本文主要是介绍【PaperReading】Stand-Alone Self-Attention in Vision Models,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文链接:https://arxiv.org/abs/1906.05909
代码:https://github.com/leaderj1001/Stand-Alone-Self-Attention
启示
1. 提出了一种代替空间卷积的操作——self attention,可以有效结合self attention操作和原来的空间卷积操作,在网络的初期使用原来的空间卷积操作,而后面和各个head使用self attention,从而提高性能,减少计算量。
2. 目前网络的整体架构还是采用的原来的,如果专门为self attention设计更加合适的网络结构或许还能进一步提升性能。
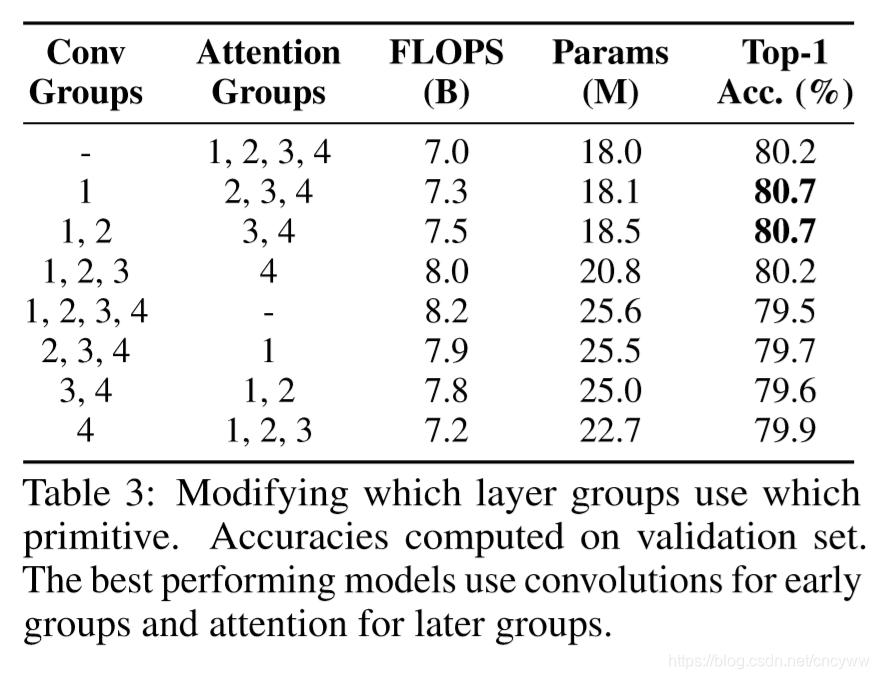
3. 在有关位置信息的一些模块中,相对位置信息> 绝对位置信息 > 没有位置信息
局限
1. 尽管基于attention操作的网络的训练效率和计算效率要比原来的要高,但是实际运行时的时间(wall-clock time.)要比原来的慢,作者说是对attention操作的优化不够好,缺少硬件加速。
2. attention的操作看起来比普通空间卷积要复杂,不太符合"大道至简"的思想。
下面是论文内容:
Abstract

主要的贡献是提出使用 “自注意力操作”代替一般的空间卷积操作,以弥补空间卷积无法有效捕捉长距离信息间的关系的不足,同时使用的计算量和参数量更少。
解决的问题
在分类、检测、分割等任务中,现在有很多工作引入 注意力机制(attention)来提升所提取特征对空间尺度上信息的获取能力,但大部分工作都是在网络的后期增添精心设置的注意力模块用以提取空间信息丰富的特征,然后再与之前的特征进行融合。如,基于通道的注意力机制Squeeze-and-Excite,还有基于空间的注意力机制No local CCNet等。这些方法有个特点,就是用全局注意力层作为卷积的附加模块,没有从卷积操作的局限性上进行根本的改进,另外还有一个限制,就是因为需要关注输入的所有位置,所以要求输入的featuremap的空间尺寸比较小,否则计算成本太大。
方法
这篇论文直接将网络中最基础的“空间卷积操作”(除了1x1卷积意外的卷积)替换为“自注意力操作”,而网络的大体结构不改变。
普通的3x3空间卷积操作:
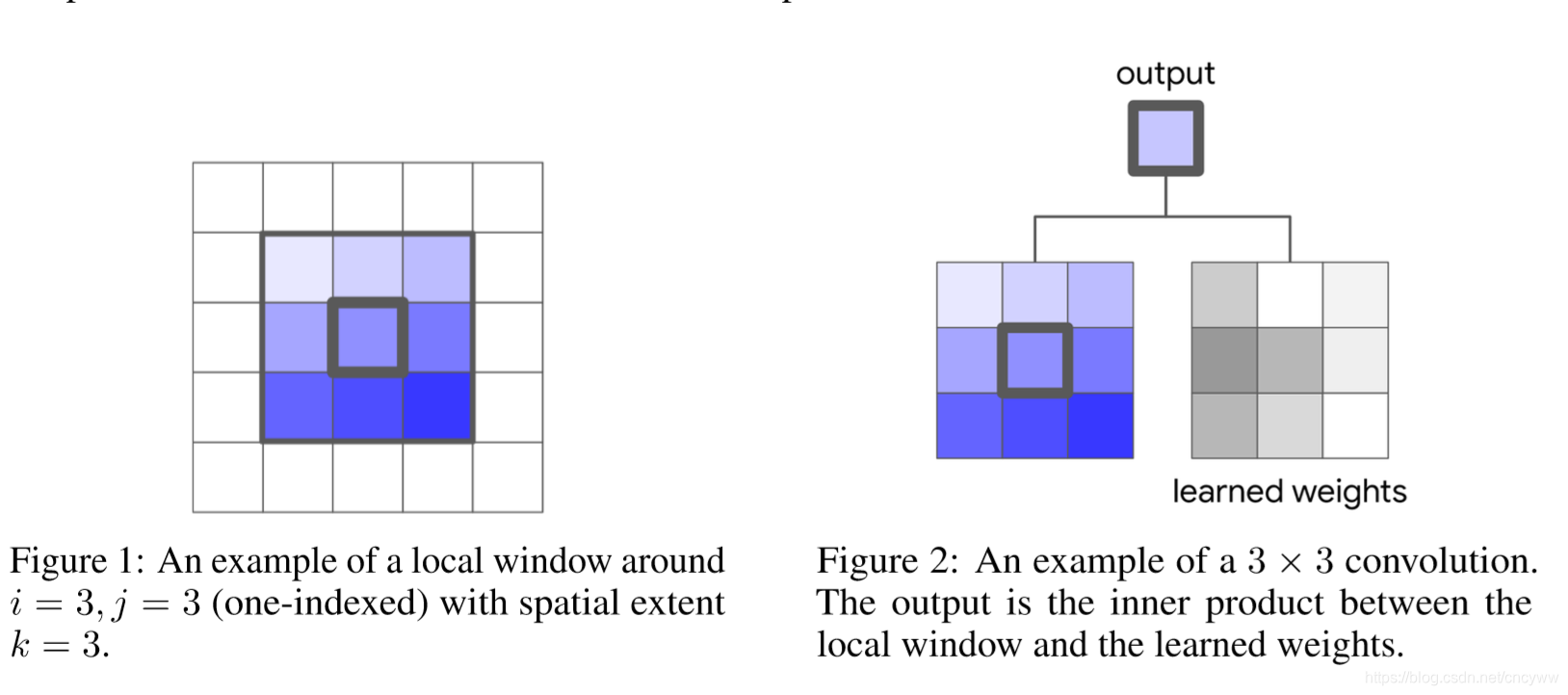

本文提出的自注意力(Self attention)操作:

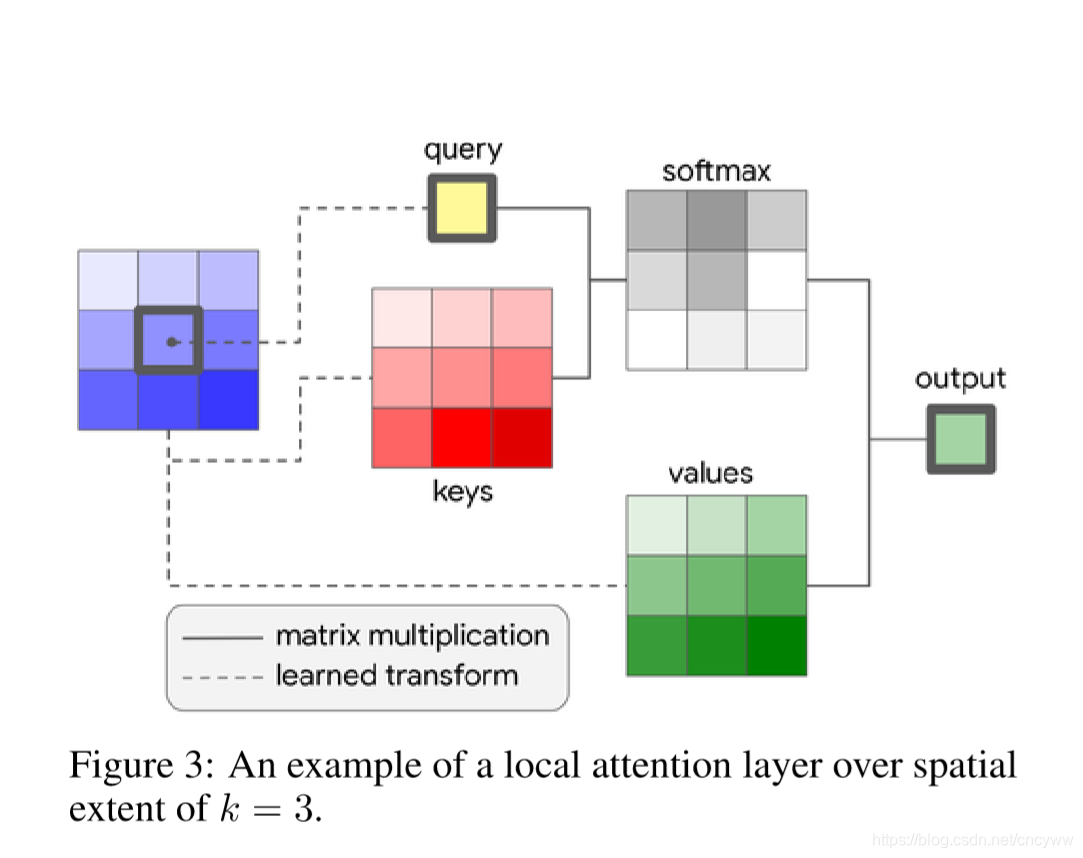

加入相对位置信息:
目前的self attention平等对待中心像素邻近的其他像素点,没有利用位置信息,因此文中进一步通过用嵌入向量来表示相对位置,把位置信息也添加到了自注意力操作中。
这里作者通过实验也说明了 相对位置信息> 绝对位置信息 > 没有位置信息

文中举例,若输入输出的feature map 的channel都是128,那么窗口为3x3的普通空间卷积的计算量和19x19的self attention差不错。
需要注意的是对于网络中的stem部分,也就是最开始的一部分卷积操作,self attention的性能不如普通卷积,这是因为最开始的部分网络需要提取像边缘之类的初始特征,而输入的特征通道数较少,content信息少,主要的是空间信息。所以又提出了个spatially aware 的attention 模块代替使用普通卷积的stem。

实验结果
ImageNet 分类结果:
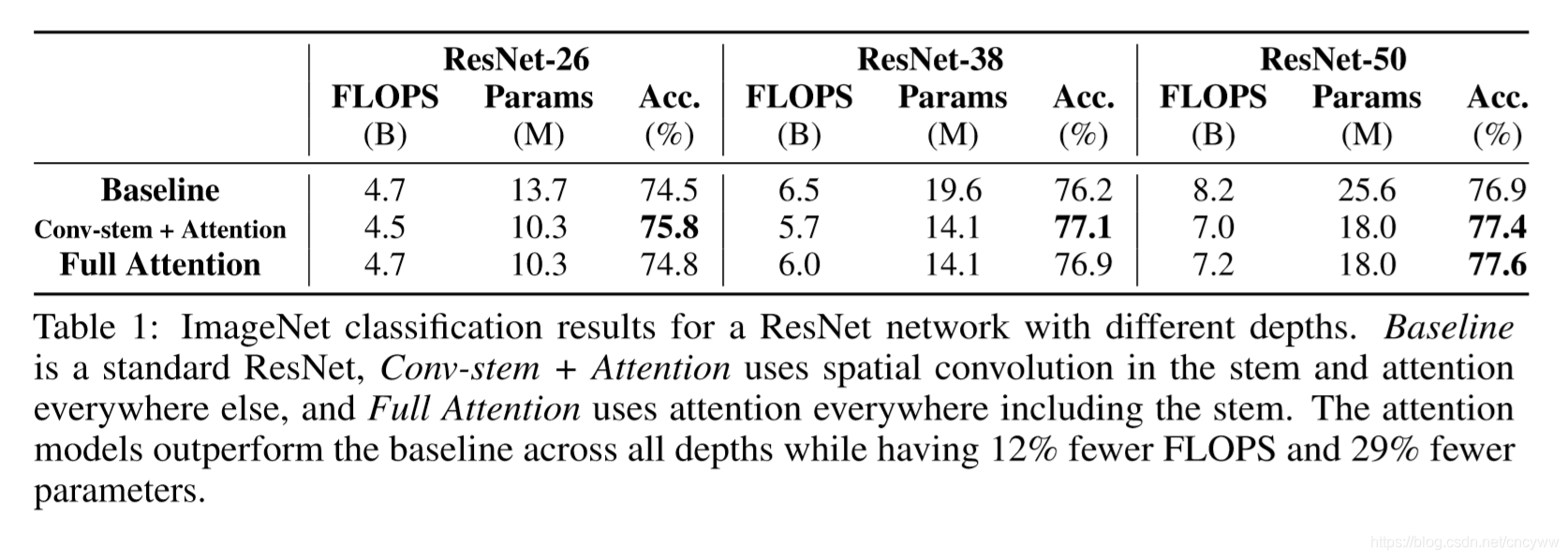
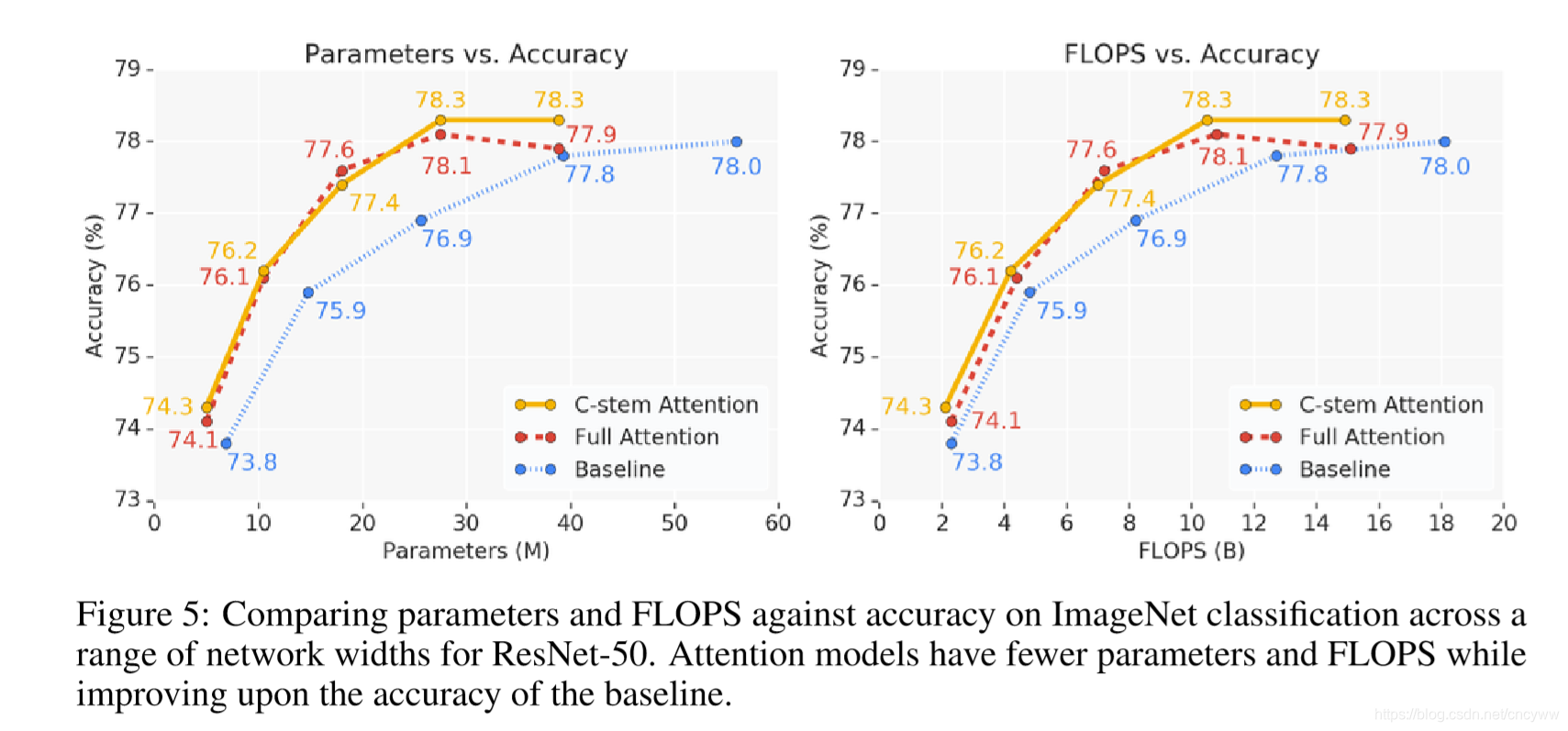
COCO 检测结果:
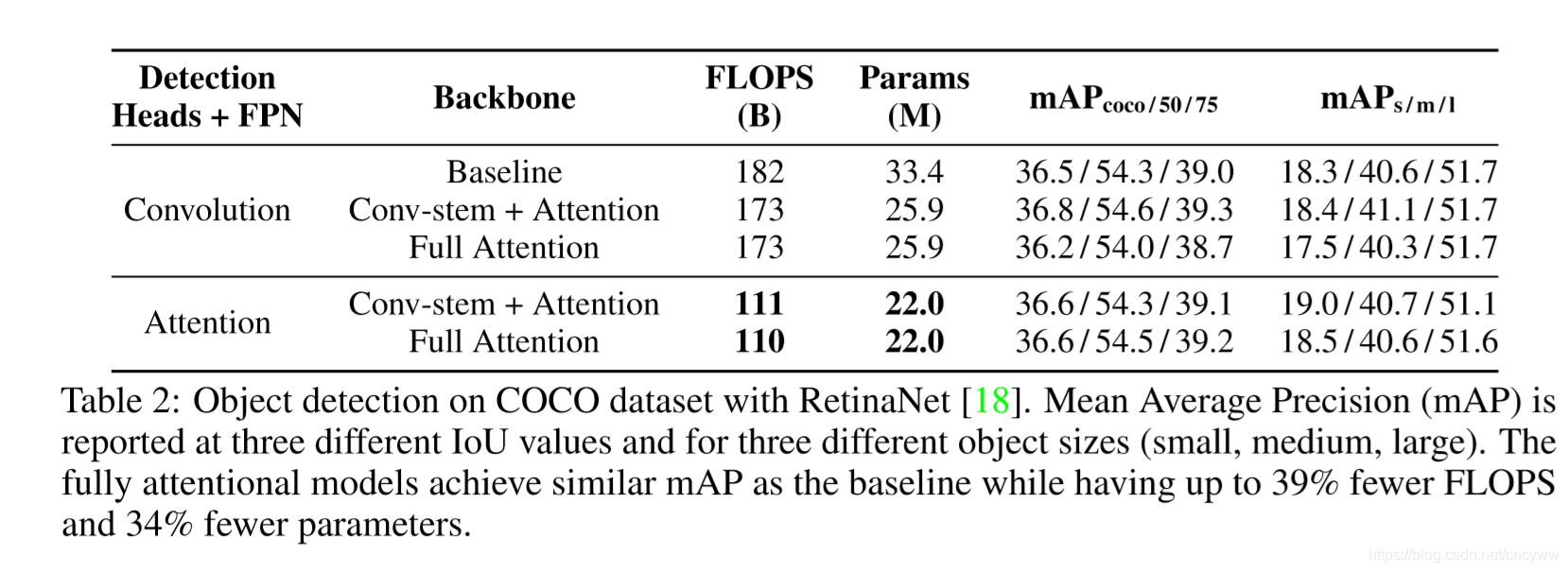
这篇关于【PaperReading】Stand-Alone Self-Attention in Vision Models的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)


