本文主要是介绍Python 机器学习 基础 之 监督学习/分类问题/回归任务/泛化、过拟合和欠拟合 基础概念说明,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Python 机器学习 基础 之 监督学习/分类问题/回归任务/泛化、过拟合和欠拟合 基础概念说明
目录
Python 机器学习 基础 之 监督学习/分类问题/回归任务/泛化、过拟合和欠拟合 基础概念说明
一、简单介绍
二、监督学习
三、分类问题
四、回归任务
五、泛化、过拟合和欠拟合
1、基础概念
2、举例说明
一、简单介绍
Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。Python是一种解释型脚本语言,可以应用于以下领域: Web 和 Internet开发、科学计算和统计、人工智能、教育、桌面界面开发、软件开发、后端开发、网络爬虫。
Python 机器学习是利用 Python 编程语言中的各种工具和库来实现机器学习算法和技术的过程。Python 是一种功能强大且易于学习和使用的编程语言,因此成为了机器学习领域的首选语言之一。Python 提供了丰富的机器学习库,如Scikit-learn、TensorFlow、Keras、PyTorch等,这些库包含了许多常用的机器学习算法和深度学习框架,使得开发者能够快速实现、测试和部署各种机器学习模型。
Python 机器学习涵盖了许多任务和技术,包括但不限于:
- 监督学习:包括分类、回归等任务。
- 无监督学习:如聚类、降维等。
- 半监督学习:结合了有监督和无监督学习的技术。
- 强化学习:通过与环境的交互学习来优化决策策略。
- 深度学习:利用深度神经网络进行学习和预测。
通过 Python 进行机器学习,开发者可以利用其丰富的工具和库来处理数据、构建模型、评估模型性能,并将模型部署到实际应用中。Python 的易用性和庞大的社区支持使得机器学习在各个领域都得到了广泛的应用和发展。
二、监督学习
监督学习 是机器学习中一种重要的范式,它通过已知输入和对应输出的训练样本来学习预测新输入的输出。在监督学习中,每个训练样本都有一个与之对应的标签或目标值,这些标签或目标值是我们希望模型能够预测的结果。监督学习的基本目标是根据输入和输出之间的关系来学习一个函数,从而使模型能够在给定新的输入时预测相应的输出。
- 记住,每当想要根据给定输入预测某个结果,并且还有输入 / 输出对的示例时,都应该使用监督学习。
- 这些输入 / 输出对构成了训练集,我们利用它来构建机器学习模型。
- 我们的目标是对从未见过的新数据做出准确预测。
- 监督学习通常需要人力来构建训练集,但之后的任务本来非常费力甚至无法完成,现在却可以自动完成,通常速度也更快。
监督学习通常在以下情况下使用:
- 当我们有一组带有标签的训练数据时,我们希望利用这些数据来建立一个模型,以便预测新的输入数据的输出。
- 当我们需要对数据进行分类(将数据分到预定义的类别中)或回归预测(预测连续变量)时,监督学习是一个常见的选择。
监督学习可以分为两大类别:分类和回归
分类: 分类是监督学习的一种重要形式,用于解决离散目标变量的问题。在分类问题中,模型的目标是将输入数据分到预定义的类别中。例如,电子邮件分类(垃圾邮件或非垃圾邮件)、图像识别(猫、狗、汽车等)、疾病诊断(患有疾病或健康)等都是分类问题的示例。
回归: 回归是监督学习的另一种形式,用于解决连续目标变量的问题。在回归问题中,模型的目标是预测输入数据的数值输出。例如,房价预测、股票价格预测、销售量预测等都是回归问题的示例。
监督学习中常见的算法包括:
分类算法:
- 逻辑回归(Logistic Regression):用于解决二分类问题的线性模型,可以进行概率估计。
- 决策树(Decision Tree):通过树状结构对数据进行分割,可解释性强。
- 支持向量机(Support Vector Machine,SVM):建立在最大化间隔的基础上,适用于高维数据集。
- 朴素贝叶斯(Naive Bayes):基于贝叶斯定理,假设特征之间相互独立。
- K 最近邻算法(K-Nearest Neighbors,KNN):基于邻居的投票来进行分类,非参数模型。
回归算法:
- 线性回归(Linear Regression):用于建立输入特征与目标变量之间的线性关系模型。
- 多项式回归(Polynomial Regression):通过多项式函数拟合数据,适用于非线性关系。
- 决策树回归(Decision Tree Regression):类似于分类决策树,但用于预测连续目标变量。
- 支持向量机回归(Support Vector Machine Regression):与支持向量机分类类似,但用于回归问题。
- 随机森林回归(Random Forest Regression):是随机森林的回归版本,通过多个决策树集成来预测目标变量。
选择适合问题需求的监督学习算法取决于数据的特征、目标变量的类型、问题的复杂度以及算法的性能要求。
三、分类问题
分类问题的目标是预测类别标签 (class label),这些标签来自预定义的可选列表。第 1 章讲过一个例子,即将鸢尾花分到三个可能的品种之一。分类问题有时可分为二分类 (binary classification,在两个类别之间进行区分的一种特殊情况)和多分类 (multiclass classification,在两个以上的类别之间进行区分)。你可以将二分类看作是尝试回答一道是 / 否问题。将电子邮件分为垃圾邮件和非垃圾邮件就是二分类问题的实例。在这个二分类任务中,要问的是 / 否问题为:“这封电子邮件是垃圾邮件吗?”
在二分类问题中,我们通常将其中一个类别称为正类 (positive class),另一个类别称为反类 (negative class)。这里的“正”并不代表好的方面或正数,而是代表研究对象。因此在寻找垃圾邮件时,“正”可能指的是垃圾邮件这一类别。将两个类别中的哪一个作为“正类”,往往是主观判断,与具体的领域有关。
另一方面,鸢尾花的例子则属于多分类问题。另一个多分类的例子是根据网站上的文本预测网站所用的语言。这里的类别就是预定义的语言列表。
四、回归任务
回归任务的目标是预测一个连续值,编程术语叫作浮点数 (floating-point number),数学术语叫作实数 (real number)。根据教育水平、年龄和居住地来预测一个人的年收入,这就是回归的一个例子。在预测收入时,预测值是一个金额 (amount),可以在给定范围内任意取值。回归任务的另一个例子是,根据上一年的产量、天气和农场员工数等属性来预测玉米农场的产量。同样,产量也可以取任意数值。
区分分类任务和回归任务有一个简单方法,就是问一个问题:输出是否具有某种连续性。如果在可能的结果之间具有连续性,那么它就是一个回归问题。想想预测年收入的例子。输出具有非常明显的连续性。一年赚 40 000 美元还是 40 001 美元并没有实质差别,即使两者金额不同。如果我们的算法在本应预测 40 000 美元时的预测结果是 39 999 美元或 40 001 美元,不必过分在意。
- 与此相反,对于识别网站语言的任务(这是一个分类问题)来说,并不存在程度问题。
- 网站使用的要么是这种语言,要么是那种语言。
- 在语言之间不存在连续性,在英语和法语之间 不存在其他语言。
五、泛化、过拟合和欠拟合
1、基础概念
泛化、过拟合和欠拟合是机器学习中常见的概念,它们描述了模型在训练集和测试集上的表现情况。
泛化(Generalization): 泛化指的是模型在未见过的数据上表现良好的能力。一个良好的模型应该能够适应训练集中的模式,并且能够推广到未见过的数据上,而不仅仅是在训练集上表现良好。
过拟合(Overfitting): 过拟合指的是模型在训练集上表现过于优秀,但在测试集上表现不佳的情况。过拟合通常发生在模型过于复杂或者训练数据过少的情况下,模型学习到了训练集中的噪声和细节,而忽略了数据中的真实模式。过拟合的模型可能会在测试集上表现不佳,因为它们学到了训练集上的特殊情况,而无法泛化到新的数据上。
欠拟合(Underfitting): 欠拟合指的是模型在训练集和测试集上都表现不佳的情况。欠拟合通常发生在模型过于简单或者训练数据不足的情况下,模型无法捕捉到数据中的复杂模式和关系。欠拟合的模型可能会在训练集上表现较差,并且也不能很好地泛化到测试集上。
假设有一个简单的分类问题,我们的目标是根据花朵的特征(如花瓣长度和宽度)来预测花的种类(如鸢尾花的三个品种之一)。我们使用一个具有多个隐藏层和大量神经元的深度神经网络来训练模型。
- 如果我们的模型在训练集上表现非常好,但在测试集上表现较差,这可能是因为模型过拟合了训练集中的噪声和细节,无法泛化到新的数据上。
- 如果我们的模型在训练集和测试集上都表现不佳,可能是因为模型太简单,无法捕捉到数据中的复杂模式,导致欠拟合。
- 如果我们的模型在训练集和测试集上都表现良好,能够很好地泛化到新的数据上,那么我们的模型就是一个泛化能力强的模型。
因此,泛化、过拟合和欠拟合是评估机器学习模型性能的重要指标,我们需要通过适当的模型选择、调整和验证来确保我们的模型能够在新的数据上表现良好。
2、举例说明
为了说明这一点,我们来看一个虚构的例子。比如有一个新手数据科学家,已知之前船的买家记录和对买船不感兴趣的顾客记录,想要预测某个顾客是否会买船。 目标是向可能购买的人发送促销电子邮件,而不去打扰那些不感兴趣的顾客。
假设我们有顾客记录,如表 所示。
| 年龄 | 拥有的小汽车数量 | 是否有房子 | 子女数量 | 婚姻状况 | 是否养狗 | 是否买过船 |
| 66 | 1 | 是 | 2 | 丧偶 | 否 | 是 |
| 52 | 2 | 是 | 3 | 已婚 | 否 | 是 |
| 22 | 0 | 否 | 0 | 已婚 | 是 | 否 |
| 25 | 1 | 否 | 1 | 单身 | 否 | 否 |
| 44 | 0 | 否 | 2 | 离异 | 是 | 否 |
| 39 | 1 | 是 | 2 | 已婚 | 是 | 否 |
| 26 | 1 | 否 | 2 | 单身 | 否 | 否 |
| 40 | 3 | 是 | 1 | 已婚 | 是 | 否 |
| 53 | 2 | 是 | 2 | 离异 | 否 | 是 |
| 64 | 2 | 是 | 3 | 离异 | 否 | 否 |
| 58 | 2 | 是 | 2 | 已婚 | 是 | 是 |
| 33 | 1 | 否 | 1 | 单身 | 否 | 否 |
对数据观察一段时间之后,我们的新手数据科学家发现了以下规律:
- “如果顾客年龄大于 45 岁,并且子女少于 3 个或没有离婚,那么他就想要买船。”如果你问他这个规律的效果如何,我们的数据科学家会回答:“100% 准确!”的确,对于表中的数据,这条规律完全正确。
- 我们还可以发现好多规律,都可以完美解释这个数据集中的某人是否想要买船。数据中的年龄都没有重复,因此我们可以这样说:66、52、53 和 58 岁的人想要买船,而其他年龄的人都不想买。
虽然我们可以编出许多条适用于这个数据集的规律,但要记住:
- 我们感兴趣的并不是对这个数据集进行预测,我们已经知道这些顾客的答案。
- 我们想知道 新顾客 是否可能会买船。
- 因此,我们想要找到一条适用于新顾客的规律,而在训练集上实现 100% 的精度对此并没有帮助。
- 我们可能认为数据科学家发现的规律无法适用于新顾客。
- 它看起来过于复杂,而且只有很少的数据支持。例如,规律里“或没有离婚”这一条对应的只有一名顾客。
判断一个算法在新数据上表现好坏的唯一度量,就是在测试集上的评估。
然而从直觉上看 ,我们认为简单的模型对新数据的泛化能力更好。
- 如果规律是“年龄大于 50 岁的人想要买船”,并且这可以解释所有顾客的行为,那么我们将更相信这条规律,而不是与年龄、子女和婚姻状况都有关系的那条规律。
- 因此,我们总想找到最简单的模型。构建一个对现有信息量来说过于复杂的模型,正如我们的新手数据科学家做的那样,这被称为过拟合 (overfitting)。
- 如果你在拟合模型时过分关注训练集的细节,得到了一个在训练集上表现很好、但不能泛化到新数据上的模型,那么就存在过拟合。
- 与之相反,如果你的模型过于简单——比如说,“有房子的人都买船”——那么你可能无法抓住数据的全部内容以及数据中的变化,你的模型甚至在训练集上的表现就很差。选择过于简单的模型被称为欠拟合 (underfitting)。
我们的模型越复杂,在训练数据上的预测结果就越好。但是,如果我们的模型过于复杂,我们开始过多关注训练集中每个单独的数据点,模型就不能很好地泛化到新数据上。
二者之间存在一个最佳位置,可以得到最好的泛化性能。这就是我们想要的模型。
如图是,过拟合与欠拟合之间的权衡:
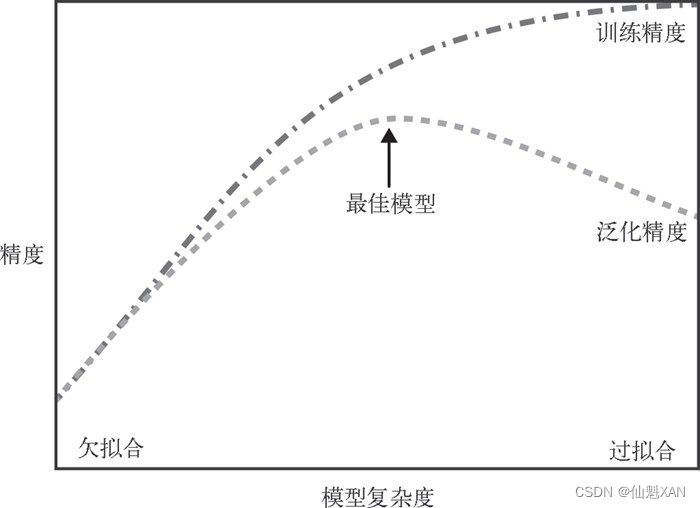
模型复杂度与数据集大小的关系
- 需要注意,模型复杂度与训练数据集中输入的变化密切相关:
- 数据集中包含的数据点的变化范围越大,在不发生过拟合的前提下你可以使用的模型就越复杂。
- 通常来说,收集更多的数据点可以有更大的变化范围,所以更大的数据集可以用来构建更复杂的模型。
- 但是,仅复制相同的数据点或收集非常相似的数据是无济于事的。
回到前面卖船的例子,如果我们查看了 10 000 多行的顾客数据,并且所有数据都符合这条规律:“如果顾客年龄大于 45 岁,并且子女少于 3 个或没有离婚,那么他就想要买船”,那么我们就更有可能相信这是一条有效的规律,比从表 2-1 中仅 12 行数据得出来的更为可信。
- 收集更多数据,适当构建更复杂的模型,对监督学习任务往往特别有用。
- 在现实世界中,你往往能够决定收集多少数据,这可能比模型调参更为有效。
- 永远不要低估更多数据的力量!
这篇关于Python 机器学习 基础 之 监督学习/分类问题/回归任务/泛化、过拟合和欠拟合 基础概念说明的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






