泛化专题

R-Adapter:零样本模型微调新突破,提升鲁棒性与泛化能力 | ECCV 2024
大规模图像-文本预训练模型实现了零样本分类,并在不同数据分布下提供了一致的准确性。然而,这些模型在下游任务中通常需要微调优化,这会降低对于超出分布范围的数据的泛化能力,并需要大量的计算资源。论文提出新颖的Robust Adapter(R-Adapter),可以在微调零样本模型用于下游任务的同时解决这两个问题。该方法将轻量级模块集成到预训练模型中,并采用新颖的自我集成技术以提高超出分布范围的鲁棒性

模型“鲁棒性”是什么,和“泛化性”有什么异同。
文章目录 1.范例2. 鲁棒性包含哪些内容2.1. 对噪声的鲁棒性2.2. 对不同分辨率或缩放的鲁棒性2.3. 对图像压缩的鲁棒性2.4. 对光照变化的鲁棒性2.5. 对姿态和视角变化的鲁棒性2.6. 对领域迁移的鲁棒性2.7. 对对抗样本的鲁棒性2.8. 对丢失数据或不完整数据的鲁棒性2.9. 对时序数据的鲁棒性 3.鲁棒性和泛化性的关系3.1.泛化性(Generalization)3.2

人工智能:模型复杂度、模型误差、欠拟合、过拟合/泛化能力、过拟合的检测、过拟合解决方案【更多训练数据、Regularization/正则、Shallow、Dropout、Early Stopping】
人工智能:模型复杂度、模型误差、欠拟合、过拟合/泛化能力、过拟合的检测、过拟合解决方案【更多训练数据、Regularization/正则、Shallow、Dropout、Early Stopping】 一、模型误差与模型复杂度的关系1、梯度下降法2、泛化误差2.1 方差2.2 偏差2.3 噪声2.4 泛化误差的拆分 3、偏差-方差窘境(bias-variance dilemma)4、Bias

LoRAHUB:通过动态LoRA组合实现高效的跨任务泛化
大模型在微调时面临着计算效率和内存使用上的挑战。为了克服这些问题,研究者们提出了低秩适应(LoRA)技术,通过在模型的每层中引入可训练的低秩分解矩阵作为适配器模块,以参数高效的方式微调LLMs。 尽管LoRA在提高效率方面取得了进展,但关于LoRA模块的内在模块化和可组合性的研究还相对缺乏,来自Sea AI Lab、华盛顿大学圣路易斯分校和艾伦人工智能研究所的研究人员提出的LoRAHUB的新框架

大语言模型向量检索技术综述:背景知识、数据效率、泛化能力、多任务学习、未来趋势
预训练语言模型如BERT和T5,是向量检索(后续文中使用密集检索)的关键后端编码器。然而,这些模型通常表现出有限的泛化能力,并在提高领域内准确性方面面临挑战。最近的研究探索了使用大型语言模型(LLMs)作为检索器,实现了各种任务的最新性能。尽管取得了这些进展,LLMs相对于传统检索器的具体优势,以及不同LLM配置—例如参数大小、预训练持续时间和对齐过程—对检索任务的影响仍然不清楚。在这项工作中,我

机器学习和数据挖掘(6):雷蒙保罗MAPA泛化理论
泛化理论 上一章中提到的生长函数 mH(N) m_{\mathcal H}(N)的定义:假设空间在 N N个样本点上能产生的最大二分(dichotomy)数量,其中二分是样本点在二元分类情况下的排列组合。 上一章还介绍了突破点(break point)的概念,即不能满足完全分类情形的样本点个数。不存在kk个样本点能够满足完全分类情形,完全二分类情形(shattered)是可分出 2N 2^N种

正则化方法:防止过拟合,提高泛化能力
本文是《Neural networks and deep learning》概览 中第三章的一部分,讲机器学习/深度学习算法中常用的正则化方法。(本文会不断补充) 正则化方法:防止过拟合,提高泛化能力 在训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合)。其直观的表现如下图所示,随着训练过程的进行,模型复杂度增加,在training da

PyTorch 入坑十:模型泛化误差与偏差(Bias)、方差(Variance)
问题 阅读正文之前尝试回答以下问题,如果能准确回答,这篇文章不适合你;如果不是,可参考下文。 为什么会有偏差和方差?偏差、方差、噪声是什么?泛化误差、偏差和方差的关系?用图形解释偏差和方差。偏差、方差窘境。偏差、方差与过拟合、欠拟合的关系?偏差、方差与模型复杂度的关系?偏差、方差与bagging、boosting的关系?偏差、方差和K折交叉验证的关系?如何解决偏差、方差问题? 本文主要参考知

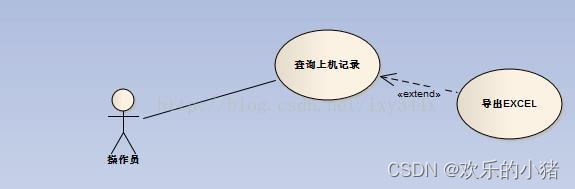
用例与用例之间的三种关系:泛化、包含、扩展
UML用例图(Use Case Diagrame),是UML图的一种,主要用来描述角色及角色与用例之间的连接关系。 1.泛化 当多个用例共有一种类似的结构和行为时。能够将他们的共性抽象成为父用例,其它的用例作为泛化关系的子用例。箭头指向父用例 用例图如 2.包含 当能够从两个或两个以上的用例中提取公共行为时,应该使用包含的关系来表示它们。这个提取出来的公共用例成为抽象用例。而

MI-SegNet: 基于互信息的超越领域泛化的超声图像分割
文章目录 MI-SegNet: Mutual Information-Based US Segmentation for Unseen Domain Generalization摘要方法实验结果 MI-SegNet: Mutual Information-Based US Segmentation for Unseen Domain Generalization 摘要 针对医

P10-P11【重载,模板,泛化和特化】【分配器的实现】
三类模板(类模板)(函数模板)(成员函数模板) 特化 偏特化:模板参数个数/模板范围 定义的分配器 以上分配器的性能和内存管理有很大不足(在分配内存时,会产生很大的内存开销) 延续了G2.9的alloc
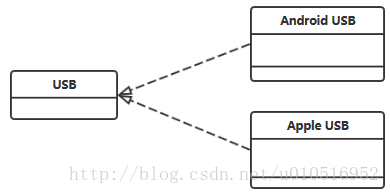
类图中的依赖、关联、聚集、构成、泛化、实现关系
一、依赖(Dependency) 依赖:A类依赖B类,在B类发生变化时,A类也会随着B类发生变化;通常依赖的类是作为参数传入。 1. Car类是User类中的(某个方法的)局部变量; 2. Car类是User类方法当中的一个参数; 3. Car类向User类发送消息,从而影响B类发生变化; 二、关联(Association) 关联:表示订单与产品对象之间存在关系;关联关
微调(fine-tuning)和泛化(generalization)
主要讨论两个主要方面:微调(fine-tuning)和泛化(generalization)。 文章目录 微调 Fine-tune泛化 Generalization 微调 Fine-tune 对于微调:选择合理的步骤(也就是迭代轮数或称为epochs),以获得良好的下游任务性能,但同时避免过拟合。微调是指在一个已经在大规模数据上预训练好的模型的基础上,针对特定任务领域的数据进行调

##15 探索高级数据增强技术以提高模型泛化能力
文章目录 前言数据增强的重要性常见的数据增强技术高级数据增强技术在PyTorch中实现数据增强结论 前言 在深度学习领域,数据增强是一种有效的技术,它可以通过在原始数据上应用一系列变换来生成新的训练样本,从而增加数据的多样性,提高模型的泛化能力。在图像识别、语音识别等任务中,数据增强被广泛用于避免过拟合,特别是在数据量较少的情况下。本文将详细探讨高级数据增强技术,并展示如何
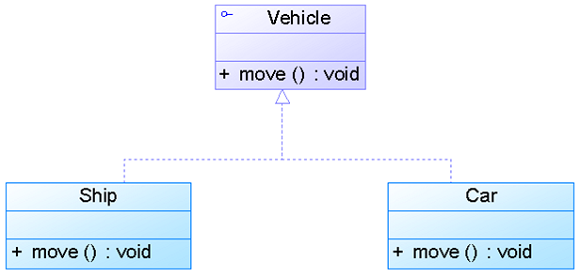
【47】java的类之间的关系:泛化、依赖、关联、实现、聚合、组合
java的类之间的关系:泛化、依赖、关联、实现、聚合、组合 泛化: • 泛化关系(Generalization)也就是继承关系,也称为“is-a-kind-of”关系,泛化关系用于描述父类与子类之间的关系,父类又称作基类或超类,子类又称作派生类。在UML中,泛 化关系用带空心三角形的直线来表示。 • 在代码实现时,使用面向对象的继承机制来实现泛化关系,如在Java语言中使用extends关键字
树形DP(3) Hdu3593 The most powerful force (泛化背包)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=3593 The most powerful force Time Limit: 16000/8000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Submission(s): 938 Accepted

理解深度学习需要重新思考泛化
这篇文章来自ICLR2017 best paper,是一片十分有争议的文章,看完之后在小组会上跟大家分享了这篇文章,最终经过一系列讨论,结合种种实验得出结论,我们认为数据对于泛化性能来说是十分重要的,因为对于实验中的数据来说,我们可以发现在真实数据上的实验结果以及泛化结果相对于其他数据副本来说都是极具优势的。以下为个人观点: 我认为这篇文章只是提出了一个新的思考,给出了一个新的研究方向,至于是否
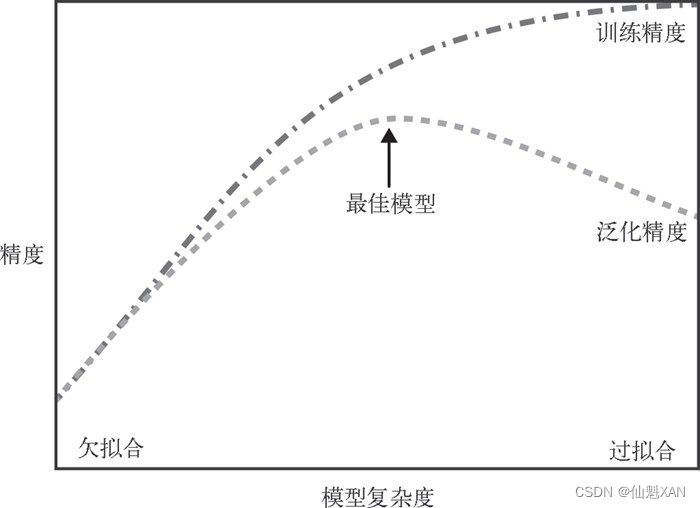
Python 机器学习 基础 之 监督学习/分类问题/回归任务/泛化、过拟合和欠拟合 基础概念说明
Python 机器学习 基础 之 监督学习/分类问题/回归任务/泛化、过拟合和欠拟合 基础概念说明 目录 Python 机器学习 基础 之 监督学习/分类问题/回归任务/泛化、过拟合和欠拟合 基础概念说明 一、简单介绍 二、监督学习 三、分类问题 四、回归任务 五、泛化、过拟合和欠拟合 1、基础概念 2、举例说明 模型复杂度与数据集大小的关系 一、简单介绍 Py
数据增强:提升模型泛化能力的秘诀
引言 在深度学习中,数据是模型性能的关键。然而,收集大量标注数据既昂贵又耗时。幸运的是,数据增强技术可以帮助我们通过生成图像的变体来人工扩充数据集,从而提高模型的泛化能力。在本博客中,我们将探索数据增强的概念,并将其应用于美国手语(ASL)数据集的图像分类任务。 数据增强的重要性 数据增强通过应用一系列随机变换(如旋转、缩放、裁剪等)来增加数据的多样性,这有助于模型学习到更加鲁棒的特征表示,
为什么深度学习中减小泛化误差称为“正则化(Regularization)”
深度学习的一个重要方面是正则化(Regularization),Ian Goodfellow在《Deep Learning 》称正则化(Regularization)就是减小泛化误差。那么,为什么减小泛化误差称为正则化呢? 首先看正则化——Regularization这个单词,Regularization是创造出来的词,在牛津词典和柯林斯词典上都没有,但是有regularize。柯林斯词典对re

从少数示例中泛化:介绍小样本学习(Few-shot Learning,FSL)
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 论文题目:Generalizing from a Few Examples: A Survey on Few-shot Learning(ACM Computing Surveys,中科院 1 区) 这篇综述论文的主题是 “从少数示例中泛化:小样本学习综述”。它探讨了小样本学习(Few-shot

20个你可以用来避免过拟合和得到更好的泛化的技巧
英文原文地址:How To Improve Deep Learning Performance 原博客链接:机器学习系列(10)_如何提高深度学习(和机器学习)的性能 原文翻译:王昱森(ethanwang92@outlook.com) 翻译与校对:寒小阳(hanxiaoyang.ml@gmail.com) 我经常被问到诸如如何从深度学习模型中得到更好的效果的问题,类似的问题还有:

为什么要训练数据集和测试数据集——模型的泛化能力
首先,自定义与上一节同样的数据集。 对数据进行 train test split,对测试集数据与预测数据进行均方误差分析: from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)from skle