本文主要是介绍【赛事基线】“深水云脑”居民小区二次供水需求预测Baseline之DL,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
v1.1 说明
-
运行此notebook需要比赛数据,请到比赛官网注册报名后下载,并放置到对应的目录(
'./work/data/')下面! -
更新一下当时的排名

-
如果要达到上面的这个分数,可以结合另一个基线的方法。
序
之前写了个【赛事基线】“深水云脑”水质净化厂工艺控制-曝气量预测Baseline之DL,同时,“深水云脑”系列的比赛还有一个《居民小区二次供水需求预测》,同样也是时间序列问题,那就趁热打铁把这个比赛的Baseline也做了~
本文大体分为:
- 赛题分析
- 基线代码
- 结果分析
黑喂狗 ~~~
赛题分析
1. 赛题与数据
摘一下赛题任务:
本次赛题主要通过居民小区智能水表总表读数和二次供水泵后流量计历史数据,结合气象、疫情数据等互联网相关数据进行回归、时序建模,以建立该区域居民小区需水预测模型。利用举办方提供的多个居民小区历史用水数据和感知数据,预测特定周期内不同小区每小时需水量,以指导实际供水运行工作。

直接看数据说话 ~
注意: 这里不提供数据集,运行的时候需要先去报名比赛,然后把相应数据放到对应的目录里面!!!
!pip install --user -q -r requirements.txt
import os
import numpy as np
import pandas as pd
import time
import functoolsfrom sklearn.metrics import mean_squared_error as mse
from sklearn.metrics import mean_absolute_error as mae
from sklearn.metrics import mean_squared_log_error as msle
from sklearn.model_selection import StratifiedKFold, KFold
import matplotlib.pyplot as plt
%matplotlib inline
DATA_PATH = './work/data/'
df_daily = pd.read_csv(DATA_PATH + 'daily_dataset.csv')
df_min = pd.read_csv(DATA_PATH + 'per5min_dataset.csv')
df_hour = pd.read_csv(DATA_PATH + 'hourly_dataset.csv')
df_test = pd.read_csv(DATA_PATH + 'test_public.csv')
df_sub = pd.read_csv(DATA_PATH + 'sample_submission.csv')
df_weather = pd.read_csv(DATA_PATH + 'weather.csv')
df_epidemic = pd.read_csv(DATA_PATH + 'epidemic.csv')
df_hour.head()
| time | flow_1 | flow_2 | flow_3 | flow_4 | flow_5 | flow_6 | flow_7 | flow_8 | flow_9 | ... | flow_12 | flow_13 | flow_14 | flow_15 | flow_16 | flow_17 | flow_18 | flow_19 | flow_20 | train or test | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2022-01-01 01:00:00 | 29.7 | 14.6 | 54.7 | 40.1 | 3.0 | 49.7 | 10.9 | 1.1 | 5.0 | ... | 2.914 | 1.7 | 3.2 | 1.3 | 3.5 | 6.8 | NaN | 1.806 | 1.4 | train |
| 1 | 2022-01-01 02:00:00 | 21.9 | 9.0 | 38.0 | 27.7 | 2.4 | 30.2 | 6.4 | 0.4 | 2.6 | ... | 1.108 | 1.3 | 2.2 | 0.8 | 2.3 | 4.5 | NaN | 3.847 | 0.8 | train |
| 2 | 2022-01-01 03:00:00 | 16.9 | 4.5 | 28.9 | 22.9 | 1.3 | 19.7 | 3.8 | 0.5 | 1.4 | ... | 0.772 | 0.6 | 1.5 | 0.6 | 1.1 | 2.4 | NaN | NaN | 0.5 | train |
| 3 | 2022-01-01 04:00:00 | 14.3 | 3.2 | 25.5 | 20.0 | 1.5 | 15.4 | 2.7 | 0.4 | 1.2 | ... | 0.414 | 0.2 | 1.2 | 0.7 | 0.8 | 1.8 | NaN | NaN | 0.2 | train |
| 4 | 2022-01-01 05:00:00 | 14.9 | 3.5 | 26.4 | 20.6 | 1.2 | 17.5 | 2.2 | 0.5 | 1.2 | ... | 0.279 | 0.8 | 1.1 | 0.4 | 0.9 | 1.9 | NaN | NaN | 0.3 | train |
5 rows × 22 columns
df_hour.tail()
| time | flow_1 | flow_2 | flow_3 | flow_4 | flow_5 | flow_6 | flow_7 | flow_8 | flow_9 | ... | flow_12 | flow_13 | flow_14 | flow_15 | flow_16 | flow_17 | flow_18 | flow_19 | flow_20 | train or test | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5731 | 2022-08-27 20:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | test4 |
| 5732 | 2022-08-27 21:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | test4 |
| 5733 | 2022-08-27 22:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | test4 |
| 5734 | 2022-08-27 23:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | test4 |
| 5735 | 2022-08-28 00:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | test4 |
5 rows × 22 columns
df_hour.describe()
| flow_1 | flow_2 | flow_3 | flow_4 | flow_5 | flow_6 | flow_7 | flow_8 | flow_9 | flow_10 | flow_11 | flow_12 | flow_13 | flow_14 | flow_15 | flow_16 | flow_17 | flow_18 | flow_19 | flow_20 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 4980.000000 | 5056.00000 | 5039.000000 | 5039.00000 | 4979.000000 | 5039.000000 | 4982.000000 | 4959.000000 | 5061.000000 | 4084.000000 | 4924.000000 | 4096.000000 | 4973.000000 | 4866.000000 | 4957.000000 | 4965.000000 | 4954.000000 | 4272.000000 | 4088.000000 | 5061.000000 |
| mean | 44.415944 | 20.26337 | 74.641338 | 47.05892 | 5.578490 | 85.778468 | 15.434424 | 2.317302 | 6.997629 | 3.476107 | 5.881519 | 4.201093 | 3.149065 | 3.150164 | 2.163244 | 5.289406 | 9.285204 | 7.915218 | 3.736578 | 2.548390 |
| std | 57.289309 | 12.21846 | 41.722874 | 29.22040 | 7.380787 | 55.072447 | 12.820762 | 2.345089 | 4.476901 | 5.086824 | 6.947821 | 8.208345 | 3.051486 | 3.394400 | 2.292557 | 5.729534 | 9.825580 | 9.928315 | 5.317441 | 1.552966 |
| min | 1.000000 | 1.80000 | 0.000000 | -0.10000 | 0.000000 | 0.100000 | 1.200000 | -32.300000 | 0.500000 | 0.056000 | -61.500000 | -0.013000 | -32.000000 | -30.300000 | -27.500000 | -68.800000 | -121.400000 | -0.013000 | -0.086000 | 0.000000 |
| 25% | 28.400000 | 11.60000 | 55.400000 | 25.80000 | 3.000000 | 54.400000 | 7.300000 | 1.100000 | 3.500000 | 1.346000 | 2.800000 | 1.776000 | 1.800000 | 1.400000 | 1.100000 | 2.600000 | 4.600000 | 3.648000 | 1.597500 | 1.500000 |
| 50% | 43.500000 | 19.60000 | 74.100000 | 47.60000 | 5.200000 | 86.300000 | 14.050000 | 2.100000 | 6.500000 | 2.684000 | 5.400000 | 3.188000 | 2.900000 | 2.700000 | 1.900000 | 4.800000 | 8.600000 | 6.440000 | 2.805000 | 2.500000 |
| 75% | 55.600000 | 26.90000 | 92.400000 | 63.20000 | 7.600000 | 113.150000 | 21.200000 | 3.200000 | 9.700000 | 4.169250 | 7.600000 | 5.008000 | 4.100000 | 4.100000 | 2.900000 | 7.100000 | 12.600000 | 9.512000 | 4.480000 | 3.400000 |
| max | 3797.400000 | 160.60000 | 2048.600000 | 1308.20000 | 475.300000 | 2458.500000 | 414.300000 | 62.600000 | 26.000000 | 172.339000 | 183.000000 | 376.938000 | 91.600000 | 88.900000 | 61.900000 | 152.700000 | 265.700000 | 364.062000 | 172.748000 | 12.200000 |
figure=plt.figure(figsize=(16,3))ax1=plt.subplot(141)
plt.plot(df_hour['flow_1'])
ax2=plt.subplot(142)
plt.plot(df_hour['flow_2'])
ax3=plt.subplot(143)
plt.plot(df_hour['flow_3'])
ax4=plt.subplot(144)
plt.plot(df_hour['flow_4'])plt.show()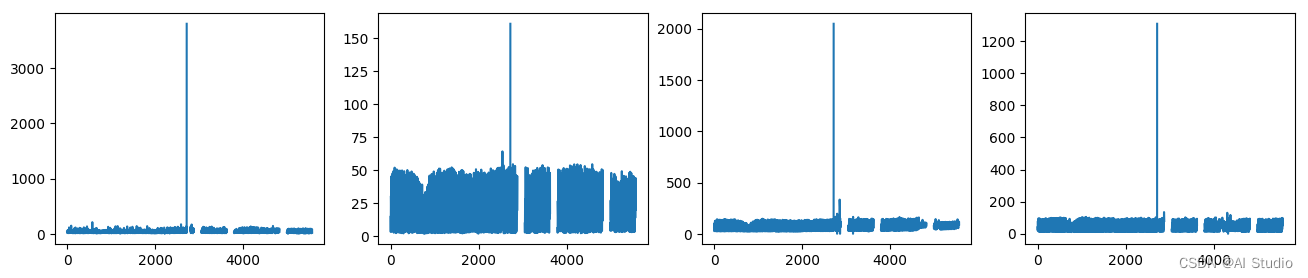
df_test
| time | flow_1 | flow_2 | flow_3 | flow_4 | flow_5 | flow_6 | flow_7 | flow_8 | flow_9 | ... | flow_12 | flow_13 | flow_14 | flow_15 | flow_16 | flow_17 | flow_18 | flow_19 | flow_20 | train or test | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2022-05-01 01:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | test1 |
| 1 | 2022-05-01 02:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | test1 |
| 2 | 2022-05-01 03:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | test1 |
| 3 | 2022-05-01 04:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | test1 |
| 4 | 2022-05-01 05:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | test1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 667 | 2022-08-27 20:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | test4 |
| 668 | 2022-08-27 21:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | test4 |
| 669 | 2022-08-27 22:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | test4 |
| 670 | 2022-08-27 23:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | test4 |
| 671 | 2022-08-28 00:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | test4 |
672 rows × 22 columns
df_test.groupby('train or test')['time'].count()
train or test
test1 168
test2 168
test3 168
test4 168
Name: time, dtype: int64
SEQ_LEN = 168
# 参考开源项目https://github.com/lhrgo/Competition-code/blob/main/baseline.ipynb
test_list1 = df_test.groupby('train or test')['time'].first().reset_index()
test_list1 = test_list1['time'].values.tolist()
test_list2 = df_test.groupby('train or test')['time'].last().reset_index()
test_list2 = test_list2['time'].values.tolist()
test_list1.extend(test_list2)
test_list1.sort()
test_list1
['2022-05-01 01:00:00','2022-05-08 00:00:00','2022-06-01 01:00:00','2022-06-08 00:00:00','2022-07-21 01:00:00','2022-07-28 00:00:00','2022-08-21 01:00:00','2022-08-28 00:00:00']
从测试数据(df_test)能够看到,这次的预测任务是以 小时 为单位的,作为基线,为了简化分析,这次训练数据同样只采用 小时 数据(df_hour)。
如果对比【赛事基线】“深水云脑”水质净化厂工艺控制-曝气量预测Baseline之DL这个任务,会发现两者最大的区别,一个是预测时间序列的伴生控制量(“水质净化厂工艺控制-曝气量”的 column),而一个是预测时间序列本身(“居民小区二次供水需求预测”的 row)。
此外,赛题更特殊的一点是,整个时间序列被分为四个大段,而每个预测时间段只能使用此段时间之前的数据进行预测。
引用赛题官网的解释:

规则举例:
- 可使用训练集1预测测试集1。
- 可使用训练集1、2和3来预测测试集3。
- 可以通过半监督学习,用训练集1、测试集1、训练集2来预测测试集2。
- 禁止使用训练集4来预测测试集1、2、3。
具体分析数据:
- 共有
5736条记录(以小时计)。 - 其中
672条测试集,共分为四段,每一段为7天168条数据:- 2022-05-01 01:00:00 ~ 2022-05-08 00:00:00
- 2022-06-01 01:00:00 ~ 2022-06-08 00:00:00
- 2022-07-21 01:00:00 ~ 2022-07-28 00:00:00
- 2022-08-21 01:00:00 ~ 2022-08-28 00:00:00
- 数据特征为
mermaid flowchat_1 ~ flow_20,共20个,同时也是需要预测的字段。 - 记录中
train or test用来区分训练集与测试集。 - 这是一个时间序列的数值回归问题。
- 数据具有
NaN值、小于零、异常大,等异常数值。 - 另外比赛还提供了以天计、以分钟计、天气、疫情等数据,后续可以用来构建特征。
2. 建模分析
目前已有的baseline基本都是用 lightgbm,这里尝试用 LSTM、Transformer来解决这个时间序列问题。
建模之前先要构造数据,这里上一个图,看看如何构造适合 LSTM、Transformer的数据结构:
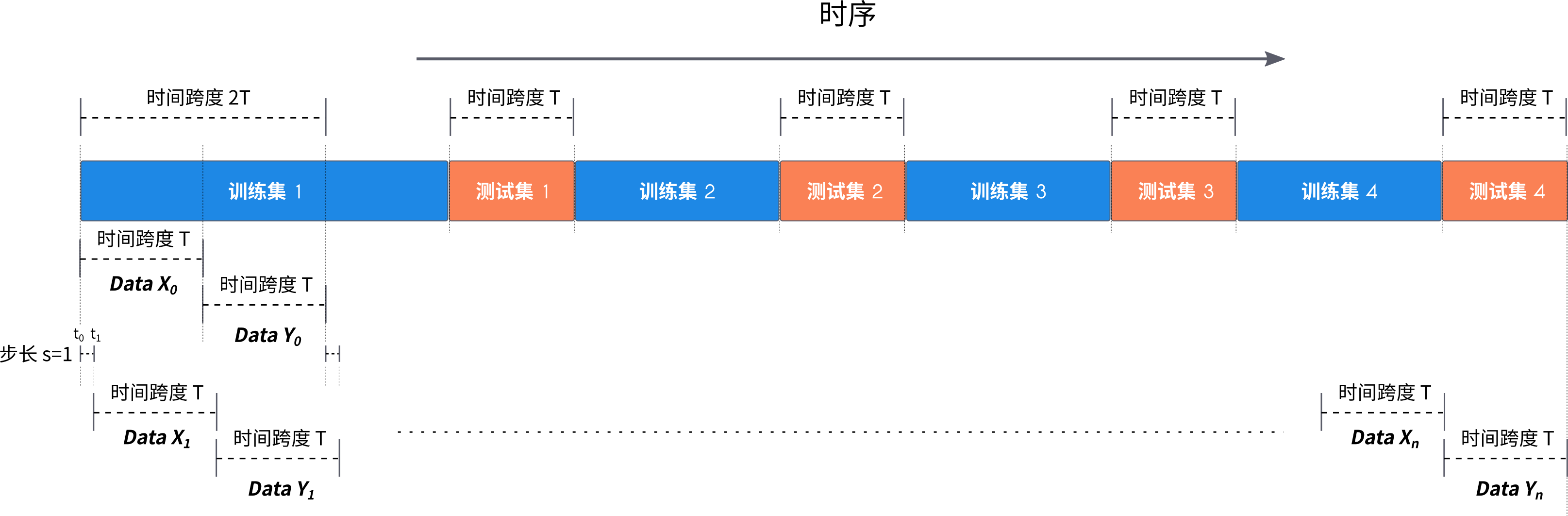
这里以测试集的长度 T = 168 T=168 T=168 为每条构造数据的时间跨度,则,以每 T T T 长度的数据为 X X X,以紧邻的长度为 T T T 的数据为 Y Y Y,以步长 s = 1 小 时 s=1小时 s=1小时 滚动生成。
其中 X X X 的每个时间点 t t t 包括 m m m 个特征值,如 mermaid flowchat_1、flow_2...,以及构造的 day、hour...等特征。
其中 Y Y Y 的每个时间点 t t t 包括 20 20 20 个预测值,分别对应 mermaid flowchat_1 ~ flow_20。
这样构造完数据之后,再根据4个测试集的时间点,从序列中摘出对应的训练数据即可。
而最终的测试数据,其实只有 4 条,也就是对应的4个测试时间点前 T T T 的那一条数据。
构造好数据了,对应的模型结构如下图所示:
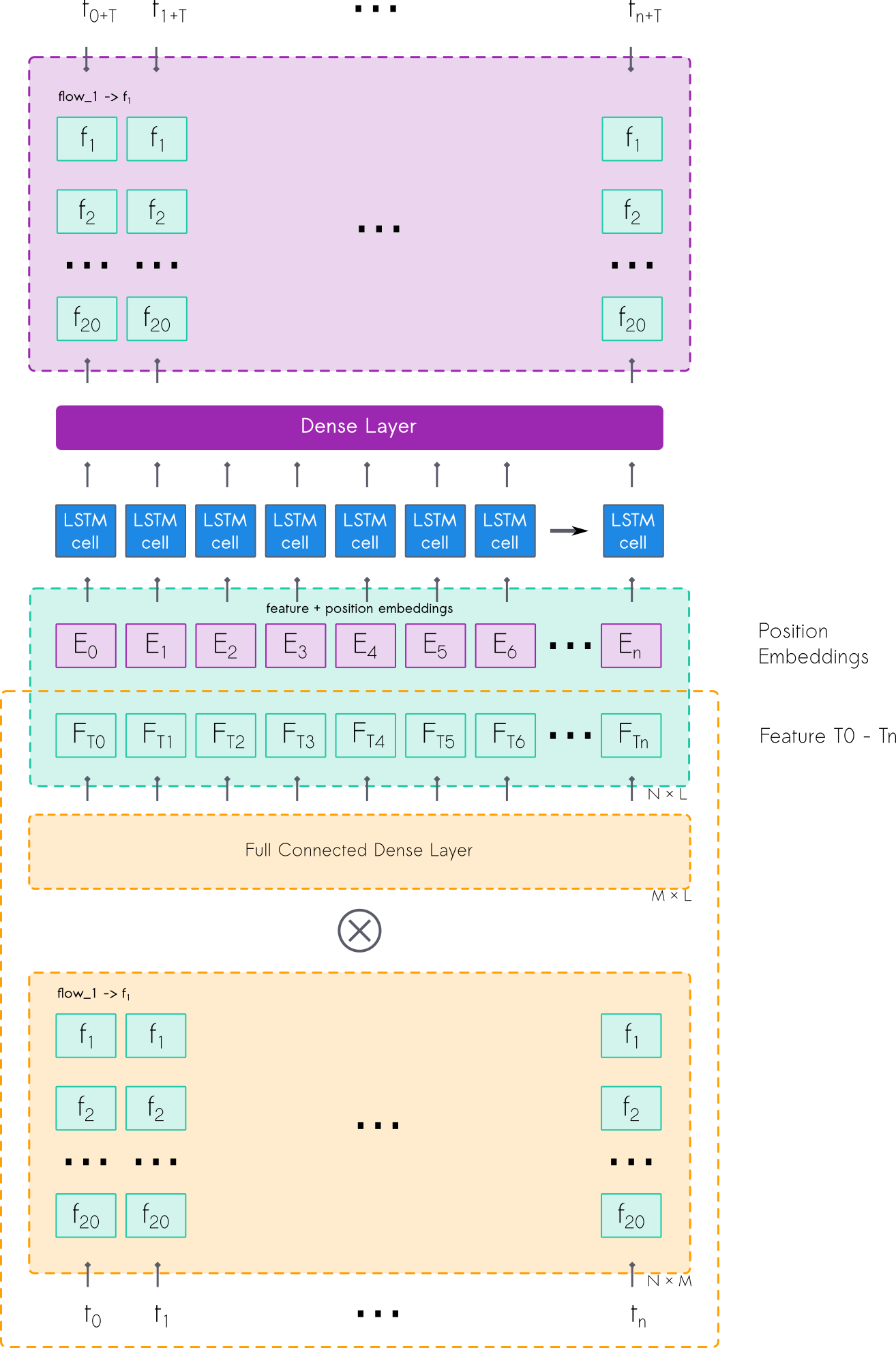
从上面的数据构造与模型结构可以看到,对比 lightgbm如果要解决此问题,需要构造模型数量为:
4 ∗ 20 ∗ k = 80 ∗ k 4 * 20 * k = 80 * k 4∗20∗k=80∗k
这里的 k k k 是 k fold的数量,也就是说至少需要 80 个模型!(以目前公布的baseline来举例。如果将 mermaid flowchat_n也做为特征的话,则可以大大减少模型数量。)
需要预测多少次数值呢?
4 ∗ 168 ∗ 20 ∗ k = 13440 ∗ k 4 * 168 * 20 * k = 13440 * k 4∗168∗20∗k=13440∗k
而我们这里使用的 LSTM、Transformer来做,共需要模型:
4 ∗ k 4 * k 4∗k
每个测试时间段只需要一个模型,需要做测试集预测 4次,只有 4个 X X X 数据需要预测!
OK,这里并不是说哪种方法更好,方法的好坏还是要用最终的成绩来说,这里只是提供一个更简洁有意思的方案而已 ~~~
数据构造与模型结构都介绍完了,具体的实现过程看下面的代码吧~
基线代码
COLUMNS_Y = ['flow_{}'.format(i) for i in range(1, 21)]
COLUMNS_X = COLUMNS_Y + ['day', 'hour', 'dayofweek']
COLUMNS_X, COLUMNS_Y
(['flow_1','flow_2','flow_3','flow_4','flow_5','flow_6','flow_7','flow_8','flow_9','flow_10','flow_11','flow_12','flow_13','flow_14','flow_15','flow_16','flow_17','flow_18','flow_19','flow_20','day','hour','dayofweek'],['flow_1','flow_2','flow_3','flow_4','flow_5','flow_6','flow_7','flow_8','flow_9','flow_10','flow_11','flow_12','flow_13','flow_14','flow_15','flow_16','flow_17','flow_18','flow_19','flow_20'])
def add_time_feat(data):data['time'] = pd.to_datetime(data['time'])data['day'] = data['time'].dt.daydata['hour'] = data['time'].dt.hourdata['minute'] = data['time'].dt.minutedata['dayofweek'] = data['time'].dt.dayofweekreturn data.sort_values('time').reset_index(drop=True)def add_other_feat(data, columns):data['flow_sum'] = data[columns].sum()data['flow_median'] = data[columns].median()data['flow_mean'] = data[columns].mean()return datadf_hour = add_time_feat(df_hour)
df_hour.head()
| time | flow_1 | flow_2 | flow_3 | flow_4 | flow_5 | flow_6 | flow_7 | flow_8 | flow_9 | ... | flow_16 | flow_17 | flow_18 | flow_19 | flow_20 | train or test | day | hour | minute | dayofweek | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2022-01-01 01:00:00 | 29.7 | 14.6 | 54.7 | 40.1 | 3.0 | 49.7 | 10.9 | 1.1 | 5.0 | ... | 3.5 | 6.8 | NaN | 1.806 | 1.4 | train | 1 | 1 | 0 | 5 |
| 1 | 2022-01-01 02:00:00 | 21.9 | 9.0 | 38.0 | 27.7 | 2.4 | 30.2 | 6.4 | 0.4 | 2.6 | ... | 2.3 | 4.5 | NaN | 3.847 | 0.8 | train | 1 | 2 | 0 | 5 |
| 2 | 2022-01-01 03:00:00 | 16.9 | 4.5 | 28.9 | 22.9 | 1.3 | 19.7 | 3.8 | 0.5 | 1.4 | ... | 1.1 | 2.4 | NaN | NaN | 0.5 | train | 1 | 3 | 0 | 5 |
| 3 | 2022-01-01 04:00:00 | 14.3 | 3.2 | 25.5 | 20.0 | 1.5 | 15.4 | 2.7 | 0.4 | 1.2 | ... | 0.8 | 1.8 | NaN | NaN | 0.2 | train | 1 | 4 | 0 | 5 |
| 4 | 2022-01-01 05:00:00 | 14.9 | 3.5 | 26.4 | 20.6 | 1.2 | 17.5 | 2.2 | 0.5 | 1.2 | ... | 0.9 | 1.9 | NaN | NaN | 0.3 | train | 1 | 5 | 0 | 5 |
5 rows × 26 columns
class Trans:def __init__(self, data, name):self.min = max(0, np.percentile(data, 1))self.max = np.percentile(data, 99)self.base = self.max-self.mindef transform(self, data, scale=True):_data = np.clip(data, self.min, self.max)if not scale:return _datareturn (_data-self.min)/self.baseclass TransUtil:def __init__(self, data, exclude_cols=None):self.columns = data.columnsself.exclude_cols = exclude_colsself.trans = {}for c in self.columns:if data[c].dtype not in [int, float]:print('column "{}" not init trans...'.format(c))continueif exclude_cols is None or (exclude_cols is not None and c not in exclude_cols):print('init trans column...', c)self.trans[c] = Trans(data[c].fillna(method='backfill').fillna(method='ffill'), c)def transform(self, data, col_name, scale=True):if self.exclude_cols is not None and col_name in self.exclude_cols:return datafor t in self.trans:if t.startswith(col_name):return self.trans[t].transform(data, scale=scale)return data
trans_util = TransUtil(df_hour, exclude_cols=None) # 数据标准化
column "time" not init trans...
init trans column... flow_1
init trans column... flow_2
init trans column... flow_3
init trans column... flow_4
init trans column... flow_5
init trans column... flow_6
init trans column... flow_7
init trans column... flow_8
init trans column... flow_9
init trans column... flow_10
init trans column... flow_11
init trans column... flow_12
init trans column... flow_13
init trans column... flow_14
init trans column... flow_15
init trans column... flow_16
init trans column... flow_17
init trans column... flow_18
init trans column... flow_19
init trans column... flow_20
column "train or test" not init trans...
init trans column... day
init trans column... hour
init trans column... minute
init trans column... dayofweek
def generate_xy_pair(data, seq_len, trans_util, columns_x, columns_y):data_x = pd.DataFrame()for c in columns_x:data_x[c] = trans_util.transform(data[c].fillna(data[c].median()), c)data_y = pd.DataFrame()for c in columns_y:data_y[c] = trans_util.transform(data[c].fillna(data[c].median()), c, scale=False)data_x = data_x.valuesdata_y = data_y.valuesprint(data_x.shape, data_y.shape)d_x = []d_y = []for i in range(len(data_x)-seq_len*2+1):_x = data_x[i:i+seq_len]_y = data_y[i+seq_len:i+seq_len+seq_len]assert len(_x) == len(_y) == seq_len, (_x, _y, _x.shape, _y.shape, i, len(data_x))d_x.append(_x.T)d_y.append(_y.T)return np.asarray(d_x).transpose((0, 2, 1)), np.asarray(d_y).transpose((0, 2, 1))
data_x, data_y = generate_xy_pair(df_hour, seq_len=SEQ_LEN, trans_util=trans_util, columns_x=COLUMNS_X, columns_y=COLUMNS_Y)
(5736, 23) (5736, 20)
data_x.shape, data_y.shape
((5401, 168, 23), (5401, 168, 20))
data_x[0], data_y[0]
(array([[0.19510716, 0.2526096 , 0.26320132, ..., 0. , 0.04347826,0.83333333],[0.11625556, 0.13569937, 0.12541254, ..., 0. , 0.08695652,0.83333333],[0.06570966, 0.04175365, 0.05033003, ..., 0. , 0.13043478,0.83333333],...,[0.63687829, 0.98538622, 0.92739274, ..., 0.2 , 0.95652174,0.66666667],[0.92094622, 0.6993737 , 0.67986799, ..., 0.2 , 1. ,0.66666667],[0.26991508, 0.44050104, 0.38118812, ..., 0.23333333, 0. ,0.83333333]]),array([[ 23.6 , 12.2 , 40.6 , ..., 3.932, 1.15 , 1.4 ],[ 15.6 , 5. , 32.6 , ..., 1.575, 0.509, 0.3 ],[ 12.4 , 3.9 , 25.1 , ..., 1.042, 0.394, 0.3 ],...,[ 71.3 , 46.3 , 133.3 , ..., 14.968, 6.192, 4.8 ],[ 60.7 , 37. , 105.5 , ..., 12.944, 5.072, 4. ],[ 35. , 19.8 , 67.5 , ..., 8.908, 2.912, 2.4 ]]))
# 根据每段测试集将对应的训练数据/测试数据的idx提取出来
_train_idx_1 = df_hour[df_hour['time']<test_list1[0]].index.values.tolist()
_train_idx_2 = df_hour[(df_hour['time']>test_list1[1])&(df_hour['time']<test_list1[2])].index.values.tolist()
_train_idx_3 = df_hour[(df_hour['time']>test_list1[3])&(df_hour['time']<test_list1[4])].index.values.tolist()
_train_idx_4 = df_hour[(df_hour['time']>test_list1[5])&(df_hour['time']<test_list1[6])].index.values.tolist()# 每一段数据包括上一段时间
train_idx_1 = _train_idx_1[:-SEQ_LEN*2]
train_idx_2 = train_idx_1 + _train_idx_2[:-SEQ_LEN*2]
train_idx_3 = train_idx_2 + _train_idx_3[:-SEQ_LEN*2]
train_idx_4 = train_idx_3 + _train_idx_4[:-SEQ_LEN*2]test_idx_1 = _train_idx_1[-SEQ_LEN]
test_idx_2 = _train_idx_2[-SEQ_LEN]
test_idx_3 = _train_idx_3[-SEQ_LEN]
test_idx_4 = _train_idx_4[-SEQ_LEN]
len(_train_idx_1), len(_train_idx_2), len(_train_idx_3), len(_train_idx_4)
(2880, 576, 1032, 576)
len(train_idx_1), len(train_idx_2), len(train_idx_3), len(train_idx_4)
(2544, 2784, 3480, 3720)
test_idx_1, test_idx_2, test_idx_3, test_idx_4
(2712, 3456, 4656, 5400)
train_x_1 = data_x[train_idx_1]
train_y_1 = data_y[train_idx_1]
train_x_2 = data_x[train_idx_2]
train_y_2 = data_y[train_idx_2]
train_x_3 = data_x[train_idx_3]
train_y_3 = data_y[train_idx_3]
train_x_4 = data_x[train_idx_4]
train_y_4 = data_y[train_idx_4]test_x_1 = data_x[test_idx_1]
test_x_2 = data_x[test_idx_2]
test_x_3 = data_x[test_idx_3]
test_x_4 = data_x[test_idx_4]FEATURE_SIZE = train_x_1.shape[-1]
OUTPUT_SIZE = train_y_1.shape[-1]
train_x_1.shape, train_y_1.shape, test_x_1.shape
((2544, 168, 23), (2544, 168, 20), (168, 23))
import paddle
import paddle.nn as nn
import paddle.nn.functional as Fclass Tt(nn.Layer):def __init__(self,seq_len,feature_size,output_size,use_model='lstm',hidden_size=576,num_hidden_layers=6,num_attention_heads=6,intermediate_size=3072,hidden_act="gelu",hidden_dropout_prob=0.1,attention_probs_dropout_prob=0.1,max_position_embeddings=512,max_hour=25,max_min=61,max_dow=8,max_ts=1441):super(Tt, self).__init__()self.use_model = use_modelself.feature_size = feature_size# 如果有相应的时间embedding则可以使用self.th_embeddings = nn.Embedding(max_hour, hidden_size)self.tm_embeddings = nn.Embedding(max_min, hidden_size)self.td_embeddings = nn.Embedding(max_dow, hidden_size)self.tt_embeddings = nn.Embedding(max_ts, hidden_size)# 位置编码self.position_embeddings = nn.Embedding(max_position_embeddings, hidden_size)self.layer_norm = nn.LayerNorm(hidden_size)self.fc_inputs = nn.Linear(feature_size, hidden_size)encoder_layer = nn.TransformerEncoderLayer(hidden_size,num_attention_heads,intermediate_size,dropout=hidden_dropout_prob,activation=hidden_act,attn_dropout=attention_probs_dropout_prob,act_dropout=0)self.encoder = nn.TransformerEncoder(encoder_layer, num_hidden_layers)self.lstm = paddle.nn.LSTM(input_size=hidden_size, hidden_size=hidden_size, num_layers=2)self.fc_output_1 = nn.Linear(hidden_size, hidden_size)self.fc_output_2 = nn.Linear(hidden_size, hidden_size)self.fc_output_3 = nn.Linear(hidden_size, output_size)def forward(self,inputs,inputs_th=None,inputs_tm=None,inputs_td=None,inputs_tt=None,position_ids=None,attention_mask=None):if position_ids is None:ones = paddle.ones(inputs.shape[:2], dtype="int64")seq_length = paddle.cumsum(ones, axis=1)position_ids = seq_length - onesposition_ids.stop_gradient = Trueposition_embeddings = self.position_embeddings(position_ids)inputs = self.fc_inputs(inputs)inputs = nn.Tanh()(inputs)inputs = inputs + position_embeddings# 如果有相应的时间embedding则可以使用if inputs_th is not None:inputs += self.th_embeddings(inputs_th)if inputs_tm is not None:inputs += self.tm_embeddings(inputs_tm)if inputs_td is not None:inputs += self.td_embeddings(inputs_td)if inputs_tt is not None:inputs += self.tt_embeddings(inputs_tt)inputs = self.layer_norm(inputs)# 选择使用LSTM或者Transformerif self.use_model == 'lstm':encoder_outputs, (h, c) = self.lstm(inputs)elif self.use_model == 'transformer':if attention_mask is None:attention_mask = paddle.unsqueeze((paddle.zeros(inputs.shape[:2])).astype(self.fc_inputs.weight.dtype) * -1e4,axis=[1, 2])encoder_outputs = self.encoder(inputs,src_mask=attention_mask)output = self.fc_output_1(encoder_outputs)output = nn.ReLU()(output)output = self.fc_output_2(output)output = self.fc_output_3(output)return outputimport paddle
import paddle.nn.functional as F
from paddle.metric import Accuracy
from paddle.io import DataLoader, BatchSampler
from paddlenlp.datasets import MapDataset
from paddlenlp.data import DataCollatorWithPadding
from paddlenlp.data import Dict, Stack, Pad
def calc_score(y_true, y_pred):return 1/(1+msle(np.clip(np.reshape(y_true, -1), 0, None), np.clip(np.reshape(y_pred, -1), 0, None)))def eval_model(model, data_loader):model.eval()y_pred = []y_true = []for step, batch in enumerate(data_loader, start=1):data = batch['data'].astype('float32')label = batch['label'].astype('float32')# 计算模型输出output = model(inputs=data)y_pred.extend(output.numpy())y_true.extend(label.numpy())score = calc_score(y_true, y_pred)model.train()return scoredef make_data_loader(data_x, idx, batch_size, data_y=None, shuffle=False):data = [{'data': data_x[i], 'label': 0 if data_y is None else data_y[i]} for i in idx]ds = MapDataset(data)batch_sampler = BatchSampler(ds, batch_size=batch_size, shuffle=shuffle)return DataLoader(dataset=ds, batch_sampler=batch_sampler)EPOCHS = 30
BATCH_SIZE = 256
CKPT_DIR = 'work/output'
K_FOLD = 5
epoch_base = 0
step_eval = 5
step_log = 100def do_train(train_x, train_y, prefix):print('-'*20)print('training ...', prefix)print('train x:', np.shape(train_x), 'train y:', np.shape(train_y))paddle.seed(2022)for kfold, tv_idx in enumerate(KFold(n_splits=K_FOLD, shuffle=True, random_state=2022).split(train_x)):print('training fold...', kfold)train_idx, valid_idx = tv_idxmodel = Tt(seq_len=SEQ_LEN, feature_size=FEATURE_SIZE, output_size=OUTPUT_SIZE)train_data_loader = make_data_loader(train_x, train_idx, BATCH_SIZE, data_y=train_y, shuffle=True)valid_data_loader = make_data_loader(train_x, valid_idx, BATCH_SIZE, data_y=train_y, shuffle=False)optimizer = paddle.optimizer.AdamW(learning_rate=1e-4, parameters=model.parameters())criterion = paddle.nn.MSELoss()epochs = EPOCHS # 训练轮次save_dir = CKPT_DIR #训练过程中保存模型参数的文件夹if not os.path.exists(save_dir):os.makedirs(save_dir)global_step = 0 #迭代次数tic_train = time.time()model.train()best_score = 0for epoch in range(1+epoch_base, epochs+epoch_base+1):for step, batch in enumerate(train_data_loader, start=1):data = batch['data'].astype('float32')label = batch['label'].astype('float32')# 计算模型输出output = model(inputs=data)loss = criterion(output, label)# print(loss)# 打印损失函数值、准确率、计算速度global_step += 1if global_step % step_eval == 0:score = eval_model(model, valid_data_loader) if score > best_score:# print('saving best model...', score)_save_dir = os.path.join(save_dir, '{}_kfold_{}_best_model.pdparams'.format(prefix, kfold))paddle.save(model.state_dict(),_save_dir)best_score = scoreif global_step % step_log == 0:print('global step %d, epoch: %d, batch: %d, loss: %.5f, valid score: %.5f, speed: %.2f step/s'% (global_step, epoch, step, loss, score,10 / (time.time() - tic_train)))tic_train = time.time()# 反向梯度回传,更新参数loss.backward()optimizer.step()optimizer.clear_grad()def do_pred(test_x, prefix):print('-'*20)print('predict ...', prefix)print('predict x:', np.shape(test_x))# 预测test_data_loader = make_data_loader([test_x], [0], BATCH_SIZE, data_y=None, shuffle=False)sub_df = []save_dir = CKPT_DIRfor kfold in range(K_FOLD):print('predict kfold...', kfold)model = Tt(seq_len=SEQ_LEN, feature_size=FEATURE_SIZE, output_size=OUTPUT_SIZE)model.set_dict(paddle.load(os.path.join(save_dir, '{}_kfold_{}_best_model.pdparams'.format(prefix, kfold))))model.eval()y_pred = []for step, batch in enumerate(test_data_loader, start=1):data = batch['data'].astype('float32')label = batch['label'].astype('float32')# 计算模型输出output = model(inputs=data)y_pred.extend(output.numpy())sub_df.append(np.clip(y_pred, 0, None))return sub_df
# 依次训练每个测试集对应的模型
do_train(train_x_1, train_y_1, 'm1')
do_train(train_x_2, train_y_2, 'm2')
do_train(train_x_3, train_y_3, 'm3')
do_train(train_x_4, train_y_4, 'm4')
--------------------
training ... m1
train x: (2544, 168, 23) train y: (2544, 168, 20)
training fold... 0W0928 21:34:13.226250 365 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0928 21:34:13.229223 365 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.global step 100, epoch: 13, batch: 4, loss: 189.34042, valid score: 0.74267, speed: 0.67 step/s
global step 200, epoch: 25, batch: 8, loss: 26.75570, valid score: 0.94225, speed: 0.75 step/s
training fold... 1
global step 100, epoch: 13, batch: 4, loss: 179.81596, valid score: 0.75175, speed: 0.88 step/s
global step 200, epoch: 25, batch: 8, loss: 27.06740, valid score: 0.94496, speed: 0.75 step/s
training fold... 2
global step 100, epoch: 13, batch: 4, loss: 192.32230, valid score: 0.74129, speed: 0.91 step/s
global step 200, epoch: 25, batch: 8, loss: 27.35677, valid score: 0.94298, speed: 0.75 step/s
training fold... 3
global step 100, epoch: 13, batch: 4, loss: 176.71466, valid score: 0.75317, speed: 0.87 step/s
global step 200, epoch: 25, batch: 8, loss: 24.32207, valid score: 0.94430, speed: 0.75 step/s
training fold... 4
global step 100, epoch: 13, batch: 4, loss: 196.51141, valid score: 0.73796, speed: 0.88 step/s
global step 200, epoch: 25, batch: 8, loss: 27.48337, valid score: 0.94143, speed: 0.74 step/s
--------------------
training ... m2
train x: (2784, 168, 23) train y: (2784, 168, 20)
training fold... 0
global step 100, epoch: 12, batch: 1, loss: 192.12552, valid score: 0.74218, speed: 0.83 step/s
global step 200, epoch: 23, batch: 2, loss: 26.67301, valid score: 0.94218, speed: 0.73 step/s
training fold... 1
global step 100, epoch: 12, batch: 1, loss: 181.16043, valid score: 0.75225, speed: 0.85 step/s
global step 200, epoch: 23, batch: 2, loss: 26.28015, valid score: 0.94389, speed: 0.73 step/s
training fold... 2
global step 100, epoch: 12, batch: 1, loss: 194.71078, valid score: 0.74261, speed: 0.87 step/s
global step 200, epoch: 23, batch: 2, loss: 28.19350, valid score: 0.93948, speed: 0.72 step/s
training fold... 3
global step 100, epoch: 12, batch: 1, loss: 181.40471, valid score: 0.75267, speed: 0.86 step/s
global step 200, epoch: 23, batch: 2, loss: 27.63694, valid score: 0.94298, speed: 0.72 step/s
training fold... 4
global step 100, epoch: 12, batch: 1, loss: 194.80693, valid score: 0.73768, speed: 0.85 step/s
global step 200, epoch: 23, batch: 2, loss: 27.04206, valid score: 0.93785, speed: 0.73 step/s
--------------------
training ... m3
train x: (3480, 168, 23) train y: (3480, 168, 20)
training fold... 0
global step 100, epoch: 10, batch: 1, loss: 195.62051, valid score: 0.74132, speed: 0.80 step/s
global step 200, epoch: 19, batch: 2, loss: 29.17942, valid score: 0.93782, speed: 0.70 step/s
global step 300, epoch: 28, batch: 3, loss: 22.93004, valid score: 0.94732, speed: 0.90 step/s
training fold... 1
global step 100, epoch: 10, batch: 1, loss: 191.73341, valid score: 0.74899, speed: 0.85 step/s
global step 200, epoch: 19, batch: 2, loss: 28.48909, valid score: 0.94111, speed: 0.70 step/s
global step 300, epoch: 28, batch: 3, loss: 24.10351, valid score: 0.94549, speed: 0.83 step/s
training fold... 2
global step 100, epoch: 10, batch: 1, loss: 200.53751, valid score: 0.74166, speed: 0.84 step/s
global step 200, epoch: 19, batch: 2, loss: 32.34964, valid score: 0.93378, speed: 0.70 step/s
global step 300, epoch: 28, batch: 3, loss: 22.18238, valid score: 0.94529, speed: 0.86 step/s
training fold... 3
global step 100, epoch: 10, batch: 1, loss: 190.54114, valid score: 0.74929, speed: 0.83 step/s
global step 200, epoch: 19, batch: 2, loss: 29.43060, valid score: 0.93647, speed: 0.70 step/s
global step 300, epoch: 28, batch: 3, loss: 22.63792, valid score: 0.94633, speed: 0.84 step/s
training fold... 4
global step 100, epoch: 10, batch: 1, loss: 199.86848, valid score: 0.73911, speed: 0.82 step/s
global step 200, epoch: 19, batch: 2, loss: 30.84038, valid score: 0.93401, speed: 0.71 step/s
global step 300, epoch: 28, batch: 3, loss: 25.37951, valid score: 0.94664, speed: 0.82 step/s
--------------------
training ... m4
train x: (3720, 168, 23) train y: (3720, 168, 20)
training fold... 0
global step 100, epoch: 9, batch: 4, loss: 196.55203, valid score: 0.74267, speed: 0.81 step/s
global step 200, epoch: 17, batch: 8, loss: 31.35485, valid score: 0.93497, speed: 0.70 step/s
global step 300, epoch: 25, batch: 12, loss: 24.27215, valid score: 0.94545, speed: 0.80 step/s
training fold... 1
global step 100, epoch: 9, batch: 4, loss: 191.64560, valid score: 0.74758, speed: 0.83 step/s
global step 200, epoch: 17, batch: 8, loss: 30.92274, valid score: 0.93813, speed: 0.69 step/s
global step 300, epoch: 25, batch: 12, loss: 24.90816, valid score: 0.94470, speed: 0.90 step/s
training fold... 2
global step 100, epoch: 9, batch: 4, loss: 197.55722, valid score: 0.74337, speed: 0.84 step/s
global step 200, epoch: 17, batch: 8, loss: 31.99613, valid score: 0.93345, speed: 0.70 step/s
global step 300, epoch: 25, batch: 12, loss: 24.23726, valid score: 0.94481, speed: 0.77 step/s
training fold... 3
global step 100, epoch: 9, batch: 4, loss: 186.58867, valid score: 0.74806, speed: 0.79 step/s
global step 200, epoch: 17, batch: 8, loss: 29.82816, valid score: 0.93393, speed: 0.71 step/s
global step 300, epoch: 25, batch: 12, loss: 25.93081, valid score: 0.94440, speed: 0.84 step/s
training fold... 4
global step 100, epoch: 9, batch: 4, loss: 198.73732, valid score: 0.74012, speed: 0.81 step/s
global step 200, epoch: 17, batch: 8, loss: 31.71860, valid score: 0.92987, speed: 0.70 step/s
global step 300, epoch: 25, batch: 12, loss: 24.98176, valid score: 0.94471, speed: 0.83 step/s
# 以此预测数据
pred_1 = do_pred(test_x_1, 'm1')
pred_2 = do_pred(test_x_2, 'm2')
pred_3 = do_pred(test_x_3, 'm3')
pred_4 = do_pred(test_x_4, 'm4')
--------------------
predict ... m1
predict x: (168, 23)
predict kfold... 0
predict kfold... 1
predict kfold... 2
predict kfold... 3
predict kfold... 4
--------------------
predict ... m2
predict x: (168, 23)
predict kfold... 0
predict kfold... 1
predict kfold... 2
predict kfold... 3
predict kfold... 4
--------------------
predict ... m3
predict x: (168, 23)
predict kfold... 0
predict kfold... 1
predict kfold... 2
predict kfold... 3
predict kfold... 4
--------------------
predict ... m4
predict x: (168, 23)
predict kfold... 0
predict kfold... 1
predict kfold... 2
predict kfold... 3
predict kfold... 4
np.shape(pred_1), np.shape(pred_2), np.shape(pred_3), np.shape(pred_4)
((5, 1, 168, 20), (5, 1, 168, 20), (5, 1, 168, 20), (5, 1, 168, 20))
result = np.vstack((np.mean(pred_1, axis=0).squeeze(),np.mean(pred_2, axis=0).squeeze(),np.mean(pred_3, axis=0).squeeze(),np.mean(pred_4, axis=0).squeeze()))result[result<0] = 0
result = pd.concat([df_sub['time'], pd.DataFrame(result)], axis=1)
result.columns = df_sub.columns
result.to_csv('work/result/result_0929_1.csv', index=False, encoding='utf-8')
result
| time | flow_1 | flow_2 | flow_3 | flow_4 | flow_5 | flow_6 | flow_7 | flow_8 | flow_9 | ... | flow_11 | flow_12 | flow_13 | flow_14 | flow_15 | flow_16 | flow_17 | flow_18 | flow_19 | flow_20 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2022-05-01 01:00:00 | 16.348139 | 9.175403 | 26.263027 | 18.721674 | 2.373459 | 34.867836 | 7.246955 | 1.099344 | 3.313838 | ... | 2.670277 | 1.593728 | 1.153737 | 1.514585 | 0.968933 | 2.303546 | 4.133782 | 3.025845 | 1.402229 | 0.971339 |
| 1 | 2022-05-01 02:00:00 | 14.053380 | 5.963273 | 22.574793 | 14.666861 | 1.698181 | 26.584387 | 4.510387 | 0.770431 | 2.162849 | ... | 1.651368 | 1.184766 | 0.758920 | 0.877874 | 0.657236 | 1.438656 | 2.712646 | 2.277040 | 1.038984 | 0.728588 |
| 2 | 2022-05-01 03:00:00 | 13.625262 | 4.783116 | 21.758783 | 13.371454 | 1.489840 | 23.987709 | 3.504470 | 0.691582 | 1.788223 | ... | 1.244085 | 1.079558 | 0.646173 | 0.639825 | 0.559387 | 1.123157 | 2.216079 | 2.084101 | 0.939994 | 0.660505 |
| 3 | 2022-05-01 04:00:00 | 14.628029 | 4.955190 | 23.244579 | 14.171738 | 1.586371 | 25.465771 | 3.612296 | 0.745096 | 1.890892 | ... | 1.251172 | 1.165931 | 0.689106 | 0.649021 | 0.590614 | 1.148339 | 2.308054 | 2.225137 | 1.003049 | 0.707679 |
| 4 | 2022-05-01 05:00:00 | 17.273390 | 6.258585 | 27.386667 | 17.034664 | 1.970203 | 30.908686 | 4.632016 | 0.918758 | 2.382508 | ... | 1.598803 | 1.420646 | 0.858239 | 0.846729 | 0.735128 | 1.465289 | 2.902800 | 2.669768 | 1.221339 | 0.861373 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 667 | 2022-08-27 20:00:00 | 66.468307 | 35.385902 | 107.975449 | 71.752434 | 9.243578 | 138.513672 | 27.510956 | 4.069358 | 12.509884 | ... | 10.101812 | 6.173742 | 4.863465 | 5.871843 | 3.652327 | 9.148096 | 15.805559 | 11.880441 | 5.471368 | 3.962896 |
| 668 | 2022-08-27 21:00:00 | 76.719620 | 42.754463 | 123.607361 | 82.205627 | 11.031697 | 161.878479 | 33.868797 | 4.929608 | 15.284616 | ... | 12.454828 | 7.429977 | 5.723071 | 7.472642 | 4.452061 | 11.248039 | 19.293243 | 14.126564 | 6.571022 | 4.579916 |
| 669 | 2022-08-27 22:00:00 | 77.418564 | 43.689445 | 125.960526 | 85.884750 | 11.060221 | 161.800690 | 34.703972 | 4.948043 | 15.392654 | ... | 12.925382 | 7.647626 | 5.894122 | 7.730872 | 4.586210 | 11.649742 | 19.840784 | 14.605158 | 6.642810 | 4.627126 |
| 670 | 2022-08-27 23:00:00 | 60.882912 | 33.174492 | 103.905174 | 76.558876 | 7.978610 | 120.090683 | 25.825283 | 3.456902 | 10.831713 | ... | 10.026538 | 5.887389 | 4.801626 | 5.655329 | 3.596707 | 9.055432 | 15.106519 | 11.837584 | 4.873275 | 3.687579 |
| 671 | 2022-08-28 00:00:00 | 39.200665 | 19.236624 | 71.477028 | 52.819008 | 4.418453 | 70.673370 | 14.343943 | 1.840522 | 5.580392 | ... | 5.988278 | 3.586876 | 3.149178 | 3.089876 | 2.144467 | 5.405599 | 8.690753 | 7.562930 | 2.856358 | 2.337228 |
672 rows × 21 columns
结果分析
由于paddle的结果会有一点波动,这里仅做简单对比分析:
| model | epoch | score |
|---|---|---|
| LSTM | 30 | 0.441 |
| LSTM | 50 | 0.442 |
关于模型的一些分析与说明,在另一篇文章【赛事基线】“深水云脑”水质净化厂工艺控制-曝气量预测Baseline之DL中已经聊了聊,这里不再赘述。
这里简单补充几点:
- 如果使用
Transformer结构,可以再加一个Decoder的步骤,类似NLP中的生成模型,可以使模型更灵活,这里只写了Encoder部分。 - 如果希望提升成绩,可以尝试构造更多的数据特征,比如时间差分、非线性变换等。
- 深度学习模型的最大优势在于结构灵活,从上面的模型就可以看出来,这里可以一次性输出 168 ∗ 20 = 3360 168 * 20 = 3360 168∗20=3360 个数值,并一次性反向传播完成。在NLP领域,多任务学习被证实具有很好的性能,在传统回归问题中也可以进行尝试。
最后,复杂的模型不一定就有更好的成绩,有同学上传的baseline中用简单的均值策略就可以获得远好于此次模型的成绩,值得深思 ~~~ 哈哈哈 [捂脸]
OK,希望这篇文章能对大家有所帮助,有问题互相探讨~
附录:
其他开源项目:
【赛事基线】“深水云脑”水质净化厂工艺控制-曝气量预测Baseline之DL
【实验分享】“字”还是“词”?这是个问题!
【比赛分享】讯飞-基于论文摘要的文本分类与查询性问答第4名(并列第3)的思考
我正在参加AI Studio 4周年活动,登录平台完成探索任务就有机会获得Mac、Iphone、网盘会员、GPU算力等奖品,点击链接为我助力,你也可以获奖哦
链接:https://aistudio.baidu.com/aistudio/4th?invitation=1&sharedUserId=942478&sharedUserName=er_zhong0
此文章为搬运
原项目链接
这篇关于【赛事基线】“深水云脑”居民小区二次供水需求预测Baseline之DL的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





