本文主要是介绍Stable Diffusion 绘画入门教程(webui)-ControlNet(Seg),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上篇文章介绍了深度Depth,这篇文章介绍下seg(Segmentation)
意思为语义分割, 通俗理解就是把图中的不同物体元素按类别不同,标为不同的颜色,不同的颜色代表不同的元素类别,如下图,左边为原图,右边就是语义分割后的预览图(还是拿之前的房子举例):

那么有什么玩法呢,如下图,我们可以保持图中物体类型不变,完全给他换一种风格:

详细步骤,和前几篇类似,不再赘述:
一、选大模型
我这里用的大模型是"anything-v5-PrtRE.safetensors",选用不同模型生成效果会有区别,可以自己找喜欢的风格的大模型使用

二、写提示词
我这里主要写了一些画质要求,可以根据自己喜好,寻找合适的大模型或者lora来进行控制风格哦。

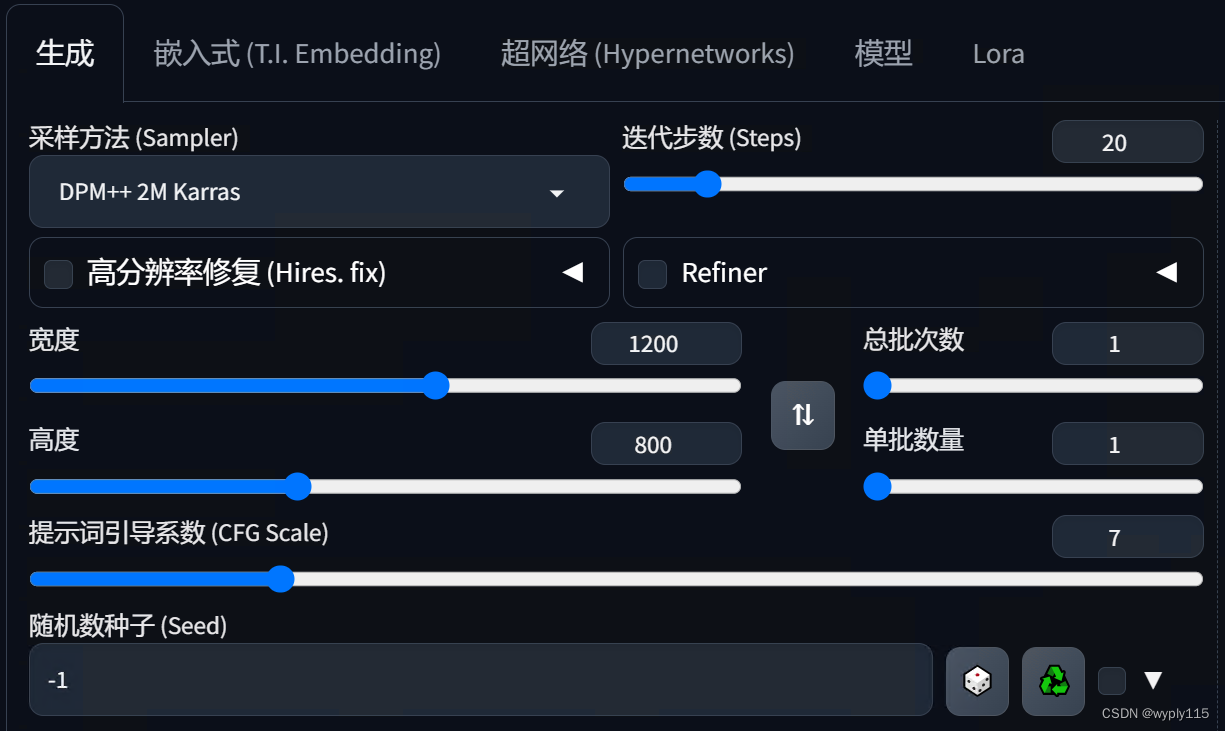
三、基础参数设置
基础参数设置还是和上篇文章一样,除了长宽,其他我都默认的,这里大家可以自行调试。
长宽可以通过ControlNet中的那个回传按钮回传过来,不用手动填写哦。
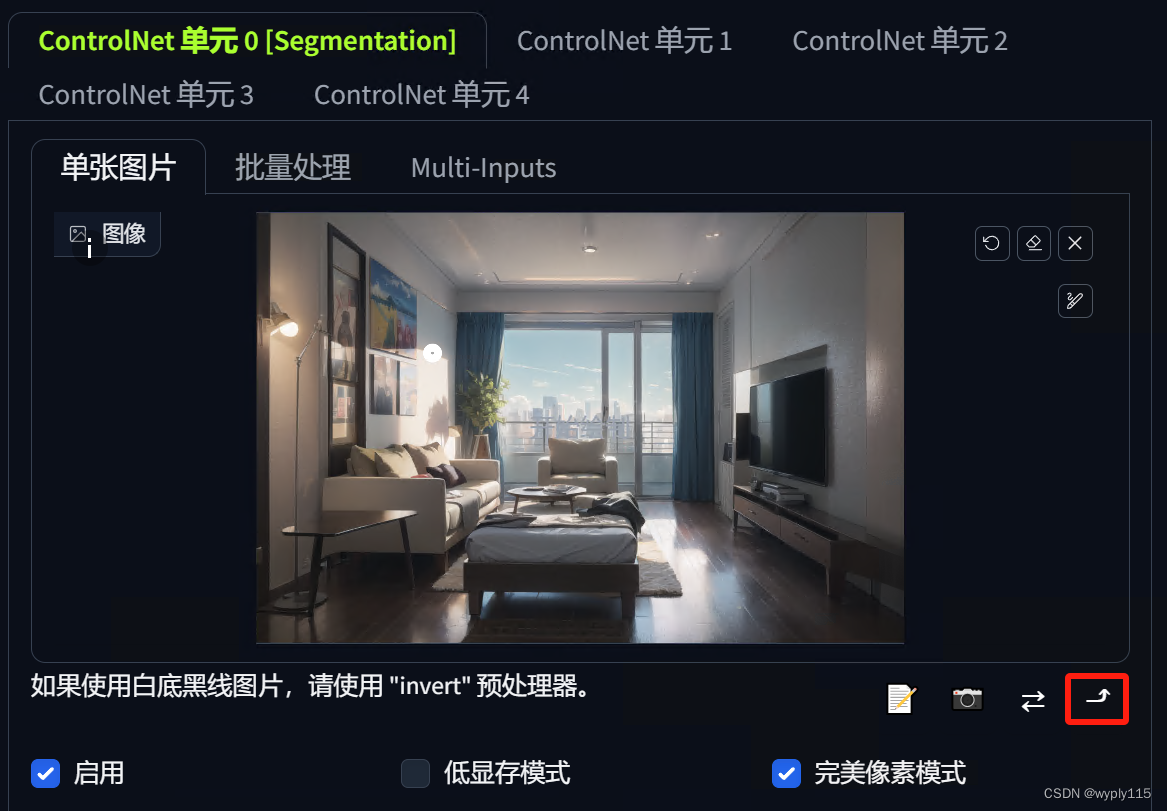
四、启用ControlNet
到这里,大家应该比较熟了,我就直接上图了,选择Segmentation(语义分割)后模型和预处理器会自动加载,预处理器有四种,我一般都默认足够用,感兴趣可以都尝试下,功能一样只是生成出的图会有些差异:

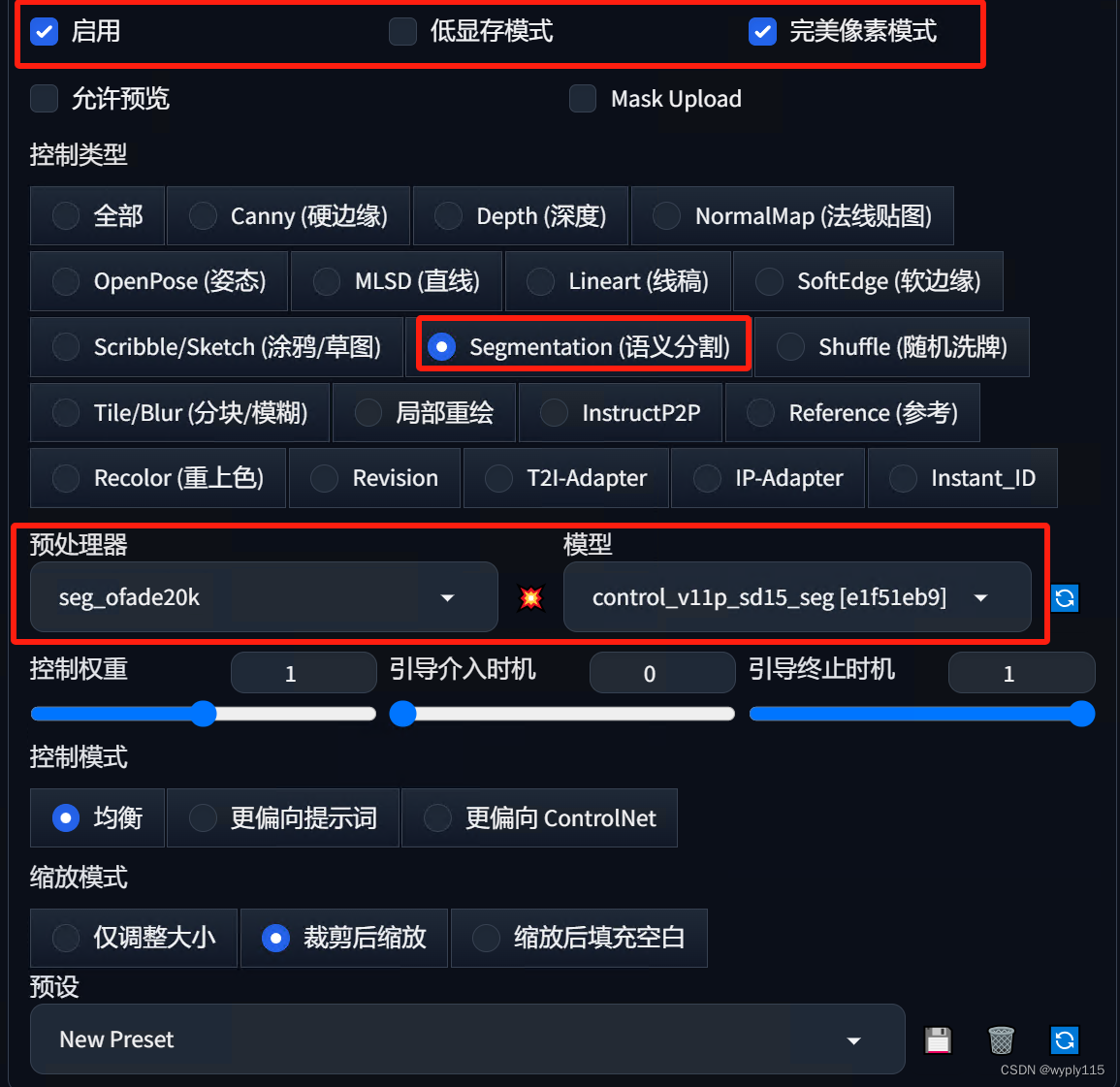
点击生成就可以了:

五、颜色-含义
参考 ControlNet中分享的下载内容 中有一个大神分享的pdf,里边列了不同颜色代表的不同含义,我这里只截图部分示意,详细参考大神分享的内容

有了这个颜色代表啥内容,可以在语义分割图中,手动绘制想要的内容,比如在房子中添加一个人,人的颜色是#96053d,那么用这个颜色的画笔手动绘制一个人像到房屋的场景中,最后可以在场景中添加上人像,当然添加其他内容也是可以的,颜色对照就好,这样的话控制性就会强很多啦,大家自己去试试吧。
这篇关于Stable Diffusion 绘画入门教程(webui)-ControlNet(Seg)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









