ocr专题

使用Python开发一个图像标注与OCR识别工具
《使用Python开发一个图像标注与OCR识别工具》:本文主要介绍一个使用Python开发的工具,允许用户在图像上进行矩形标注,使用OCR对标注区域进行文本识别,并将结果保存为Excel文件,感兴... 目录项目简介1. 图像加载与显示2. 矩形标注3. OCR识别4. 标注的保存与加载5. 裁剪与重置图像

Java使用Tesseract-OCR实战教程
《Java使用Tesseract-OCR实战教程》本文介绍了如何在Java中使用Tesseract-OCR进行文本提取,包括Tesseract-OCR的安装、中文训练库的配置、依赖库的引入以及具体的代... 目录Java使用Tesseract-OCRTesseract-OCR安装配置中文训练库引入依赖代码实
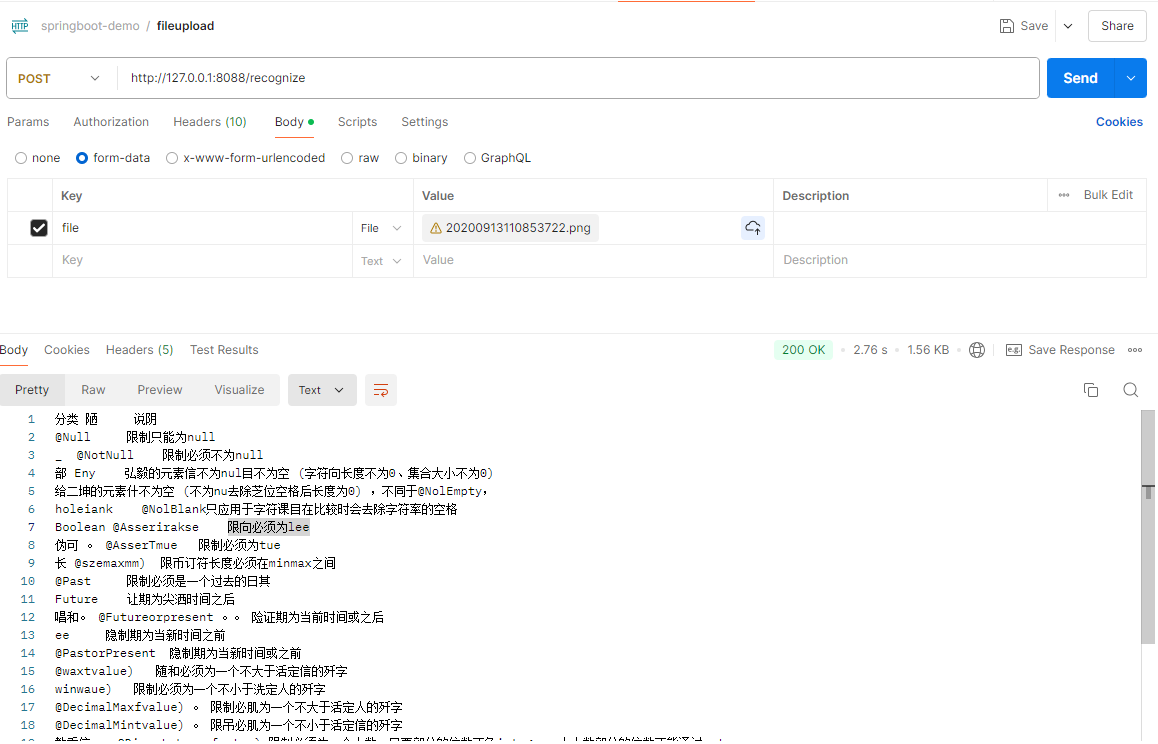
Spring Boot集成Tess4J实现OCR
1.什么是Tess4j? Tesseract是一个开源的光学字符识别(OCR)引擎,它可以将图像中的文字转换为计算机可读的文本。支持多种语言和书面语言,并且可以在命令行中执行。它是一个流行的开源OCR工具,可以在许多不同的操作系统上运行。Tess4J是一个基于Tesseract OCR引擎的Java接口,可以用来识别图像中的文本,说白了,就是封装了它的API,让Java可以直接调用。 Tess
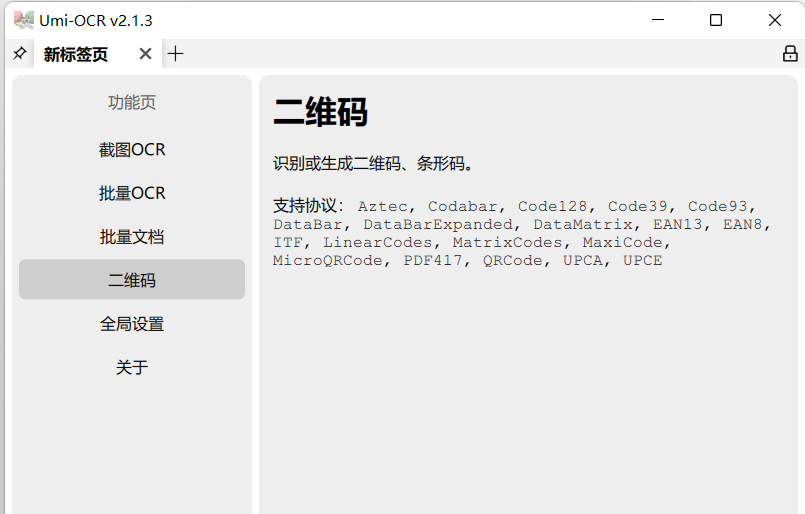
推荐一款强大的OCR软件,请低调使用!
今天给大家分享一款开源的OCR识别软件,可以提升大家的办公效率——Umi-OCR,支持window和Linux系统。 Umi-OCR支持提取一张图片或者多张图片的信息,只需通过右边的功能页选择相应的功能。 点击左边的“截图OCR”进入页面 点击“截图”按钮选取截图区域,直接在右边的记录中提取出截图中的信息。 批量OCR功能也一样,点击左边菜单的“批量OCR”菜单


使用百度飞桨PaddleOCR进行OCR识别
1、代码及文档 代码:https://github.com/PaddlePaddle/PaddleOCR?tab=readme-ov-file 介绍文档:https://paddlepaddle.github.io/PaddleOCR/ppocr/overview.html 2、依赖安装 在使用过程中需要安装库,可以依据代码运行过程中的提示安装。我使用的为python3.7,安装库为:

免费OCR 文字识别工具
免费:本项目所有代码开源,完全免费。 方便:解压即用,离线运行,无需网络。 高效:自带高效率的离线OCR引擎,内置多种语言识别库。 灵活:支持命令行、HTTP接口等外部调用方式。 功能:截图OCR / 批量OCR / PDF识别 / 二维码 / 公式识别 下载地址:https://pan.quark.cn/s/f263ecc221b7

Chainlit结合百度飞浆的ocr识别和nlp自然语言处理做图片文字信息提取
PP飞桨简介 PaddlePaddle(PArallel Distributed Deep LEarning),是由百度公司开发的一款开源深度学习平台,支持动态和静态图模式,提供了从模型构建到训练、预测等一系列的功能。PaddlePaddle 的设计目标是让开发者能够更容易地实现、训练和部署自己的深度学习模型。它支持多种操作系统,并提供了多种编程接口,包括 Python 和 C++。 Pad

基于tesseract实现文档OCR识别
导入环境 导入必要的库 numpy: 用于处理数值计算。 argparse: 用于处理命令行参数。 cv2: OpenCV库,用于图像处理。 import numpy as npimport argparseimport cv2 设置命令行参数 ap = argparse.ArgumentParser()ap.add_argument("-i", "--image", defaul

C++发票查验-发票验真-发票真伪查验-发票ocr识别-数电票真伪-接口
发票查验接口,是指通过特定的技术手段和服务平台,对发票的真伪进行验证和识别的一项服务。在现代商业活动中,发票作为一种重要的财务和法律凭证,其真实性对于维护税务秩序和防范财务风险至关重要。 随着技术的进步,人工智能和OCR(光学字符识别)技术也被应用于发票查验之中。通过OCR技术,可以自动识别发票上的文本信息,包括发票号码、代码、金额等关键信息,并自动完成查验。这种技术不仅提高了查验效率


开源通用验证码识别OCR —— DdddOcr 源码赏析(二)
文章目录 前言DdddOcr分类识别调用识别功能classification 函数源码classification 函数源码解读1. 分类功能不支持目标检测2. 转换为Image对象3. 根据模型配置调整图片尺寸和色彩模式4. 图像数据转换为浮点数据并归一化5. 图像数据预处理6. 运行模型,返回预测结果 总结 前言 DdddOcr 源码赏析 上文我们读到了分类识别部分的源

lstm+ctc 实现ocr识别
转载地址: https://zhuanlan.zhihu.com/p/21344595 OCR是一个古老的研究领域,简单说就是把图片上的文字转化为文本的过程。在最近几年随着大数据的发展,广大爬虫工程师在对抗验证码时也得用上OCR。所以,这篇文章主要说的OCR其实就是图片验证码的识别。OCR并不是我的研究方向,我研究这个问题是因为OCR是一个可以同时用CNN,RNN两种算法都可以很好解决的

java实现ocr功能(Tesseract OCR)
1、pom文件中引入依赖 <dependency><groupId>net.sourceforge.tess4j</groupId><artifactId>tess4j</artifactId><version>4.5.4</version></dependency> 2、下载语言库文件(不要放到resources下,可以放到项目所在目录下,在博主的主页资源菜单下可下载,也可自行在网上找资源

两行代码搞定python OCR图像文字识别
目前OCR主要依赖几个低层库,本博客采用Tesseract,Tesseract是由Google维护的开源OCR。本博客在windows环境进行,linux环境同理。 1、安装Tesseract: windows下Tesseract的安装比较简单,下载exe然后一直next下去就行了。但是由于要做中文的识别,所以一定在安装的时候要勾选相应的中文库,这个安装时是默认不下载的。 2、安装p
【深度学习】OCR,CLIP4STR论文,多模态OCR
CLIP4STR:基于预训练视觉语言模型的简单场景文本识别基线 CLIP4STR:基于预训练视觉语言模型的简单场景文本识别基线 摘要 预训练的视觉语言模型(VLMs)已成为各种下游任务的基础模型。然而,场景文本识别(STR)方法仍然倾向于依赖仅在单一模态(视觉模态)上预训练的骨干网络,尽管VLMs具有成为强大场景文本识别器的潜力。例如,CLIP可以稳健地识别图像中的常规(水平)和非规则(旋转
【深度学习】OCR,TrOCR,transformer 端对端,论文
TrOCR: 基于Transformer的光学字符识别,使用预训练模型 摘要 文本识别是文档数字化领域中的一个长期存在的研究问题。现有的方法通常基于用于图像理解的CNN和用于字符级文本生成的RNN。此外,通常还需要另一个语言模型作为后处理步骤来提高整体准确性。在本文中,我们提出了一种端到端的文本识别方法,名为TrOCR,它使用预训练的图像Transformer和文本Transformer模型,
【深度学习】OCR模型的现状,厉害的OCR模型一览,OCR模型排行榜
文章目录 一些模型介绍1. **SwinOCR**2. **Donut (Document Understanding Transformer)**3. **MGP-STR (Multi-Grained Prediction for Scene Text Recognition)**4. **PARSeq (Parallel Sequential Text Recognition)**5.
Umi-OCR 文字识别工具
免费开源的离线orc识别功能 git地址 感谢大佬的贡献 Umi-OCR 文字识别工具 使用说明 • 下载地址 • 更新日志 • 提交Bug 免费,开源,可批量的离线OCR软件 适用于 Windows7 x64 、Linux x64 免费:本项目所有代码开源,完全免费。方便:解
Oracle RAC ocr进行备份和恢复的一次错误操作(没关闭所有节点)
在看张晓明大师的《大话RAC》OCR命令部分的时候,由于自己眼拙,不细心的缘故,所有两个节点中,我只关闭了其中一个,就进行export,还有dd裸设备,所以备份恢复出现了错误!!深刻教训,后来成功恢复了,所以记录之。此记录不是规范的OCR备份恢复操作,规范的请详见张大师的《大话RAC》著作。 redhat 5.5 +oracle 10.2.0.1.0 错误如下提示: [ro
JavaScript数电票识别查验接口、增值税发票识别OCR、医疗票识别查验
支持全国增值税专用发票、普通发票、电子发票、数电票、卷式发票、机票行程单、火车票、打车票、定额发票、非税收入统一票据、医疗收费票据、机动车销售统一发票等多种发票全票面信息的快速提取、录入 支持一图多票识别,支持发票的自动分类,减少手动录入的时间和人力成本,避免人工录入误差,提升财务数据准确率与工作效率 提供标准化接口,便于与企业现有的ERP、会计软件或其它财务管理系统无缝集成,助力

AI文本转语音:Toucan TTS 支持 7000 多种语言的语音合成工具箱,突破性 OCR 技术:支持多种语言识别,媲美顶级云服务
AI文本转语音:Toucan TTS 支持 7000 多种语言的语音合成工具箱,突破性 OCR 技术:支持多种语言识别,媲美顶级云服务。 AI文本转语音:Toucan TTS 支持 7000 多种语言的语音合成工具箱 Toucan TTS是由德国斯图加特大学自然语言处理研究所(MS)精心打造的文本转语音(TTS)工具箱,它支持超过7000种语言,包括多样的方言和语言变体。这款工具箱建立在P
OCR文字识别在UI自动化上的运用
用了Airtest的图像识别后发现在一些文字的识别上有些不准确,猜测可能是特征值比较低吧,容易匹配错。 在论坛上也看到过有人用OCR的方式,记不得是哪个帖子了,用的是腾讯云的接口吧。 按这个思路尝试了一下,腾讯云的接口有次数限制,我找了讯飞的接口,完全免费,也能用 原理很简单,给这个接口上传一张图片,后台处理生成识别出来的文字以及位置坐标。 有几个云平台提供了OCR的接口,腾讯云超过一定次

开源的Umi-OCR 文字识别工具
开源的Umi-OCR 文字识别工具:OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。 可以将图片PDF识别文字,并可以保存为双层可搜索文档的PDF格式(与原PDF还是基本一致的)。
【深度学习】OCR, 如何使用 Tesseract 进行 OCR 识别
以下是一篇关于如何使用 Tesseract OCR 的中文博客,涵盖了基本的命令行使用方法和一些常见的选项。 如何使用 Tesseract 进行 OCR 识别 介绍 Tesseract 是一个强大的开源 OCR(光学字符识别)引擎,支持多种语言和字符集。它的命令行工具可以将图像中的文本提取为文本文件,广泛应用于文档数字化、数据提取等场景。 安装 Tesseract 在使用 Tessera