本文主要是介绍Stand-Alone Self-Attention in Vision Models,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转自微信公众号


谷歌研究和谷歌大脑团队提出针对视觉任务的独立自注意力(stand-alone self-attention)层,用它创建的纯注意力(fully attentional)模型,在ImageNet分类任务和COCO目标检测任务中都超越了用卷积的基准模型,而且用了更少的浮点运算和更少的参数量。LearnX对具体内容整理如下。
在开始之前先对几个新的概念做一些解释。
独立自注意力层
大家都知道自注意力是什么。这个独立自注意力的独立体现在哪里呢?之所以叫独立自注意力是因为,之前的注意力机制是和卷积结合起来作为卷积的扩展来用的,而独立自注意力不依赖卷积层单独作为一层。详细定义见下面。
纯注意力网络
全部用独立自注意力层构建的网络。
背景
卷积用的好好的,为什么提出注意力机制呢?这篇文章更过分,完全不想用卷积了,为什么?
卷积捕获长距离交互能力比较差,这是因为卷积的感受野大时缩放特性弱。此前,针对这个问题的处理方法就是用注意力机制。在卷积中运用的注意力机制主要有两种。一个是,基于通道的注意力机制Squeeze-and-Excite;一个是,基于空间的注意力机制。这些方法有个特点,就是用全局注意力层作为卷积的附加模块;还有一个限制,因为关注输入的所有位置,要求输入比较小,否则计算成本太大。这篇文章正是为了解决这些问题。
解决方法
这篇文章回答了一个问题。基于内容的交互(content-based interaction,暂且理解为注意力机制)能否成为视觉模型的主要模块,而不仅仅是作为卷积的扩展功能?答案是,能。
为了替换卷积,在这篇文章中提出了独立自注意力层和空间感知独立自注意力层。空间感知独立自注意力层在独立自注意力层上加了一些位置相关的信息,这个在后面详细解释。
然后,用空间感知独立自注意力层替换初始层卷积。用独立自注意力层替换其余卷积层。为什么对不同的卷积层区分对待?这个在后面详细解释。
结果
替换后的模型,也就是纯注意力模型在ImageNet分类任务和COCO目标检测任务中都超过了用卷积的基准模型,而且用了更少的浮点运算和更少的参数量。详细的实验结果在这里就不贴出来了,有兴趣的同学看论文吧。
到这里,论文的主要idea基本说完了。此外,文章中还做了一些对比实验。对比对卷积层和注意力层,对比不同感受野的注意力层,对比不同的位置嵌入方式等。
下面回答上文中提出的一些问题。
独立自注意力
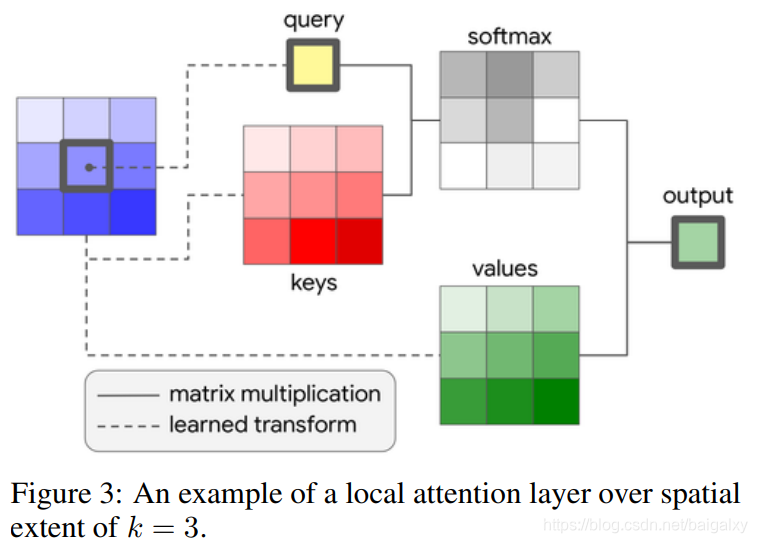
独立自注意力层定义了三个概念query,key, value。自注意力层的运算是局域的,所以不用限制输入的大小。自注意力层的参数个数与感受野的大小无关,卷积的参数个数与感受野的大小成平方关系;运算量的增长也比卷积的缓慢。图为自注意力的示意图。
自注意力的公式如下,
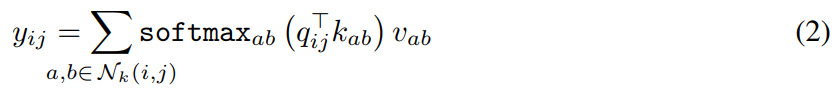
其中

其中![]() 为学习到的参数。
为学习到的参数。
但是,上面的公式(2)没有包含位置信息,所以对于一个query,其邻域的位置关系无法体现出来。为了解决这个问题,通过用嵌入向量表示相对位置,把位置信息巧妙的添加到了自注意力运算。有位置信息的注意力公式如下,
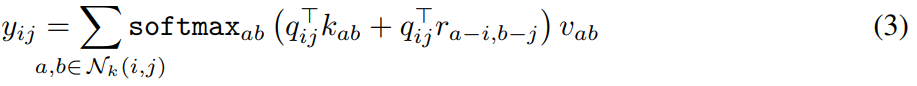
在这个式子里既包含了内容,又包含了位置。其中![]() 为位置嵌入。
为位置嵌入。
为什么对卷积层的初始层和其余层不同对待?
一句话的答案是卷积层的初始层和其余层在卷积网络中起着不同的作用。
在图像问题中卷积网络的初始层,也叫stem,它与其它层有比较大的区别。一般认为初始层的功能主要有两个方面。第一,学习局部特征,如边缘,用于后续的全局目标识别或检测。第二,由于输入图像通常比较大,初始层的任务还有下采样。如ResNet的初始层为stride为2的7x7卷积,以及stride为2的3x3 max pooling。初始层的输入为RGB图像,每个像素的信息单独拿出来并不是很重要,但是它们与周围的像素有很大的空间相关性。这种特征使得像自注意力一样的基于内容的机制很难学习到有效的特征,如边缘。总之,卷积网络的初始层与其他层有一些功能省的区别,而文中提出的标准自注意力机制无法满足初始层的要求。因此文中又提出了一个空间感知(spatially aware)自注意力层来解决标准的自注意力层无法包含空间信息的问题。
空间感知独立自注意力
空间感知自注意力层的定义如下,
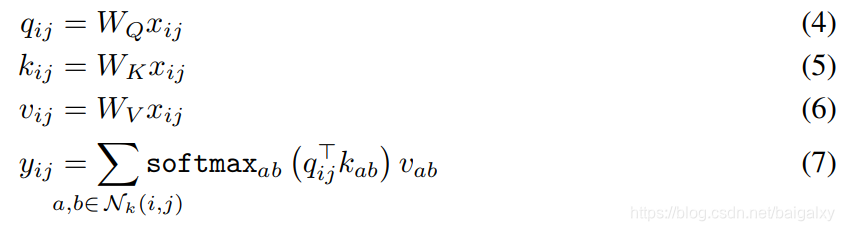
其形式和标准的自注意力层一样。只有![]() 的定义与标准的自注意力不同。定义如下,
的定义与标准的自注意力不同。定义如下,
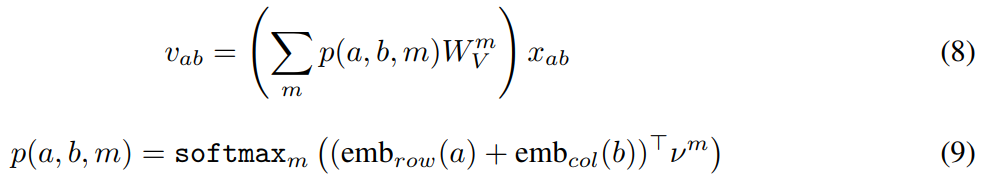
这个公式的意思就是在一个窗口中每个位置的![]() 都通过
都通过![]() 与不同的
与不同的![]() 相乘得到。其中
相乘得到。其中![]() 是多值矩阵的第m矩阵,
是多值矩阵的第m矩阵,![]() 是向量的第m元素,为标量,a和b是相对于窗口的行和列位置。
是向量的第m元素,为标量,a和b是相对于窗口的行和列位置。
如果喜欢,请关注公众号!

这篇关于Stand-Alone Self-Attention in Vision Models的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)


