本文主要是介绍Lightweight Attention Module for Deep Learning on Classification and Segmentation of 3D Point Clouds,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Lightweight Attention Module for Deep Learning on Classification and Segmentation of 3D Point Clouds
Yunhao Cui, Yi An, Member, IEEE, Wei Sun, Huosheng Hu, Senior Member, IEEE, and Xueguan Song
年份:2020
期刊:IEEE TRANSACTIONS ON INSTRUMENTATION AND MEASUREMENT
IF:3.658
1、创新
1、将深度可分离卷积引入到PointNet等网络中,实现了轻量级+高效,Lightweight Module 。
2、为了弥补深度可分离卷积导致的精度下降的问题,引入了channel attention模块,提高了精度,Attention Module。
3、将两个模块(LM+AM)结合起来,使轻量级和高精度之间达到了平衡。
2、具体体现
1、深度可分离卷积
深度可分离卷积可以参考:这篇
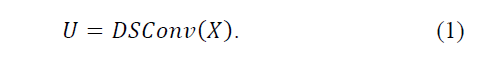
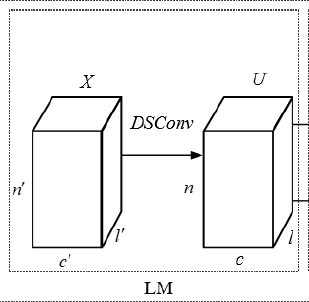
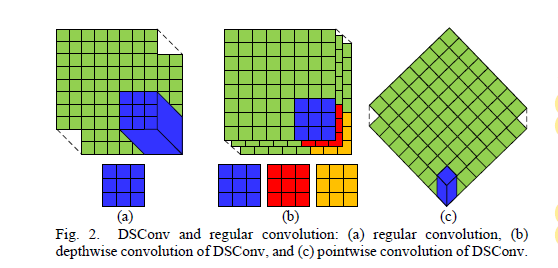
常规卷积的参数量:
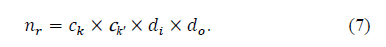
深度可分离卷积的参数量:
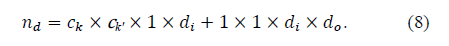
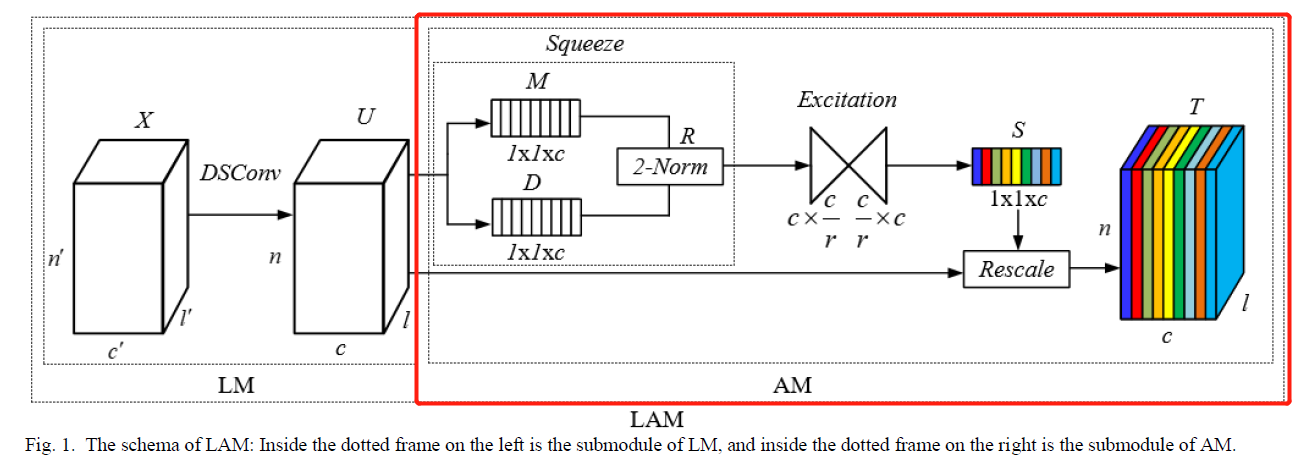
2、channel attention模块
M代表每一个通道上特征的均值:
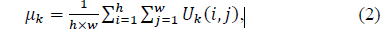
D代表每一个通道上特征的分布标准差:
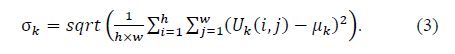
每一个通道上的"权重":
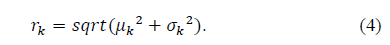
最终得到注意力权重:

根据权重更新通道的特征:

借助于PointNet的结构,将其中的mlp替换为本文提出的LAM:
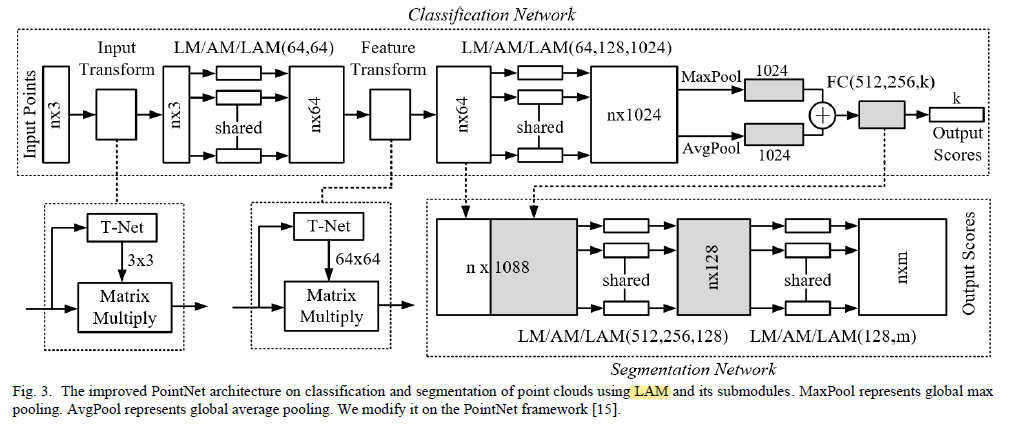
3、实验结果
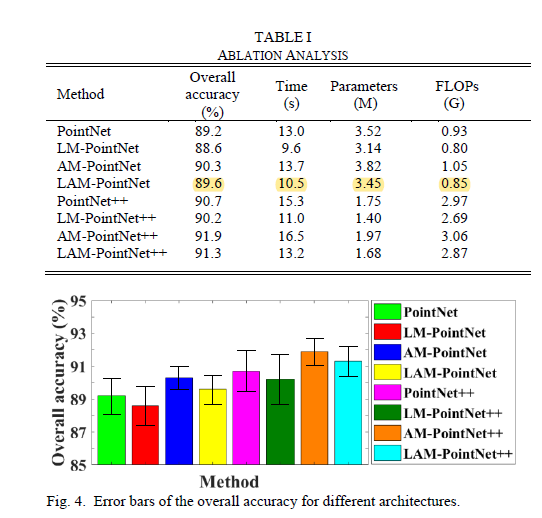
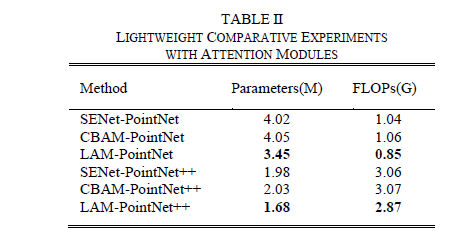
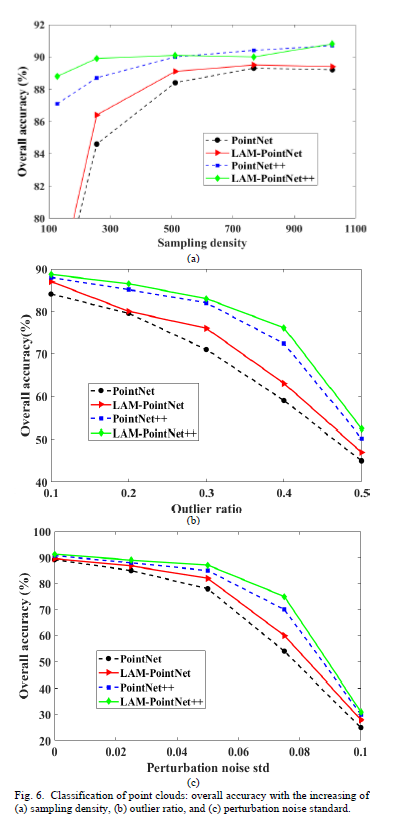
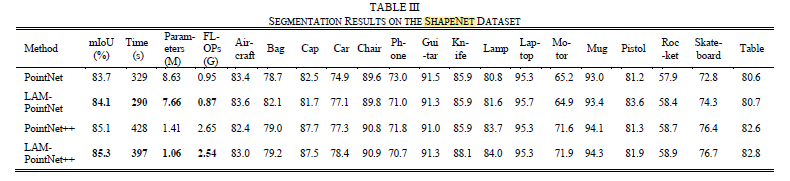


这篇关于Lightweight Attention Module for Deep Learning on Classification and Segmentation of 3D Point Clouds的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







