本文主要是介绍MI-SegNet: 基于互信息的超越领域泛化的超声图像分割,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- MI-SegNet: Mutual Information-Based US Segmentation for Unseen Domain Generalization
- 摘要
- 方法
- 实验结果
MI-SegNet: Mutual Information-Based US Segmentation for Unseen Domain Generalization
摘要
- 针对医学图像分割在不同领域间泛化能力有限的问题,特别是针对超声成像,论文提出了一种新的方法称为MI-SegNet。
- 超声成像的质量很依赖于声学参数的精细调整,这些参数在不同的操作者、设备和环境中都存在差异,导致了领域偏移问题。
- MI-SegNet利用互信息(MI)来显式地分离解耦解剖特征和领域特征表示,从而可以期望获得更鲁棒的领域无关分割性能。
- 该方法使用两个编码器网络来分别学习解剖和领域特征,分割任务只使用解剖特征图进行预测。通过交叉重建等训练技巧来促进编码器学习到有意义的特征表示。
- 此外,还应用了特定于领域或解剖的变换,并惩罚两个特征图之间的任何残留MI,进一步促进特征空间的分离。
代码地址
方法
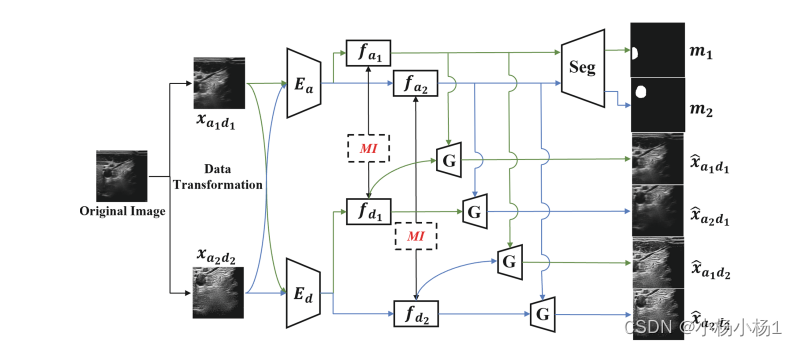
- 输入: 两张输入图像,分别为xa1d1和xa2d2。它们来自不同的领域d1和d2。
- 编码器: 使用两个独立的编码器网络(Encoder1和Encoder2)来分别提取解剖特征和领域特征。
- 分割模块: 接收Encoder1提取的解剖特征,并执行语义分割任务,输出分割结果。
- 重建模块: 将Encoder1和Encoder2提取的特征输入到重建模块,进行交叉重建以确保两个编码器学习到有意义的特征表示。
- 变换模块: 对输入图像施加特定于领域或解剖的变换,以指导编码器网络学习相应的特征。
- MI惩罚: 计算两个编码器的输出特征之间的互信息(MI),并将其最小化,进一步促进特征空间的分离。
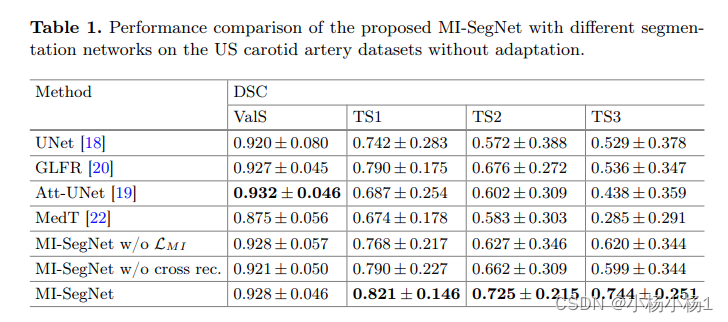
实验结果


这篇关于MI-SegNet: 基于互信息的超越领域泛化的超声图像分割的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






