webui专题

本地搭建DeepSeek-R1、WebUI的完整过程及访问
《本地搭建DeepSeek-R1、WebUI的完整过程及访问》:本文主要介绍本地搭建DeepSeek-R1、WebUI的完整过程及访问的相关资料,DeepSeek-R1是一个开源的人工智能平台,主... 目录背景 搭建准备基础概念搭建过程访问对话测试总结背景 最近几年,人工智能技术

Ollama整合open-webui的步骤及访问
《Ollama整合open-webui的步骤及访问》:本文主要介绍如何通过源码方式安装OpenWebUI,并详细说明了安装步骤、环境要求以及第一次使用时的账号注册和模型选择过程,需要的朋友可以参考... 目录安装环境要求步骤访问选择PjrIUE模型开始对话总结 安装官方安装地址:https://docs.

Retrieval-based-Voice-Conversion-WebUI模型构建指南
一、模型介绍 Retrieval-based-Voice-Conversion-WebUI(简称 RVC)模型是一个基于 VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)的简单易用的语音转换框架。 具有以下特点 简单易用:RVC 模型通过简单易用的网页界面,使得用户无需深入了

如何在算家云搭建模型Stable-diffusion-webUI(AI绘画)
一、Stable Diffusion WebUI简介 Stable Diffusion WebUI 是一个网页版的 AI 绘画工具,基于强大的绘画模型Stable Diffusion ,可以实现文生图、图生图等。 二、模型搭建流程 1.选择主机和镜像 (1)进入算家云的“应用社区”,点击搜索或者找到"stable-diffusion-webui,进入详情页后,点击“创建应用”

【Prometheus】Prometheus安装部署流程详解,配置参数webUI使用方法解析说明
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,阿里云开发者社区专家博主,CSDN全栈领域优质创作者,掘金优秀博主,51CTO博客专家等。 🏆《博客》:Python全栈,前后端开发,小程序开发,人工智能,js逆向,App逆向,网络系统安全,数据分析,Django,fastapi
Windows安装docker,启动ollama运行open-webui使用AIGC大模型写周杰伦歌词
Windows安装docker,启动ollama运行open-webui使用AIGC大模型写周杰伦歌词 1、下载docker的Windows版本。 docker下载地址: https://docs.docker.com/desktop/install/windows-install/https://docs.docker.com/desktop/install/windows-insta
【AI 绘画】更快?更省显存?支持 FLUX?使用绘世启动器安装 SD WebUI Forge
使用绘世启动器安装 SD WebUI Forge 下载绘世启动器 绘世启动器下载地址1:https://gitee.com/licyk/term-sd/releases/download/archive/hanamizuki.exe 绘世启动器下载地址2:https://www.bilibili.com/video/BV1ne4y1V7QU 新建一个文件夹取名sd-webui-
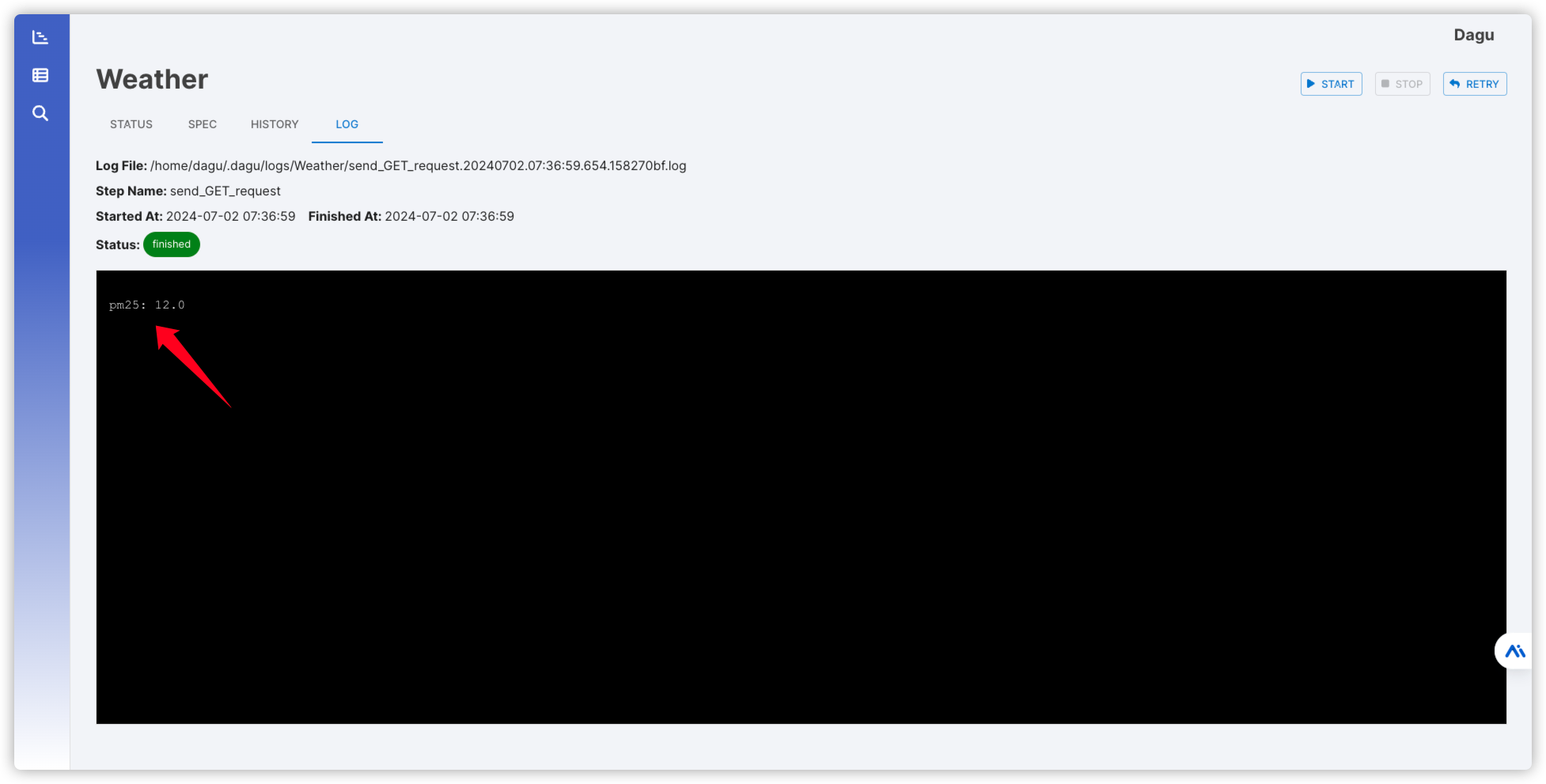
带有WebUI的cron替代品Dagu
什么是 Dagu ? Dagu 是一个强大的 Cron 替代品,它带有一个 Web UI。它允许你将命令之间的依赖关系定义为有向无环图(DAG),使用声明式的 YAML 格式。Dagu 的设计易于使用、自包含且无需编码,非常适合小型项目。 安装 在群晖上以 Docker 方式安装。因为镜像发布在 ghcr.io ,所以采用命令行方式安装 需要用 SSH 客户端登录到群晖后再

使用Aqua进行WebUI测试(Pytest)——介绍篇
一、在创建时选择Selenium with Pytest 如果选择的是Selenium,则只能选择Java类语言 选择selenium with Pytest,则可以选择Python类语言 Environment 其中的【Environment】可选New 和 Existing New :选择这个选项意味着你希望工具为你创建一个新的开发环境。这通常涉及到安装所需的依赖项和配置文件,确

spark运维监控:查看历史作业的webUI
1、停止集群 2、配置spark-env.sh export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=50 -Dspark.history.fs.logDirectory=hdfs://centos-5:9001/spark-event" 3、重启集群 4、启

Hadoop,Zookeeper,Hbase,Hive,Spark,Kafka,CDH中webui常用端口
Hadoop: 50070:HDFS WEB UI端口 8020 : 高可用的HDFS RPC端口 9000 : 非高可用的HDFS RPC端口 8088 : Yarn 的WEB UI 接口 8485 : JournalNode 的RPC端口 8019 : ZKFC端口 Zookeeper: 2181 : 客户端连接zookeeper的端口 2888 : zookeeper集群内
![[AI]从零开始的so-vits-svc webui部署教程(小白向)](https://i-blog.csdnimg.cn/direct/a50225e1883342acada23cbb1a401d9b.png)
[AI]从零开始的so-vits-svc webui部署教程(小白向)
一、本次教程是给谁的? 如果你点进了这篇教程,相信你已经知道so-vits-svc是什么了,那么我们这里就不过多讲述了。如果你还不知道so-vits-svc能做什么,可以去b站搜索一下,你大概率会搜索到一些AI合成的音乐,是的简单来讲,so-vits-svc是一个训练并且推理声音的开源项目。它能够模仿某些角色的声音来唱歌或者单纯的文字朗读。那么,我们回到正题,本次教程是给谁的?如

stable-diffusion-webui 部署 ,启用 api 服务
stable-diffusion-webui 部署 ,启用 api 服务 api 文档参考 https://profaneservitor.github.io/sdwui-docs/api/ api 源码路径是 stable-diffusion-webui/modules/api/api.py 我系统是 ubuntu22.04 conda 环境torchpgu , python 是 3.11

Win11 本地部署大模型 WebUI + ComfyUI
Open WebUI 是一个可扩展、功能丰富且用户友好的自托管 Web 用户界面(WebUI),它被设计用于完全离线操作。该项目最初被称为 Ollama WebUI,后来更名为 Open WebUI。Open WebUI 的主要目的是为本地的大语言模型(LLMs)提供一个图形化的交互界面,使得用户能够更加方便地调试和调用本地模型,它不仅支持本地模型,还兼容 Ollama 和 OpenAI 的 AP

ubuntu下open-webui + ollama本地大模型部署
文章目录 nvidia gpu驱动安装安装卸载 ollama 部署添加docker秘钥docker配置添加国内镜像源ollama安装从源拉取ollama镜像。启动一个ollama容器 通过ollama下载模型到本地检验本地模型 open-webui 部署安装容器和镜像下载webui使用查看模型运行时内存、cpu、gpu占用 业余兴趣,部署下最近很火的LLM大模型玩玩,现在市面
comfyUI和SD webUI都有哪些差别呢?
ComfyUI和SD WebUI都是用于AI绘画的用户界面,它们各自有着不同的特点和适用场景。以下是两者之间的一些关键差别: 1、用户体验与界面友好性: SD WebUI(Stable Diffusion Web User Interface)以其直观易用著称,特别受初学者欢迎。它的界面布局清晰,功能模块一目了然,用户可以很容易地找到所需的功能,降低了使用难度。ComfyUI虽然
ComfyUI 和 WebUI
概述 ComfyUI:像拼积木一样,你可以用各种“模块”搭建出一个复杂的图像生成“机器”。适合那些喜欢自己动手折腾、希望精确控制每个步骤的人。WebUI:更像是一个智能“图像生成器”,你只需要输入文字描述,它就能生成图片。适合那些想快速得到结果,不想研究复杂流程的人。 ComfyUI ComfyUI 是一个非常灵活的图像生成工具。你可以想象它是一个“搭积木”的系统,你把不同的功能模块(比如颜
stable diffusion webui电商基础模型
电商生成模型的产生主要有两个路子,1.训练微调;2.模型融合。 下面这些是借鉴,帮助思考如何构建电商模型。 电商必备的10款Stable diffusion WebUI 模型 - 知乎一、WFProduct 电商场景这是一个专门为电商摄影场景训练的 lora 模型,可以生成各种极具设计感的场景图,效果逼真,无论是电商、海报、产品渲染还是空间布置上都能用得到,可以解决产品摄影空间布景困难、创意度不

Ollama部署大模型并安装WebUi
Ollama用于在本地运行和部署大型语言模型(LLMs)的工具,可以非常方便的部署本地大模型 安装 Linux curl -fsSL https://ollama.com/install.sh | sh 我是ubuntu系统安装,其他系统可以看项目的开源地址有写 GitHub - ollama/ollama: Get up and running with Llama 3, Mist

Ollama(docker)+ Open Webui(docker)+Comfyui
Windows 系统可以安装docker desktop 相对比较好用一点,其他的应该也可以 比如rancher desktop podman desktop 安装需要windows WSL 安装ollama docker docker run -d --gpus=all -v D:\ollama:/root/.ollama -p 11434:11434 --name ollama ol
【深度学习】stable-diffusion-webui AUTOMATIC1111 的参数解释翻译
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Command-Line-Arguments-and-Settings 参数命令值默认值描述-h, --helpNoneFalse显示帮助信息并退出–exit安装后终止–data-dirDATA_DIR./存储所有用户数据的基本路径–configCONFIGconfigs/s
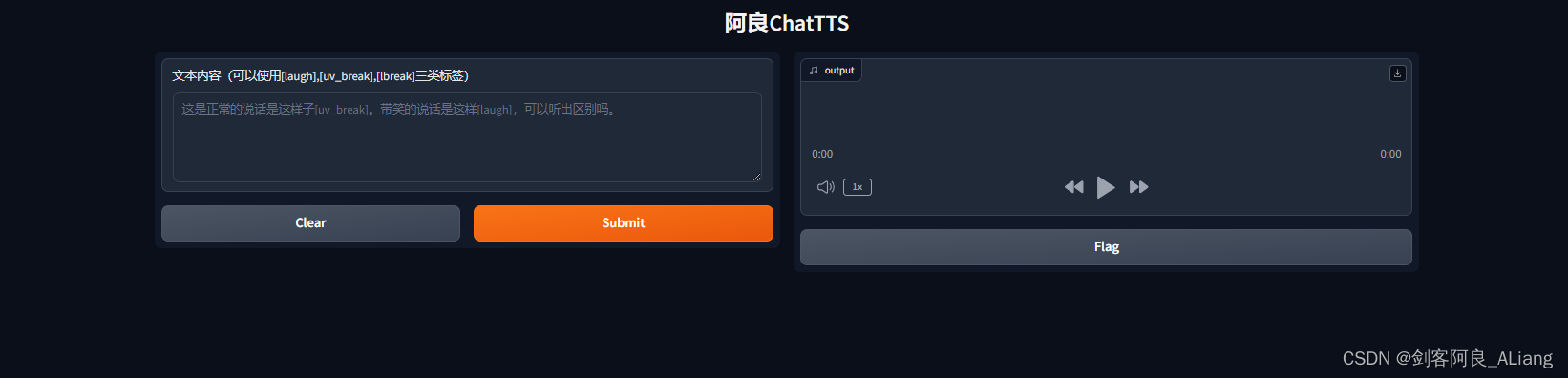
ChatTTS-WebUI测试页面项目
概述 分享可以一个专门为对话场景设计的文本转语音模型ChatTTS,例如LLM助手对话任务。它支持英文和中文两种语言。最大的模型使用了10万小时以上的中英文数据进行训练。在HuggingFace中开源的版本为4万小时训练且未SFT的版本. 该模型能够预测和控制细粒度的韵律特征,包括笑声、停顿和插入词等。标签有[laugh]和[uv_break], [lbreak]。在韵律上也有很好的表现。

Ollama+Open WebUI本地部署Llama3 8b(附踩坑细节)
先展示一下最终结果,如下图所示: 1. 添加环境变量 在下载 ollama 之前,先去配置环境变量,确保模型下载到我们想要的地方 win10 和 win11 输入path或者环境变量: 增加系统环境变量 变量名不可更改,必须是OLLAMA_MODELS,变量值可以自定义, 2. 下载ollama 下载网址:Download Ollama on macOS 下

Qwen2 阿里最强开源大模型(Qwen2-7B)本地部署、API调用和WebUI对话机器人
阿里巴巴通义千问团队发布了Qwen2系列开源模型,该系列模型包括5个尺寸的预训练和指令微调模型:Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B以及Qwen2-72B。对比当前最优的开源模型,Qwen2-72B在包括自然语言理解、知识、代码、数学及多语言等多项能力上均显著超越当前领先的Llama3-70B等大模型。 老牛同学今天部署和体验Qwen2-
![[2024-06]-[大模型]-[DEBUG]- ollama webui 11434 connection refused](https://img-blog.csdnimg.cn/direct/b3e2eea302d64b04a52afde4f26d32c2.png)
[2024-06]-[大模型]-[DEBUG]- ollama webui 11434 connection refused
报错:host.docker.internal:11434 ssl:default [Connection refused] 将/etc/systemd/system/ollama.service中加上如下红框两行 Environment="OLLAMA_HOST=0.0.0.0"Environment="OLLAMA_ORIGINS=*" 然后 systemctl daemon