本文主要是介绍爬虫入门到精通_实战篇7(Requests+正则表达式爬取猫眼电影)_ 抓取单页内容,正则表达式分析,保存至文件,开启循环及多线程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 目标
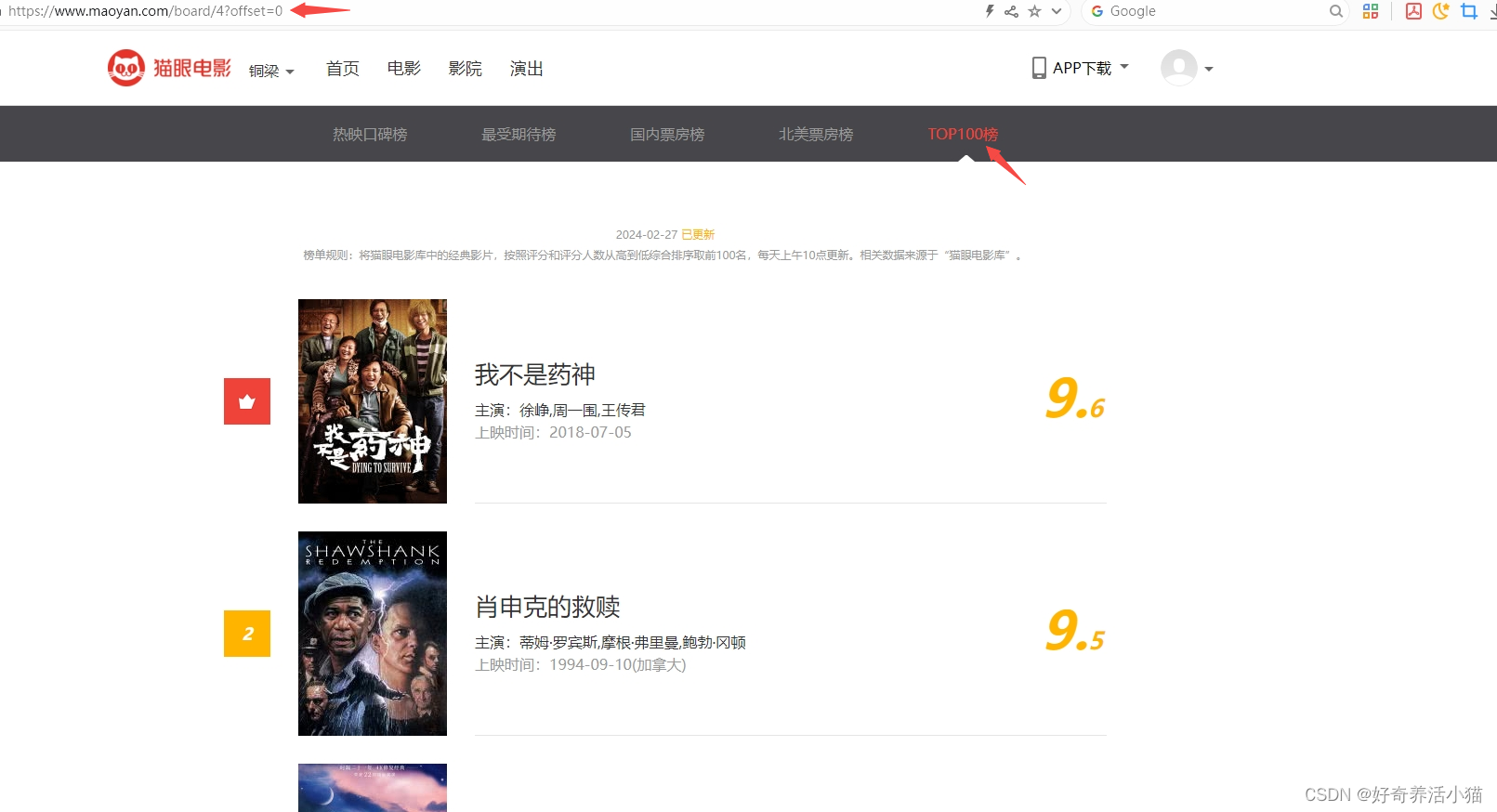
猫眼榜单TOP100:https://www.maoyan.com/board
2 流程框架
- 抓取单页内容:利用requests请求目标站点,得到单个网页HTML代码,返回结果。
- 正则表达式分析:根据HTML代码分析得到电影名称,主演,上映时间,评分,图片链接等信息。
- 保存至文件:通过文件的形式将结果保存,每一步电影一个结果一行json字符串。
- 开启循环及多线程:对多页内容遍历,开启多线程提高抓取速度。
3 实战
1.抓取单页内容
import requests
from requests.exceptions import RequestException# 提取单页内容,用try,except防止挂机
def get_one_page(url):try:response = requests.get(url)if response.status_code == 200:#如果状态码为200,请求成功return response.textreturn response.status_code #请求失败,返回状态码结果except RequestException:return Nonedef main():url = "https://www.maoyan.com/board/4"html = get_one_page(url)print(html)
if __name__ == '__main__':main()
url路径:下图可知:第一页offset = 0,第二页offset=10

respnse查看内容:Network 选项->筛选Doc
返回:
如果报了403状态码:
请求是加上headers
headers = {'User-Agent':'Mozilla/5.0(Macintosh;Intel Mac OS X 10_11_4)AppleWebKit/537.36(KHTML,like Gecko)Chrome/52.0.2743.116 Safari/537.36'}
#提取单页内容,用try,except方便找bug
def get_one_page(url):try:response = requests.get(url, headers=headers)#传入headers参数if response.status_code == 200:return response.textreturn response.status_codeexcept RequestException:return None
2 正则表达式分析
根据HTML代码分析得到电影名称,主演,上映时间,评分,图片链接等信息。
HTML的结构:
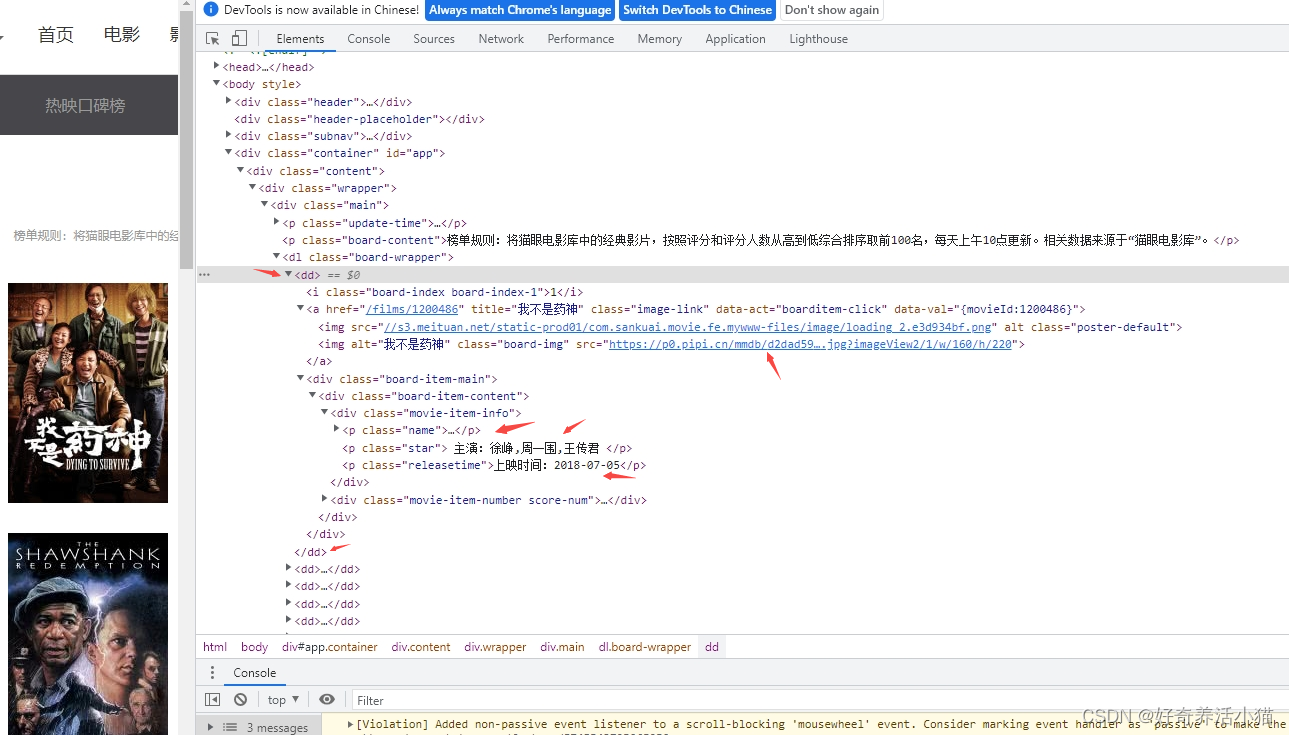
红色箭头是需要提取的信息,正则表达式如下:
def parse_one_page(html):# 生成一个正则表达式对象pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a' # 此处换行+ '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)items = re.findall(pattern,html)# items是一个list,提取信息成字典形式for item in items:yield { # 构造一个字典'index': item[0],'image':item[1],'title':item[2],'actor':item[3].strip()[3:],#做切片,去掉“主演:“这3个字符'time':item[4].strip()[5:],'score':item[5]+item[6] #将小数点前后的数字拼接起来}return itemsdef main():url = "https://www.maoyan.com/board/4"html = get_one_page(url)for item in parse_one_page(html):print(item)
效果如下:

3 保存至文件
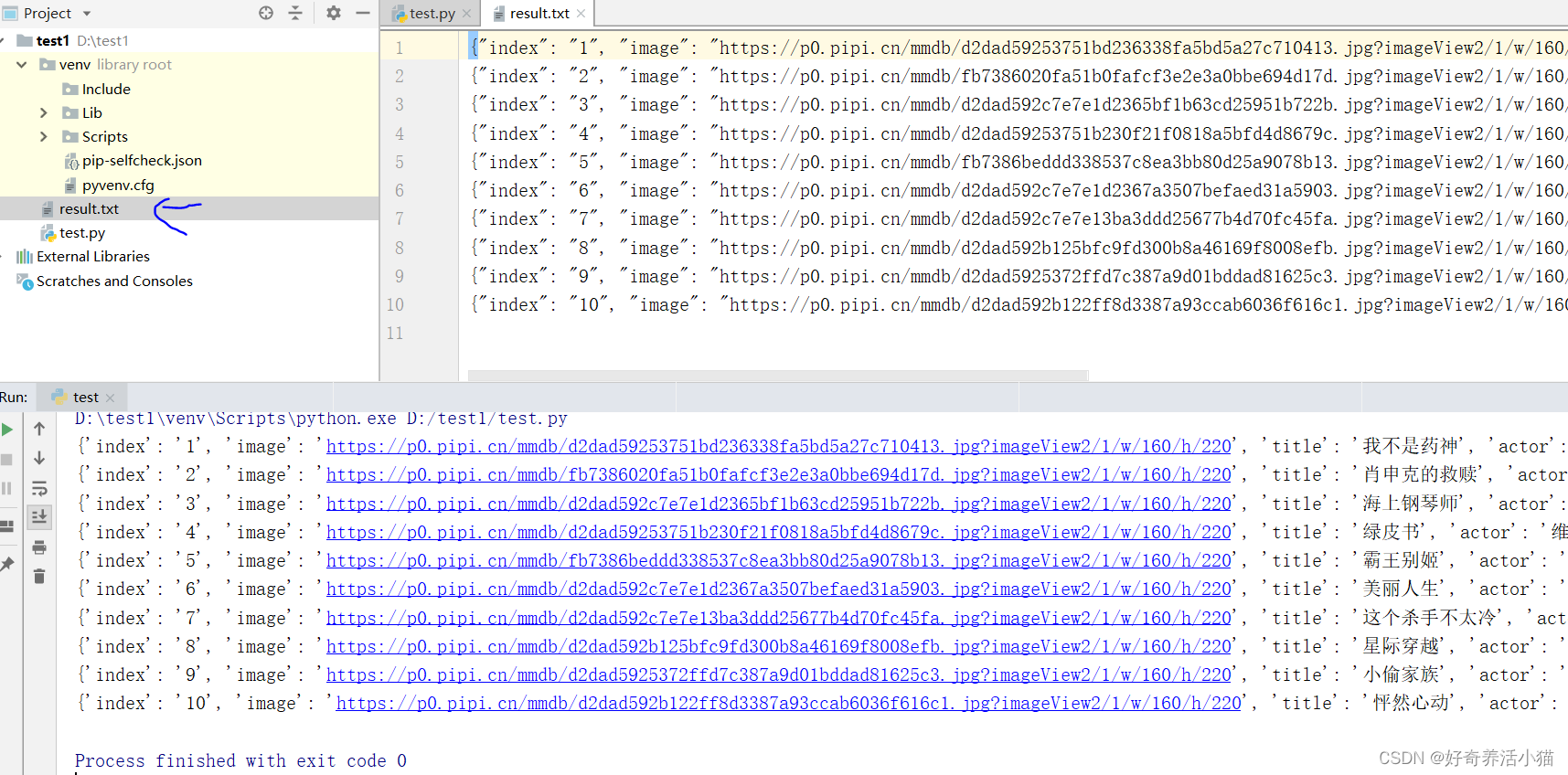
def write_to_file(content):with open('result.txt','a',encoding='utf-8') as f:f.write(json.dumps(content, ensure_ascii=False) + '\n') # 不允许写入ascii码f.close()def main():url = "https://www.maoyan.com/board/4"html = get_one_page(url)for item in parse_one_page(html):print(item)write_to_file(item)
效果如下:
4 开启循环及多线程
方式一:
def main(offset):url = "https://www.maoyan.com/board/4?offset="+str(offset)html = get_one_page(url)for item in parse_one_page(html):print(item)write_to_file(item)if __name__ == '__main__':for i in range(10):main(i*10)
方式二:
from multiprocessing import Pool
if __name__ == '__main__':pool = Pool() #创建一个进程池pool.map(main,[i*10 for i in range(10)])
4 整体代码
import requests
from requests.exceptions import RequestException
import re
import json
from multiprocessing import Poolheaders = {'User-Agent': 'Mozilla/5.0(Macintosh;Intel Mac OS X 10_11_4)AppleWebKit/537.36(KHTML,like Gecko)Chrome/52.0.2743.116 Safari/537.36'}# 提取单页内容,用try,except方便找bug
def get_one_page(url):try:response = requests.get(url, headers=headers) # 传入headers参数if response.status_code == 200:return response.textreturn response.status_codeexcept RequestException: # 捕获这个类型的异常return Nonedef parse_one_page(html): # 定义一个函数用来解析html代码# 生成一个正则表达式对象pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a' # 此处换行+ '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)items = re.findall(pattern, html)# items是一个list,其中的每个内容都是一个元组# 将杂乱的信息提取并格式化,变成一个字典形式for item in items:yield { # 构造一个字典'index': item[0],# 'image': item[1],'title': item[2],'actor': item[3].strip()[3:], # 做一个切片,去掉“主演:”这3个字符'time': item[4].strip()[5:], # 做一个切片,去掉“上映时间:”这5个字符'score': item[5] + item[6] # 将小数点前后的数字拼接起来}def write_to_file(content):with open('result.txt', 'a', encoding='utf-8') as f:# a表示模式是“追加”;采用utf-8编码可以正常写入汉字f.write(json.dumps(content, ensure_ascii=False) + '\n') # 不允许写入ascii码# content是一个字典,我们需要转换成字符串形式,注意导入json库f.close()def main(offset):url = 'https://maoyan.com/board/4?offset=' + str(offset) # 把offset参数以字符串形式添加到url中html = get_one_page(url)for item in parse_one_page(html): # item是一个生成器print(item)write_to_file(item)if __name__ == '__main__':pool = Pool() # 创建一个进程池pool.map(main, [i * 10 for i in range(10)]) # map方法创建进程(不同参数的main),并放到进程池中

这篇关于爬虫入门到精通_实战篇7(Requests+正则表达式爬取猫眼电影)_ 抓取单页内容,正则表达式分析,保存至文件,开启循环及多线程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





