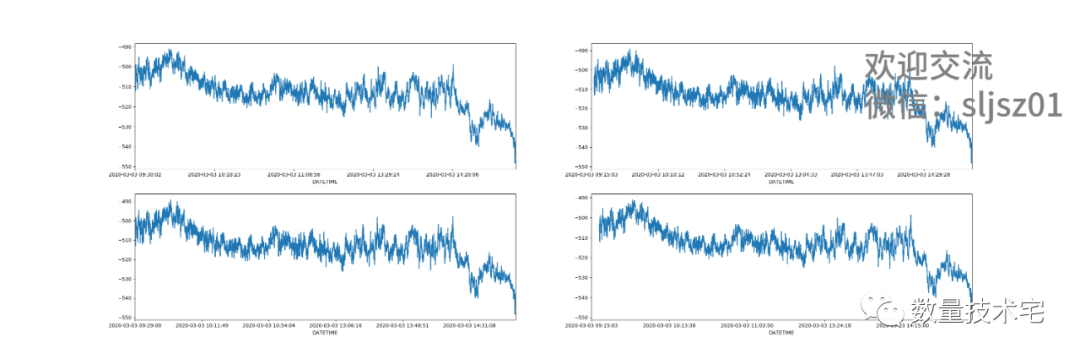
我们将不同价差计算方式所绘制的图合并到一起,可以看到,左上how="inner"的图,点最为稀疏,因为需要同时两个价格在该时刻都有数据,才会计算价差;而右上how="outer"的图,价差点最为密集,只需其中一组价格变动,就会计算1次价差,而下方的两张图how="left"、how="right",密集程度位于两者之间。
价差不同的计算方式,表面来看是Merge函数所选择how的参数不同,造成的价差序列计算结果不同。然而不同how参数的选择,背后实则对应着不同的策略原理、策略逻辑。
我们无论在策略的回测中,对待行情数据,都需要采用一种“事件驱动”的方式来进行测试,这是最贴近实盘交易的回测方式。我们假设历史数据也是像实盘那样,每生成一个新的数据,推送给我们一次,而我们每收到一个新的数据,相当于是一个新的事件,这个事件驱动了后续的策略信号计算,以及信号对应的开平仓条件的判断。
我们再回到价差不同的计算方式,其对应的,实则是策略不同的驱动方式。
how=‘outer’:对应的是期货、股票双路行情的并发驱动,即只要有股票、期货任意数据的更新,我们的程序就更新价差,判断是否触发交易信号,此时的信号计算和触发,最为频繁。
how = 'left':对应的是期货行情的单路驱动,即我们不管股票行情是否到达,只要期货数据更新,股票采用最新存储的数据合并计算价差,并判断是否触发交易信号。
how = 'right':对应股票行情的单路驱动,即我们不管期货行情达到与否,只要股票数据更新,期货用最新存储的数据合并计算价差,并判断是否触发交易信号,left和right的触发方式,信号不如outer频繁。
how=‘inner’:对应的是期货、股票双路行情同时驱动,我们一般在回测、实盘中均不采用这种方式,在本文第一小节,为大家介绍过,行情基本上不可能同时到达,这种驱动方式太过理想化,也会在无形中减少很多交易机会。
05 实盘交易应该选用的驱动方式综上,我们在回测、交易中可选的交易方式,可以分为两大类:双路行情的并发驱动、单路行情的驱动。那么,这两大类不同的驱动方式,究竟又该如何选择?
笔者根据统计套利策略的实盘交易经验,提出如下几点建议:
计算价差的两类资产,有明确的活跃度区分、从属关系:例如期货的远近月(近月合约的交易活跃度通常大于远月)、股票与股指期货的期现套利(股指期货对于股票现货有价格发现的作用)等,此时应该以交易活跃、具有领先作用的品种,作为主驱动品种,采用单路行情的驱动。
计算价差的两类资产,无明确区分、从属关系:例如数字货币的跨交易所套利(OKEX、火币交易所之间的套利,活跃程度相当,关系对等),可以采用双路行情的并发驱动,以此来捕捉更多的交易机会。
一旦确定了驱动方式,在数据合并、回测、以及实盘交易系统的开发中,都需要采用同一种驱动方式,以最大程度确保回测结果与实盘交易的一致性。
如果你对于本期分享的内容有任何问题或建议,欢迎添加技术宅微信:sljsz01,与我交流


往期干货
【数量技术宅|量化投资策略系列分享】成熟交易者期货持仓跟随策略
如何获取免费的数字货币历史数据
【数量技术宅|量化投资策略系列分享】多周期共振交易策略
【数量技术宅|金融数据分析系列分享】为什么中证500(IC)是最适合长期做多的指数
【数量技术宅 | Python爬虫系列分享】现货数据不好拿?商品季节性难跟踪?一键解决没烦恼的爬虫分享
【数量技术宅|金融数据分析系列分享】如何正确抄底商品期货、大宗商品
【数量技术宅|量化投资策略系列分享】股指期货IF分钟波动率统计策略
【数量技术宅 | Python爬虫系列分享】实时监控股市重大公告的Python爬虫
这篇关于按15分钟取数据_【数量技术宅|金融数据分析系列分享】套利策略如何神bin天降五杀,价差计算有诀窍...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





