本文主要是介绍RAM-DSIR:眼底和前列腺图像泛化能力增强,免除不同的扫描仪、成像协议和操作者等多种因素差异,影响学习效果,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
RAM-DSIR:眼底和前列腺图像泛化能力增强,免除不同的扫描仪、成像协议和操作者等多种因素差异,影响学习效果
- 提出背景
- 总体架构
- 两种领域适应策略
- 数学构造
- 效果
提出背景
论文:https://arxiv.org/pdf/2208.03901.pdf
代码:https://github.com/zzzqzhou/RAM-DSIR
深度学习方法假设训练数据和测试数据共享相同的分布信息。
这一假设要求训练和测试数据来自同一分布,这是一个强假设。
众所周知,由于不同的扫描仪、成像协议和操作者等多种因素,医学图像的质量差异很大。
- 不同实验室、不同专业人员、不同批次染色剂、不同扫描仪、不同玻片原材料、不同组织对颜色的响应程度等因素而引起的颜色差异,影响学习效果
由于数据分布的变化,这一假设在真实临床环境中通常变得无效。
因此,直接在一组训练图像上训练的分割模型可能缺乏对来自另一家医院或医疗中心、遵循不同分布的测试图像的泛化能力。
总体架构
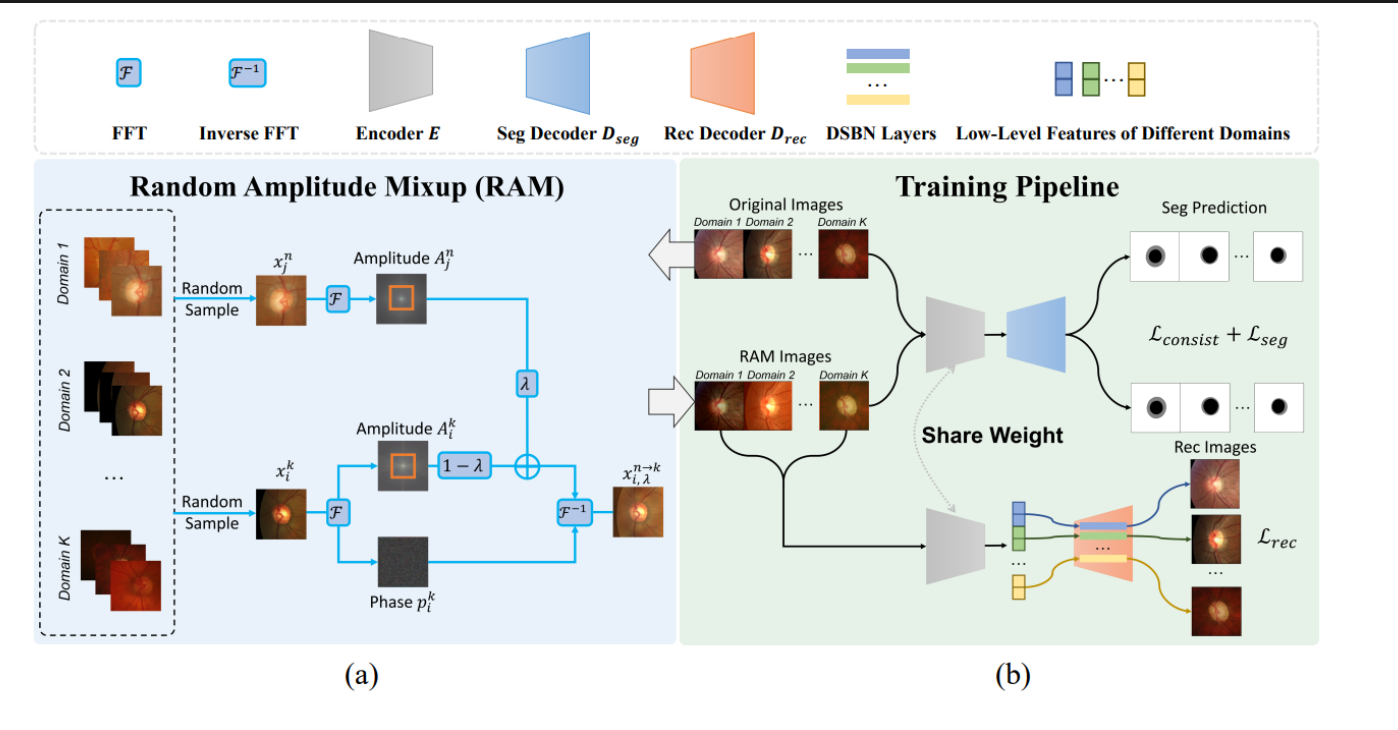
图是一个用于医学图像分割的深度学习方法的总体架构,包含了两个主要部分:
(a) 随机振幅混合(RAM)模块:
这部分展示了如何生成具有不同领域风格的新图像,同时保留原始的语义信息。
具体步骤如下:
- 从不同领域(Domain 1, Domain 2, …, Domain K)随机采样图像。
- 对这些图像应用傅立叶变换(FFT),提取出它们的振幅映射(Amplitude Maps)。
- 通过计算不同振幅映射的加权和(通过一个称为λ的权重),结合原始的相位信息,再应用逆傅立叶变换(Inverse FFT)来合成新的图像。
通过这种方式,新图像包含了来自多个源领域的低级频率信息,有助于模型学习更具泛化性的特征。
(b) 训练流程(Training Pipeline):
这部分描述了如何使用合成的图像来训练医学图像分割模型,整个流程包括:
- 使用RAM模块合成的图像来训练分割模型,这样做可以增加训练数据的多样性并提高模型的泛化能力。
- 分割模型(Seg Prediction)使用基本的分割损失(L_seg)和语义一致性损失(L_consist)。语义一致性损失确保合成图像和真实源域图像的预测结果在语义上保持一致。
- 为了进一步提高模型的泛化能力,引入了领域特定图像恢复(DSIR)解码器(Rec Decoder D_rec)来从合成图像中恢复原始源域图像的低级特征。
- 通过这样的训练,模型不仅学会了分割任务,还通过DSIR和RAM模块提高了对不同领域变化的鲁棒性。
整个架构的目的是减少模型对于特定医学图像领域的依赖,从而提高在不同设备、协议或医疗中心获取的图像上的表现。
使用如图所示的RAM和DSIR框架:
-
收集和处理不同设备的眼底图像:从各种眼底相机和扫描设备收集图像,并进行预处理。
-
应用RAM模块:对收集的眼底图像应用RAM模块,通过傅立叶变换提取振幅信息,并结合来自不同设备的图像的振幅,生成新的合成图像。
-
域特定图像恢复:使用DSIR解码器从合成图像中恢复出接近原始设备图像的低级特征。
-
训练分割模型:使用合成图像和原始图像训练分割模型,同时采用语义一致性损失和分割损失来确保模型能够在语义上正确地分割眼底结构。
-
评估和应用:在不同设备获取的眼底图像上评估模型的性能,并将其应用于实际的医学诊断中。
通过这种方法,即使是在不同设备上获取的眼底图像,模型也能够更好地泛化和适应,从而在实际的医疗环境中提供更准确的分割结果。
虽然这个特定的架构是为医学图像分割设计的,它的一些概念也可以应用于其他医学图像分析任务,包括糖尿病视网膜病变的分类。
关键在于方法的主要目的是增强模型对不同域的泛化能力,无论是分割还是分类。
两种领域适应策略
-
无监督领域适应 (UDA):
- 问题设定:利用来自一个或多个源域的有标签数据和目标域的无标签数据来训练分类器。
- 动机:使源域和目标域的分布对齐。
- 方法:
- 生成模型:缩小源域和目标域之间的像素级分布差距。
- 对抗训练:通过对抗性训练对齐源域和目标域的特征分布,以保持不同域中的语义特征一致。
- 输出空间对齐:缩小源域和目标域在输出空间级别的分布差距。
-
领域泛化 (DG):
- 问题设定:仅在一个或多个相关源域上训练模型,并直接泛化到目标域。
- 方法:
- 领域不变表示学习:最小化多个源域之间的领域差异。
- 情景训练策略:利用元学习方法开发模型以泛化到未见过的域。
- 领域特定知识:利用领域属性聚合领域特定的先验知识。
-
自监督正则化:
- 动机:利用无需注释的任务来学习数据的特征表示,为下游任务服务。
- 方法:
- 自监督任务:引入自监督任务来规范语义特征学习。
- 图像级恢复任务:开发图像级恢复自监督任务以进一步正则化模型。
例子:假设我们需要训练一个模型来识别和分类糖尿病视网膜病变图像。
-
步骤 1:使用UDA,我们可能会从一个医院(源域)获取有标签的图像,并从另一个医院(目标域)获取无标签的图像。
我们的目标是训练一个模型,能够在目标域的图像上表现良好,即使我们没有这些图像的标签。
-
步骤 2:如果目标域的数据因为隐私保护而不可用,我们转向DG。
我们将仅使用源域的数据来训练模型,并希望模型能够直接泛化到目标域。
-
步骤 3:为了提高模型的鲁棒性并减少过拟合,我们加入自监督正则化。
例如,我们可能会设计一个自监督任务,如图像级恢复,让模型学习如何从部分损坏的图像中恢复出完整的视网膜图像。
-
步骤 4:最终,我们评估模型在不同医院收集的糖尿病视网膜病变图像的分类性能。
如果模型在来自源域的测试集和未见过的目标域测试集(比如其他医院的数据)上都表现良好,那么我们可以认为模型具有良好的泛化能力。
完整流程:
- 数据准备
- 收集数据:从多个医院或诊所收集糖尿病视网膜图像。这些图像来自不同的设备,代表了多个源域。
- 标注数据:对部分数据进行专家标注,包括健康视网膜和不同阶段的糖尿病视网膜病变。
- 无监督领域适应 (UDA)
- 目标域数据:假设某些医院的数据无法获取标签,这些数据被视为目标域数据。
- UDA应用:使用有标签的源域数据和无标签的目标域数据,训练一个模型,尝试缩小源域和目标域间的分布差异。
- 领域泛化 (DG)
- 模型训练:如果无法访问目标域数据或者目标域过于广泛,采用DG策略。仅使用源域的有标签数据训练模型,并期望它能够泛化到新的、未见过的目标域。
- 自监督正则化
- 自监督任务设计:设计自监督任务,如预测图像的缺失部分,作为训练过程的一部分。这有助于模型学习更丰富的特征表示,增强泛化能力。
- 随机振幅混合(RAM)模块
- 数据增强:使用RAM技术生成新的训练图像。这些图像结合了来自不同源域图像的频率信息,增加数据多样性,帮助模型学习处理来自不同设备的图像变化。
- 训练流程
- 模型训练:结合上述技术,训练糖尿病视网膜分类模型。利用自监督任务和RAM增强的数据,以及原始的有标签数据进行训练。
- 损失函数:使用分类损失(如交叉熵损失),以及自监督任务的损失来优化模型。
- 评估和应用
- 性能评估:在独立的测试集上评估模型性能,测试集包括来自未见过医院(设备)的图像。
- 应用:将训练好的模型部署到临床环境中,帮助医生识别和分类糖尿病视网膜病变,以便及时治疗。
通过这个流程,可以看到UDA、DG、自监督正则化、RAM模块和训练流程如何相互配合,共同解决糖尿病视网膜病变分类任务中的领域适应问题。
这个综合策略旨在提高模型对于不同设备、不同医院收集的图像的泛化能力,确保在实际应用中具有较高的准确性和可靠性。
数学构造
- 傅立叶变换 (公式 1)
- 目的:将图像从空间域转换到频率域。
- 推导:
- 对于每个图像 x i k x^k_i xik,计算其傅立叶变换 F ( x i k ) F(x^k_i) F(xik)。
- 傅立叶变换把图像转换为频率空间信号,表示为 F ( x i k ) ( u , v ) F(x^k_i)(u,v) F(xik)(u,v)。
F ( x i k ) ( u , v , c ) = ∑ h = 0 H − 1 ∑ w = 0 W − 1 x i k ( h , w , c ) e − j 2 π ( h H u + w W v ) , j 2 = − 1. F(x_i^k)(u, v, c) = \sum_{h=0}^{H-1} \sum_{w=0}^{W-1} x_i^k(h, w, c)e^{-j2\pi(\frac{h}{H}u + \frac{w}{W}v)}, \quad j^2 = -1. F(xik)(u,v,c)=h=0∑H−1w=0∑W−1xik(h,w,c)e−j2π(Hhu+Wwv),j2=−1.
- 振幅和相位分解 (无明确公式编号)
- 目的:在频率域中分解图像为振幅和相位,振幅包含风格信息,相位包含结构信息。
- 推导:
- 从傅立叶变换得到的信号 F ( x i k ) F(x^k_i) F(xik) 中分解出振幅 A i k A^k_i Aik 和相位 P i k P^k_i Pik。
- 随机振幅混合 (RAM) (公式 2 和 3)
- 目的:通过混合不同源域图像的振幅,生成新的图像以增加数据多样性。
- 推导:
- 随机选择一个样本图像 x i k x^k_i xik 和另一个样本 x j n x^n_j xjn。
- 通过权重 λ \lambda λ 和二元掩码 M M M 插值两个图像的振幅 A i k A^k_i Aik 和 A j n A^n_j Ajn。
- 使用插值后的振幅 A i n → k A^{n \rightarrow k}_i Ain→k 与原始相位 P i k P^k_i Pik 通过逆傅立叶变换合成新图像 x i n → k x^{n \rightarrow k}_i xin→k。
A i , λ n → k = A i k ∗ ( 1 − M ) + ( ( 1 − λ ) A i k + λ A j n ) ∗ M , A_{i, \lambda}^{n \rightarrow k} = A_i^k * (1 - M) + ((1 - \lambda)A_i^k + \lambda A_j^n) * M, Ai,λn→k=Aik∗(1−M)+((1−λ)Aik+λAjn)∗M,
x i , λ n → k = F − 1 ( A i , λ n → k , P i k ) , x_{i, \lambda}^{n \rightarrow k} = F^{-1}(A_{i, \lambda}^{n \rightarrow k}, P_i^k), xi,λn→k=F−1(Ai,λn→k,Pik),
- 分割模型训练 (公式 4, 5, 6, 7 和 8)
- 目的:训练模型以进行图像分割,并通过损失函数优化。
- 推导:
- 定义分割模型的前向传播,使用编码器 E E E 和分割解码器 D s e g D_{seg} Dseg。
- 计算预测的分割掩码 y ^ i k \hat{y}^k_i y^ik。
- 通过交叉熵损失 L c e L_{ce} Lce 和 Dice 损失 L d i c e L_{dice} Ldice 优化模型,这两个损失结合评估分割的精确度和一致性。
y ^ i k = D s e g ( E ( x i k ) ) , \hat{y}_i^k = D_{seg}(E(x_i^k)), y^ik=Dseg(E(xik)),
y ^ i , λ n → k = D s e g ( E ( x i , λ n → k ) ) , \hat{y}_{i, \lambda}^{n \rightarrow k} = D_{seg}(E(x_{i, \lambda}^{n \rightarrow k})), y^i,λn→k=Dseg(E(xi,λn→k)),
L c e k = − 1 N ∑ i = 0 N − 1 ( y i k log y ^ i k + ( 1 − y i k ) log ( 1 − y ^ i k ) ) , L_{ce}^k = -\frac{1}{N} \sum_{i=0}^{N-1} (y_i^k \log \hat{y}_i^k + (1 - y_i^k) \log(1 - \hat{y}_i^k)), Lcek=−N1i=0∑N−1(yiklogy^ik+(1−yik)log(1−y^ik)),
L d i c e k = 1 − 2 ∑ i = 0 N − 1 y i k y ^ i k ∑ i = 0 N − 1 ( y i k + y ^ i k + ϵ ) , L_{dice}^k = 1 - \frac{2 \sum_{i=0}^{N-1} y_i^k \hat{y}_i^k}{\sum_{i=0}^{N-1}(y_i^k + \hat{y}_i^k + \epsilon)}, Ldicek=1−∑i=0N−1(yik+y^ik+ϵ)2∑i=0N−1yiky^ik,
L s e g k = L d i c e k + L c e k , L s e g n → k = L d i c e n → k + L c e n → k . ( 8 ) \mathcal{L}_{seg}^k=\mathcal{L}_{dice}^k+\mathcal{L}_{ce}^k,\quad\mathcal{L}_{seg}^{n\to k}=\mathcal{L}_{dice}^{n\to k}+\mathcal{L}_{ce}^{n\to k}.\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad(8) Lsegk=Ldicek+Lcek,Lsegn→k=Ldicen→k+Lcen→k.(8)
- 语义一致性损失 (公式 9)
- 目的:确保分割模型在风格化图像和原始图像上具有一致的预测。
- 推导:
- 使用KL散度 K L KL KL 计算预测掩码和目标掩码之间的差异。
- 通过 L c o n s i s t L_{consist} Lconsist 最小化源域和合成图像预测之间的差异。
L c o n s i s t k = 1 N ∑ i = 0 N − 1 ( K L ( y ^ i k ∥ y ^ i , λ n → k ) + K L ( y ^ i , λ n → k ∥ y ^ i k ) ) , ( 9 ) \mathcal{L}_{consist}^k=\frac1N\sum_{i=0}^{N-1}\Big(\mathrm{KL}(\hat{y}_i^k\|\hat{y}_{i,\lambda}^{n\to k})+\mathrm{KL}(\hat{y}_{i,\lambda}^{n\to k}\|\hat{y}_i^k)\Big),\quad\quad\quad(9) Lconsistk=N1i=0∑N−1(KL(y^ik∥y^i,λn→k)+KL(y^i,λn→k∥y^ik)),(9)
- 领域特定图像恢复 (DSIR) (公式 10 和 11)
- 目的:从低级特征中恢复图像,作为正则化任务。
- 推导:
- 定义图像恢复模块的前向传播,使用编码器 E E E 和图像恢复解码器 D r e c D_{rec} Drec。
- 通过L2距离作为恢复损失 L r e c L_{rec} Lrec 来优化图像恢复模块。
x ^ i k = D r e c k ( E ( x i , λ n → k ) ) , ( 10 ) \begin{aligned}\hat{x}_{i}^{k}=D_{rec}^{k}(E(x_{i,\lambda}^{n\to k})),\quad(10)\end{aligned} x^ik=Dreck(E(xi,λn→k)),(10)
L r e c k = 1 N H W C ∑ i = 0 N − 1 ∑ h = 0 H − 1 ∑ w = 0 W − 1 ∑ c = 0 C − 1 ( x i k ( h , w , c ) − x ^ i k ( h , w , c ) ) 2 , ( 11 ) \begin{aligned}\mathcal{L}_{rec}^k&=\frac{1}{NHWC}\sum_{i=0}^{N-1}\sum_{h=0}^{H-1}\sum_{w=0}^{W-1}\sum_{c=0}^{C-1}\left(x_i^k(h,w,c)-\hat{x}_i^k(h,w,c)\right)^2,\quad(11)\end{aligned} Lreck=NHWC1i=0∑N−1h=0∑H−1w=0∑W−1c=0∑C−1(xik(h,w,c)−x^ik(h,w,c))2,(11)
7. 总损失 (公式 12)
- 目的:结合所有损失,以全面优化模型。
- 推导:
- 总损失 L t o t a l L_{total} Ltotal 是基础分割损失 L s e g k L_{seg}^k Lsegk、合成图像的分割损失 L s e g c n − k L_{seg}^{cn-k} Lsegcn−k、图像恢复损失 L r e c k L_{rec}^k Lreck 和一致性损失 L c o n s i s t k L_{consist}^k Lconsistk 的加权和。
- 每个损失函数都由一个对应的权重参数 λ \lambda λ 控制,这些权重参数在训练前需要设定。
- 总损失函数可以表示为:
L t o t a l = 1 K ∑ k = 1 K ( λ 1 L s e g k + λ 2 L s e g c n − k + λ 3 L r e c k + λ 4 L c o n s i s t k ) L_{total} = \frac{1}{K} \sum_{k=1}^{K} \left( \lambda_1 L_{seg}^k + \lambda_2 L_{seg}^{cn-k} + \lambda_3 L_{rec}^k + \lambda_4 L_{consist}^k \right) Ltotal=K1k=1∑K(λ1Lsegk+λ2Lsegcn−k+λ3Lreck+λ4Lconsistk)
其中, K K K 是源域的数量, λ 1 \lambda_1 λ1 到 λ 4 \lambda_4 λ4 是超参数,用来平衡不同损失项的重要性。
想象我们正在处理眼科疾病的诊断,需要从眼底图像中分割出视盘和视杯区域。
我们收集了来自多家医院的眼底图像,每家医院使用不同的眼底相机,这就在图像中造成了变化,可以被视为不同的“域”。
-
傅立叶变换(公式1):我们首先将每张眼底图像的空间信息转换为频率域,因为这样可以减少由于不同相机造成的图像对比度或亮度变化的影响。
例子:对于每张眼底图像,我们计算其傅立叶变换,捕捉图像的结构和纹理细节的频率成分。
-
振幅和相位分解:进行傅立叶变换后,我们分离振幅和相位成分。振幅可能包含了图像的风格信息,而相位则包含了结构信息。
例子:从变换后的眼底图像中,我们提取振幅和相位。振幅可能反映了视盘和视杯的纹理信息,而相位则描绘了它们的形状和位置。
-
随机振幅混合(RAM)(公式2和3):为了增加训练数据的多样性,我们混合了来自不同域的图像振幅,创造新的图像风格。
例子:我们可能会取一张来自甲医院的眼底图像的振幅,与乙医院的图像振幅混合,然后进行逆傅立叶变换,创建一个新的混合风格图像供模型学习。
-
分割模型训练(公式4, 5, 6, 7和8):模型被训练用来从原始图像和新创建的混合图像中分割视盘和视杯。它必须学会无视相机的特性,准确分割。
例子:模型在眼底图像中预测视盘和视杯的边界。我们使用交叉熵和Dice损失来评估预测分割与实际医学标注的一致性。
-
语义一致性损失(公式9):我们引入了语义一致性损失来确保模型对原始图像及其混合版本的分割预测保持一致性。
例子:如果模型在甲医院的图像中预测了视盘的边界,它也应该在由甲乙医院数据创建的混合图像中做出相似的预测,以保持预测的一致性。
-
领域特定图像恢复(DSIR)(公式10和11):此步骤帮助模型学习如何从混合频率信息中恢复原始眼底图像,加强对解剖结构的理解。
例子:模型尝试从混合了不同医院图像数据的频率信息中重建甲医院的原始眼底图像。
-
总损失(公式12):所有损失组成部分结合起来形成总损失,用于训练模型。
效果

红色轮廓表示真实的分割边界(ground truths),而绿色和蓝色轮廓表示由不同方法预测的分割边界。
可以看出,“Ours”(作者的方法)在分割边缘的精确度上与真实边缘的一致性较高,这表明其在这些任务上的有效性。
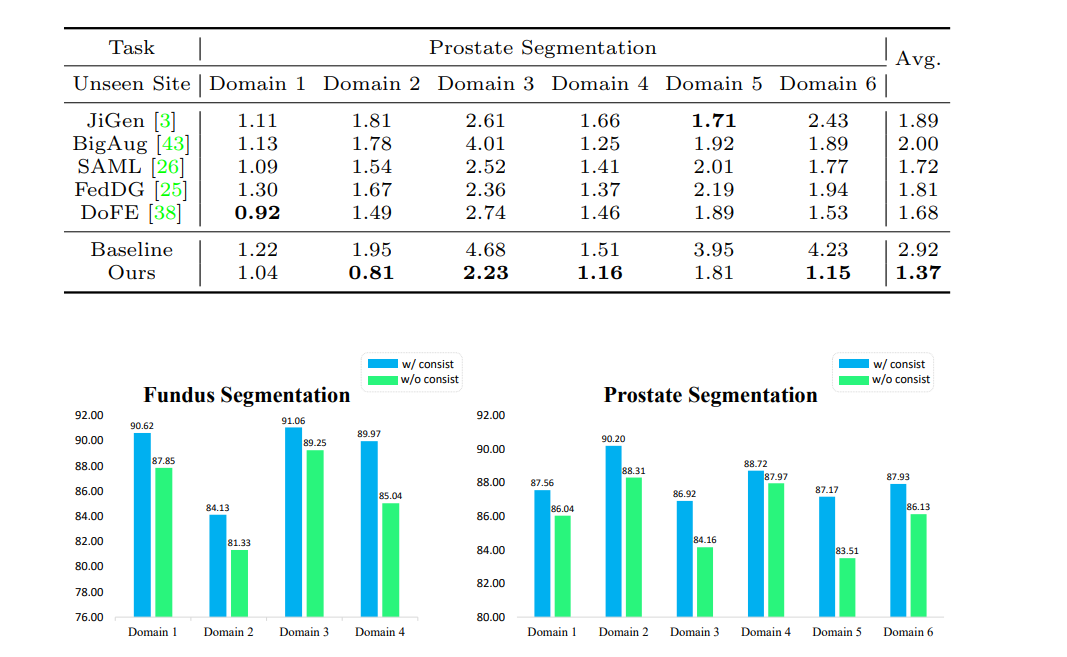
"语义一致性训练策略"本文提高模型泛化能力的方法,目的是确保模型在不同数据集(或称为“域”)上都能给出准确的分割结果。
这种策略涉及在训练过程中使用特定的损失函数,促使模型学习到在视觉上可能有所不同但在结构上应该相似的图像之间保持一致的分割预测。
图像中的Fig. 4,显示了两组数据:
- 绿色柱子表示当使用语义一致性损失作为训练模型的一部分时的模型性能,这种情况下的Dice系数通常更高。
- 蓝色柱子表示没有使用语义一致性损失进行训练时的模型性能,这种情况下的Dice系数较低。
Dice系数是一个衡量分割质量的指标,数值范围从0到1,数值越接近1,说明模型的分割结果与真实情况(即医生或专家标注的真实边缘)越吻合。
因此,图中绿色柱子较蓝色柱子高表示模型在使用语义一致性损失时能够获得更准确的分割结果。
性能差异的意义在于,通过使用语义一致性训练策略,模型能够更好地学习如何处理来自不同来源的图像,即便这些图像在外观上有所不同(比如由于不同的成像设备或成像条件造成的差异),模型依然能够准确识别出图像中的结构,这对于实际临床应用是非常重要的。
这篇关于RAM-DSIR:眼底和前列腺图像泛化能力增强,免除不同的扫描仪、成像协议和操作者等多种因素差异,影响学习效果的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







