本文主要是介绍谈一谈在OCR/场景文本识别中的对抗攻击,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
目前对抗攻击在计算机视觉中如火如荼,作为计算机视觉的一个子领域OCR,文本识别和文本检测领域中对抗攻击的任务并不多,其中文本检测可以说是一种目标检测的任务,所以目标检测的攻击方法可以直接应用在文本检测中;文本识别是一种序列分类的任务和很多图像分类任务不同,所以攻击方法不能直接迁移,下面我们对三篇论文来看一看他们的攻击思路。
Adaptive Adversarial Attack on Scene Text Recognition (INFOCOM 2020)主要针对场景文本
动机
最近的研究表明,最先进的深度学习模型容易受到小扰动的影响(对抗性例子)。在对抗性例子中观察到两个关键的障碍:(i)最近的对抗性攻击需要手动调整超参数,并且需要很长时间来构建对抗性例子,这使得攻击实时系统变得不切实际;(ii)大多数研究集中在非序列任务上,例如图像分类,但是只有少数考虑顺序任务。
贡献点
- 在这项工作中,我们提出了一种自适应的方法来加速对抗性攻击,特别是在顺序学习任务上。通过利用每个任务的不确定性,我们直接学习自适应多任务权重,而不需要手动搜索超参数。
- 开发了一个统一的体系结构,并对非顺序任务和顺序任务进行了评估。为了评价该方法的有效性,我们以场景文本识别任务为例进行了研究。据我们所知,我们提出的方法是第一次尝试对抗性攻击的场景文本识别。与最新的对抗攻击相比,自适应攻击以3∼6倍的速度达到99.9%以上的成功率。
文章剖析
作者首先发现两个任务之间的最优权重强烈依赖于任务(例如,图像距离与音频距离、交叉熵损失与CTC损失)。研究者和实践者必须在任务损失之间仔细选择适当的权重,以获得良好的绩效。因此,寻找一种更好的方法来自动学习最优权值是很有必要的。最近,Kendall等人。提出了一种将观测(任意)不确定性和模型(认知)不确定性相结合的多任务权重计算方法。其解决方案仅限于非序列学习任务(如图像分类、图像分割),这可能不直接适用于对序列学习任务的对抗性攻击。
以攻击文本识别任务为例。非序列对抗实例与序列对抗实例的区别在于:
i)序列模型的输出是可变长度的标签,而不是单个标签。
ii)非序列攻击(如对象分类模型)只涉及替换操作(如修改原始类标签),而序列攻击考虑插入、替换和删除三种操作(如插入:coat→coats,替换:coat→cost,删除:coat→cot)。目标标签中的每个字符需要良好对齐。输入和输出之间的一致性要求在生成对抗性示例时提出了挑战;
iii)序列模型通常利用递归神经网络,其中内部特征表示涉及比卷积神经网络更多的序列上下文。
简单来说,作者的思路就是将对抗攻击看作一个多任务学习,然后将Kendall等人提出的一种多任务权重计算方法拓展到了序列学习当中,特别是场景文本识别任务。
首先看一看对抗攻击的多任务学习形式, x x x为原始样本, x ′ x' x′为对抗样本, D ( ) D\left( \right) D()为距离衡量函数, l l l为原始标签, l ′ l' l′为目标标签。那么对抗攻击可以表示成下面形式:
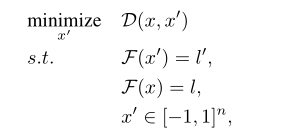
在序列任务中, l l l为序列, F ( ) F\left( {} \right) F()为CTC损失函数,并且我们用一个新的变量 ω \omega ω 代替对抗样本: x ′ = tanh ( ω ) x' = \tanh \left( \omega \right) x′=tanh(ω),则上式可以化简为:
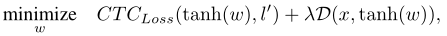
接下来作者又讲到了Kendall等人提出的多任务权重计算方法:
对于回归任务:
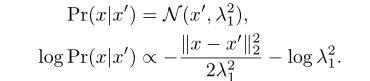
对于分类任务:
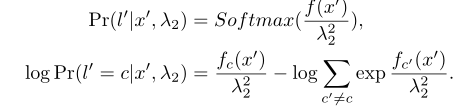
对抗攻击多任务的联合自适应损失如下:
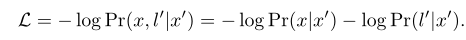
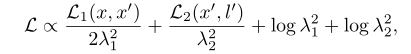
自适应多任务学习在序列任务种的拓展(作者的核心工作), π 1 {\pi _1} π1和 π 2 {\pi _2} π2是推理过程中的两条路径。设计详细的数学推导,不再赘述:
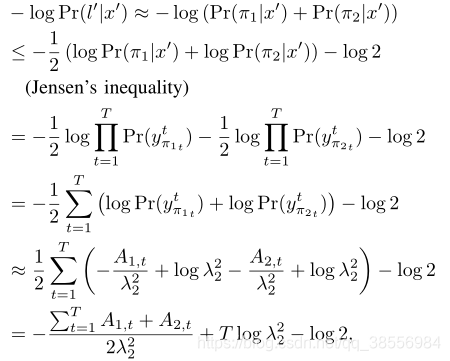
实验
文章首先可视化了如果杜固定参数的话,对抗效果如下图:结果表明,当我们使用较大的λ值(1,10,100)时,它在大多数情况下都不能产生对抗性的例子。对于较小的λ值(0.1,0.01),尽管基本攻击成功地生成对抗图像,但它花费的时间更长,并且带来的扰动幅度更大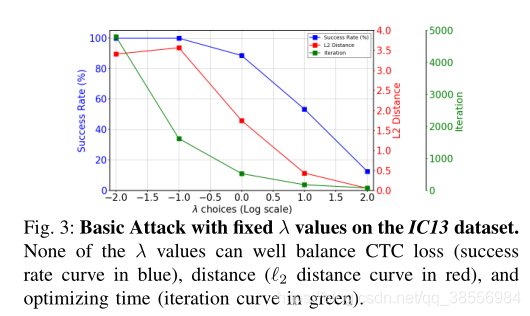
下表给出了实验结果,自适应攻击进行攻击的速度(3∼6×)要比使用改进的二进制搜索的基本攻击快得多
下图给出了攻击的可视化。作者分析了三种常见的针对目标序列标签的对抗性操作:插入、替换和删除。我们在一个数字上执行这些操作,其余的保持不变。我们还包括另一个插入重复数字的操作(例如,“24500”—“245500”)。
Attacking Optical Character Recognition (OCR) Systems with Adversarial Watermarks (AICS2020)主要针对身份证、信件等印刷文本
动机
OCR中采用深度神经网络(DNN)会导致对抗性例子的脆弱性,这些例子是为了误导威胁模型的输出。与普通的彩色图像不同,印刷文本的图像通常具有清晰的背景。然而,现有的大多数对抗性攻击所产生的对抗性例子都是不自然的,严重污染了背景。
CR模型也容易受到对抗性的例子的影响,这些例子是通过对原始图像进行不可察觉的干扰来构建的,目的是误导模型。在真实世界中中广泛采用OCR会给对手带来更多的动机,使他们玩一些技俩,比如伪造身份信息、错误读取度量或指令等。

贡献
我们提出了一种水印攻击方法,利用水印的伪装来产生自然失真,从而避开人眼的检测。实验结果表明,在不同的攻击场景下,水印攻击可以产生一组带有水印的自然对抗实例,并获得与现有攻击方法相似的攻击性能。
论文剖析
作者首先也是分析了在OCR任务中的挑战性。
首先,OCR的输入图像是在背景一尘不染的白纸上。因此,任何由现有攻击增加的干扰对人类读者来说都是显而易见的,以至于会引起怀疑。
其次,如果对手想进行有针对性的攻击,即在句子中将一个字符改为另一个特定的字符(目标),同时产生有语义意义的识别结果,则需要大量明显无法隐藏的干扰
第三,它通常被称为序列标记任务,比图像分类任务更容易受到攻击。仅仅给单个字符添加扰动是不够的。相反,这些扰动需要跨越多个字符。此外,由于OCR模型是端到端的,内部特征表示依赖于附近的字符(上下文)。因此,攻击单个字符的扰动是在给定其上下文的情况下设计的。
们针对现代OCR模型提出了一种新的攻击方法,即水印攻击。人类的眼睛习惯了这些水印而忽略了它们。在本文中,我们生成了自然的水印样式扰动。水印不会妨碍文本的可读性,因此看起来更自然。本文重点研究白盒,有针对性的攻击。
作者提出的模型框架结构如下图所示:
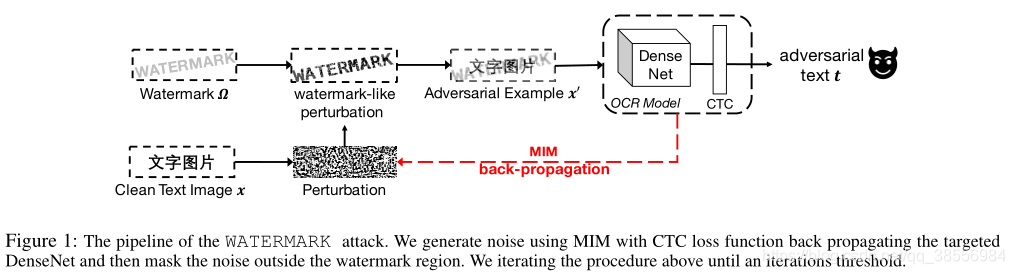
作者提出的水印攻击是基于MIM的水印攻击。优化式子如下:
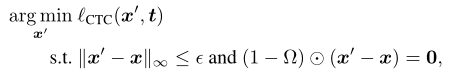
具体的算法如下,作者采用的是基于梯度的攻击:

实验
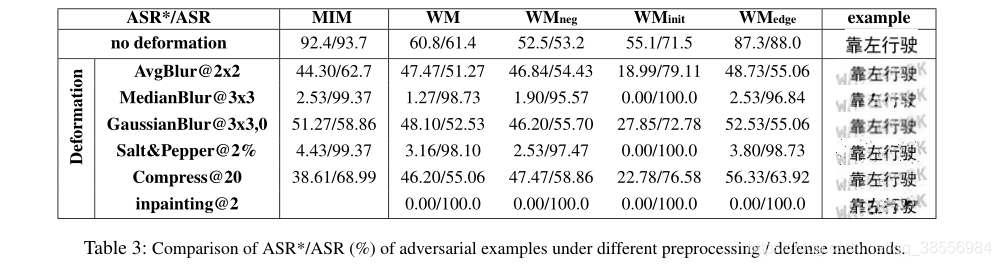
作为评估,作者使用DenseNet+CTC中文神经网络架构对最新的开源OCR模型进行了水印攻击。我们使用的数据集有364万个图像和5989个唯一字符。利用158对原始目标,我们证明了水印攻击可以产生对人眼非常友好的对抗性样本,成功率很高。一些水印对抗性示例甚至以黑盒方式在Tesseract OCR上工作。
最后作者可视化一些样例:
Fooling OCR Systems with Adversarial Text Images(2018)(针对文档的攻击)
动机:
- OCR模型不是基于对单个字符的分类。相反,它们将离散标签序列(对应于整个单词)分配给可变大小的输入。因此,这对对手来说是一个挑战。
- 对输入图像的小扰动通常会导致OCR模型拒绝输入或产生无意义的输出。在我们的案例中,对抗性例子的搜索应该以语言信息为指导,即视觉上相似但语义上相反的一对词。当OCR的目标是识别自然语言文本时,即使是单个词语的错误识别也会对文本的整体意义产生很大的影响。例如,一个对手如果能在模型的输出中实现一个非常小的有针对性的改变,那么用反义词替换一个精心选择的词,就可以完全改变人类理解结果文本的方式。
- OCR系统经常被用作自然语言处理(NLP)的组件。它们的输出被输入到NLP应用程序中,例如文档分类和摘要。因为NLP应用程序对输入中的某些单词高度敏感,所以这会放大敌对示例的影响。
贡献:
我们将展示如何生成单个单词的敌对图像,从而导致Tesseract识别器错误地将其识别为反义词,从而有效地翻转其含义。然后我们将字级攻击扩展到整个文档。利用希拉里·克林顿的电子邮件语料库进行实验,我们展示了如何修改关键数据,包括日期、时间、数字和地址,以及将一些选定的单词更改为它们的反义词,完全改变OCR生成的文本的含义与原始文档中文本的含义。
论文剖析:
整个对抗问题定式如下:
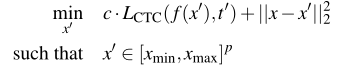
接下来作者使用了变量变化法将上式子更改为:
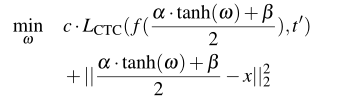
作者提到了筛选对抗样本有两个关键步骤:
**寻找单词对:**一个简单的攻击可以帮助转换文本的意思是用反义词替换关键字。为了为我们的实验创建一个词对列表,我们从WordNet字典[37]中收集了一对反义词,其中一对词中两个词之间的距离低于阈值。在实验中,我们根据单词中的字符数自适应地设置阈值。我们还确保替换的单词与原始单词是同一词性。这确保了攻击不会在OCR模型输出的文本中引入(新的)语法错误。
**语义滤波:**首先,一个英语单词可以有多种含义,因此简单地用它的反义词替换一个单词,许多反义词不符合上下文。例如,将“他们不小心解雇了谷仓”改为“他们不小心雇用了谷仓”。“把这句话变成废话。这个问题可以通过语言建模来解决。对手可以检查转换文本的语言可能性,如果可能性很低,则不进行攻击。在上面的例子中,单词hired the barn应该有较低的分数,因为它在英语中很少见,虽然不是完全没有。检查转换文档的语义平滑度是一项非常重要的任务。如[25]所建议的,可以使用众包来决定转换后的文档是否有意义。
作者生成对抗样本分为下面几个流程:
- 给定文档的原始文本,首先呈现一个干净的图像。然后在文本中找到出现在反义词对列表中的单词(见上文)。
- 找到包含要转换的单词的干净图像的行,对它们进行转换,并且只保留生成有效单词并通过语义过滤的转换(即,不会在生成的文本中产生语义不一致)。
- 然后为这些行图像生成对抗示例,并替换文档图像中相应行的图像。
- OCR模型能够正确识别图像中除修改后的行以外的所有行。对于修改后的行,模型将输出正确的文本,其中一些单词将替换为它们的反义词。
具体的算法流程如下所示:

简单来说,作者采用了贪婪搜索的方式寻找对抗样本。据分数的变化按降序排列所有最佳单词替换。我们首先找到t中每个词w的最佳替换,然后选择替换词w的候选集,使得w与w中每个词之间的编辑距离小于某个阈值 τ \tau τ。编辑距离的限制允许我们在生成敌对文本图像时使用较小的扰动。我们将所有最佳的单词替换按它们在分数中引起的变化降序排列。其目的是识别对改变NLP模型预测最有影响的单词。然后我们贪婪地把 t t t修改成 t ′ t' t′,用最有影响力的词替换它们的最佳替换。
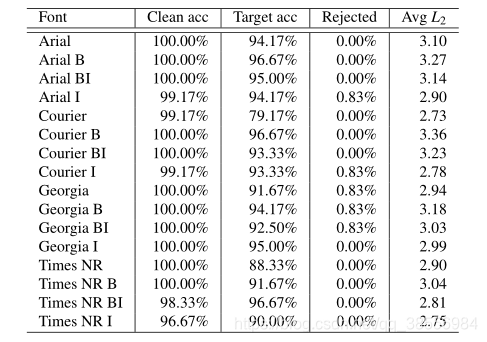
实验结果:
作者首先看了一些不同字体下的攻击效果。
然后作者可视化了一些生成对抗样本的案例。
总结
搜尽文献,目前发现的OCR对抗攻击也就这三篇,并且也没有什么顶会之作,可见这个方向在这个领域没有受到重视。那就从这三篇管中窥豹一下。
如果偏应用和有趣程度来看,第二篇和第三篇都不错,这两个都是白盒有目标的攻击。都是要在预先可用的词典种选取一些反义词,同时保证不会产生令人费解的输出(保证词性一样),在隐私保护以及黑客攻击上会起到一定的作用。
第一篇也是白盒攻击,但是他具体的攻击目标不太明确,可以是插入字母或者减少字母更改字母等等,因为场景文本本身很多字符都是没意义的,另外场景文本背景复杂,也可能比文档(背景白色)好攻击一点,可以如何想想更有趣的进行场景文本的攻击。
这篇关于谈一谈在OCR/场景文本识别中的对抗攻击的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





