本文主要是介绍【 YOLOv5】目标检测 YOLOv5 开源代码项目调试与讲解实战(4)-自制数据集及训练(使用makesense标注数据集),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如何制作和训练自己的数据集
- 看yolov5官网
- 创建数据集
- 1.搜索需要的图片
- 2.创建标签
- 标注数据集地址:
- 放入图片后选择目标检测
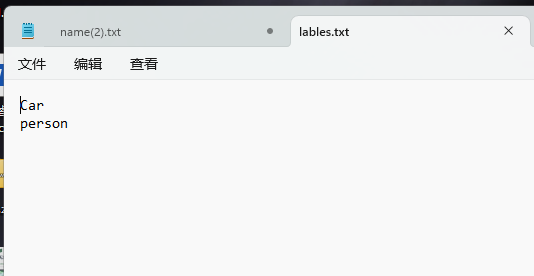
- 创建文档,每个标签写在单独的一行
- 上传结果
- 此处可以编辑类别
- 把车框选选择类别即可
- 导出数据
- 3.新建一个目录放数据
- 写yaml文件
- 4. 测试训练效果
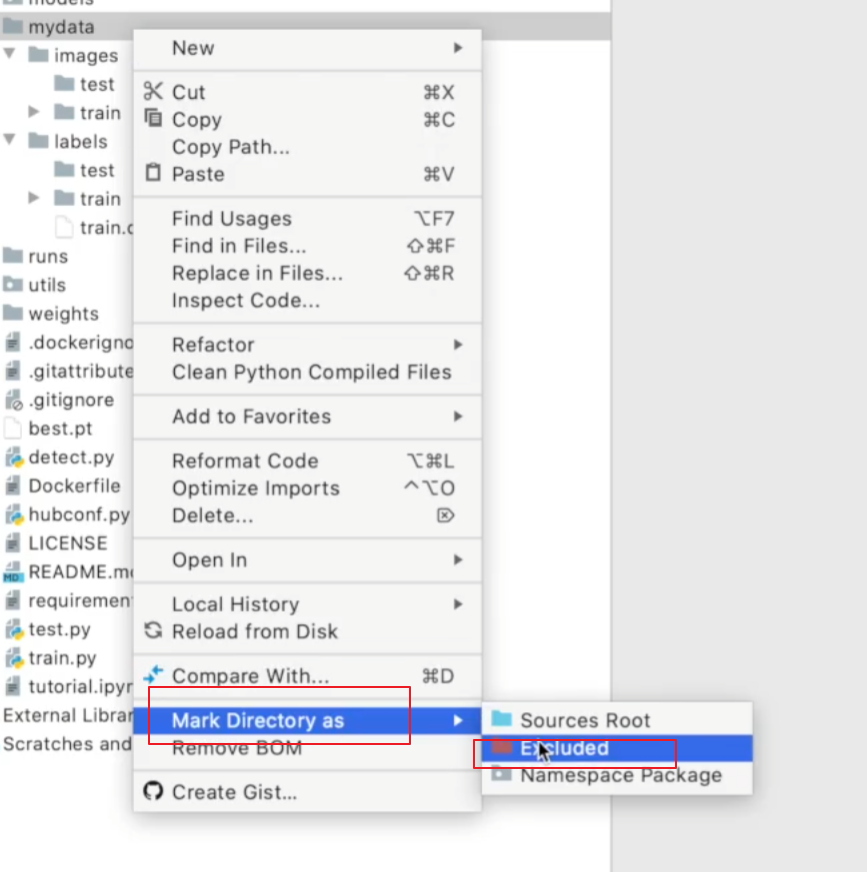
- 防止pychram检索数据集的方法
看yolov5官网
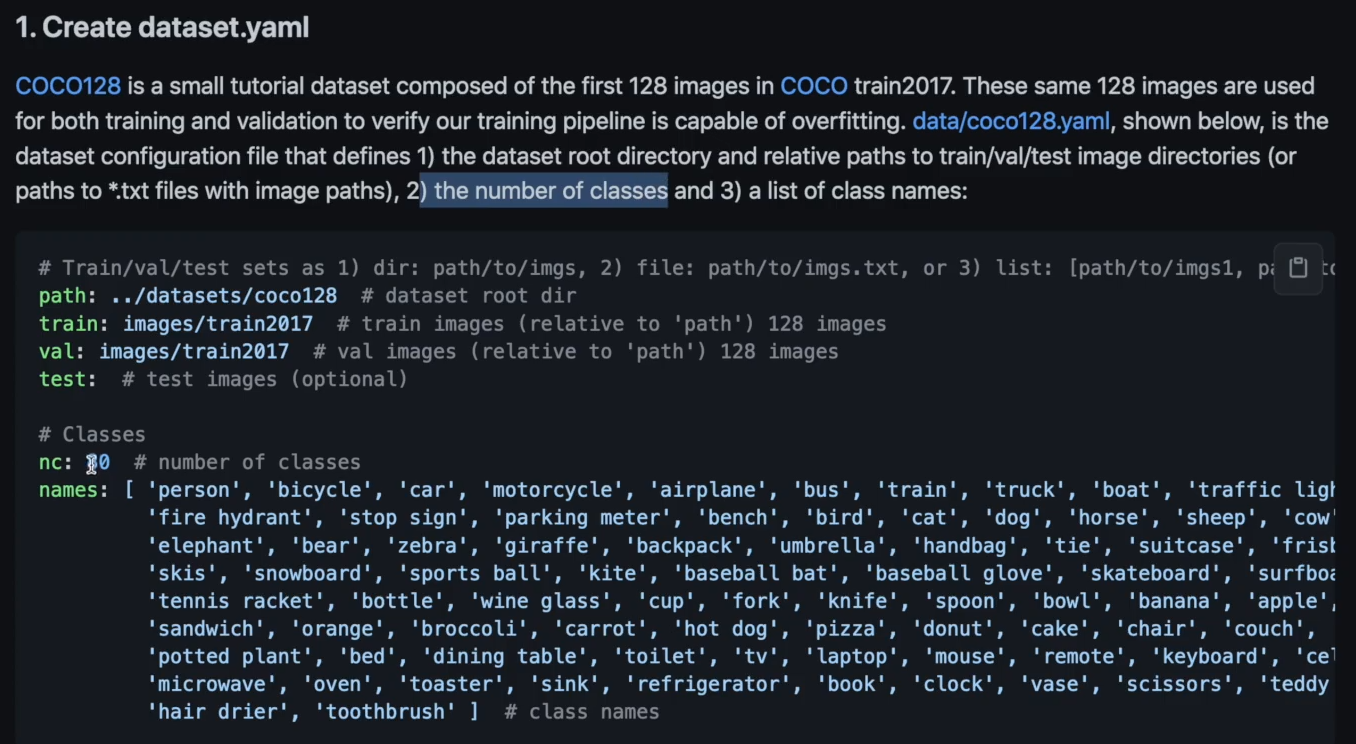
首先是创建.yaml数据集
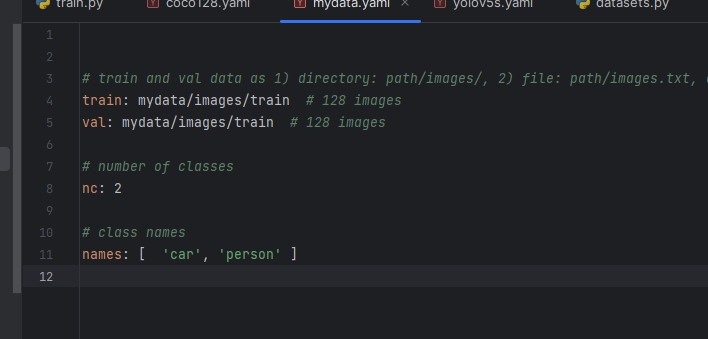
1)首先指明数据集的根目录在哪里,训练集,验证集,测试集他们文件夹的相对路径
2)指定训练中有多少个类
3)指定这些类代表什么含义
创建数据集
1.搜索需要的图片
这里名字最好保存为英文,保存在data下面
2.创建标签
标注数据集地址:
https://www.makesense.ai/

放入图片后选择目标检测
创建文档,每个标签写在单独的一行
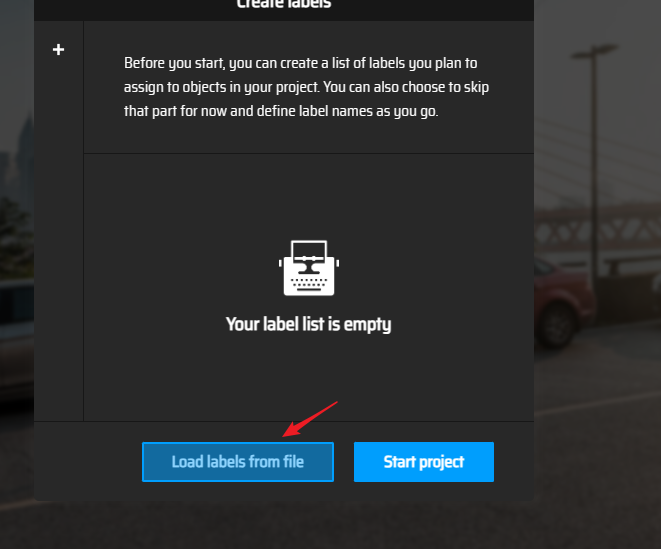
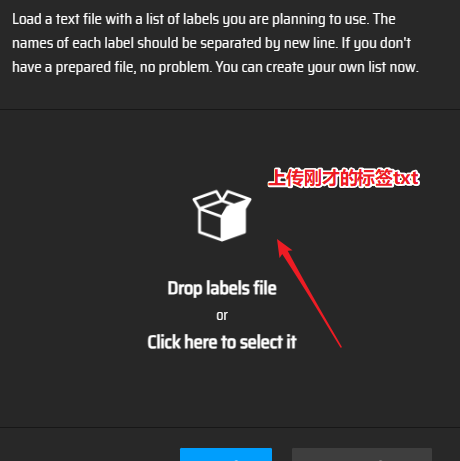
上传结果
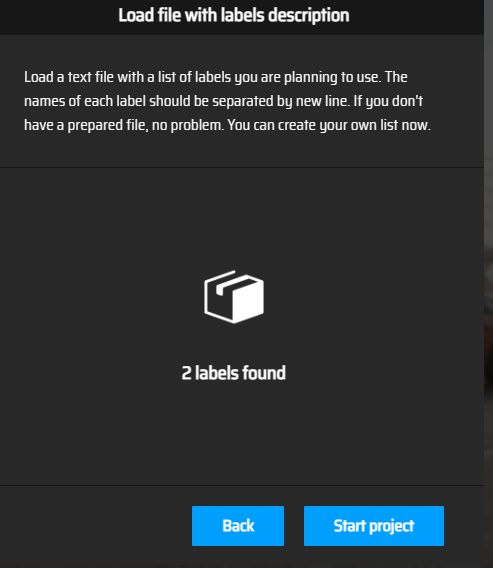
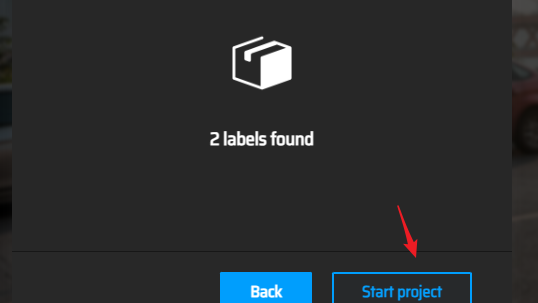
此处可以编辑类别

从上往下依次是
标签列表
导入图片
导入标注
导出标注
用训练好的检测
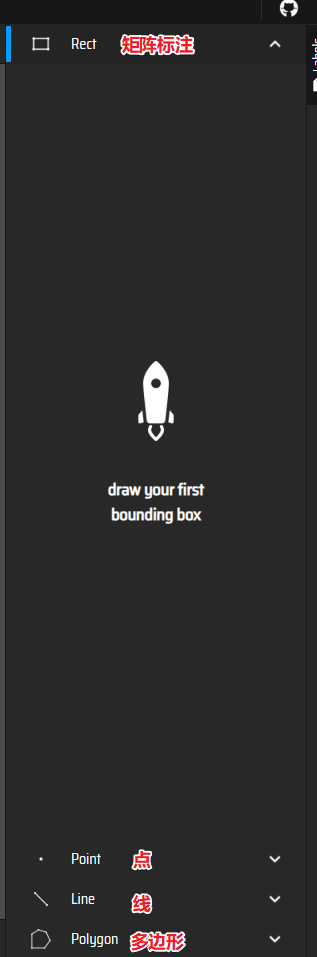
一般用矩阵标注
把车框选选择类别即可

导出数据
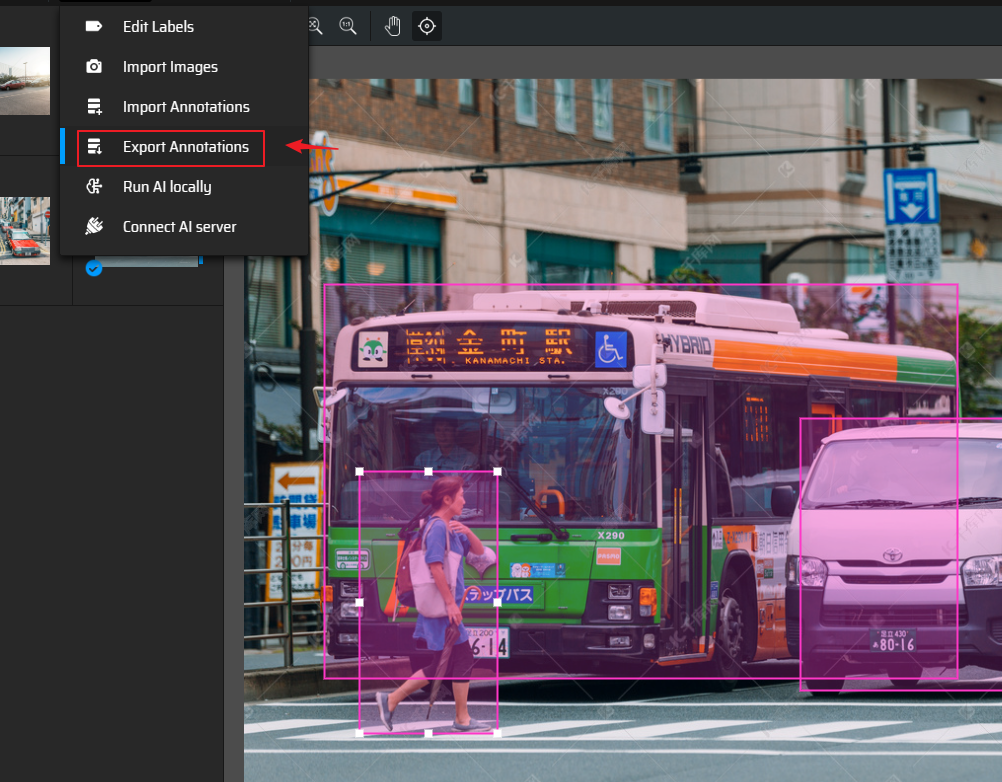

需要归一化

3.新建一个目录放数据
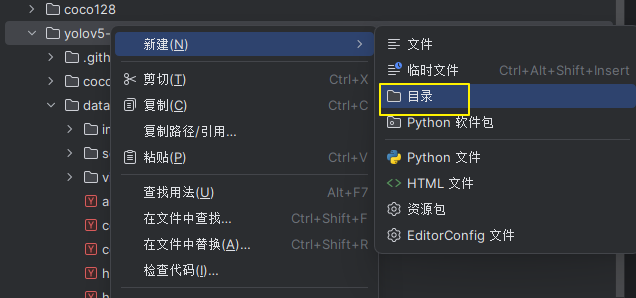
继续在该目录下新建
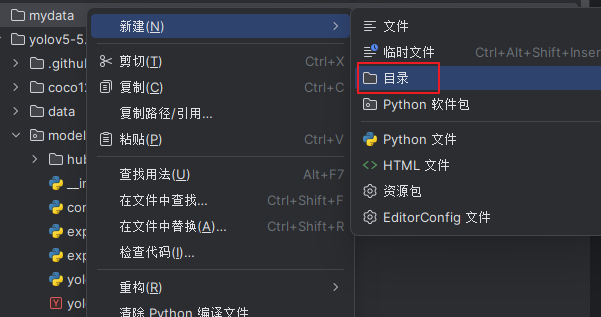
新建目录如图
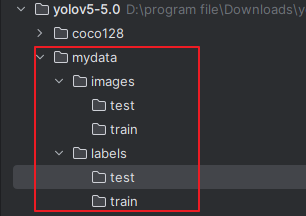
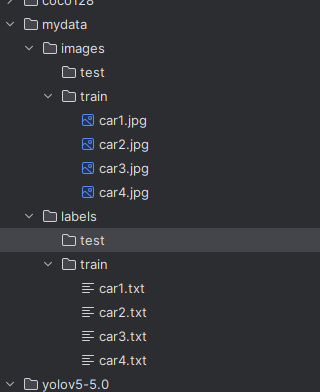
把图片和标注的数据放入
写yaml文件
直接复制一个,并命名为mydata
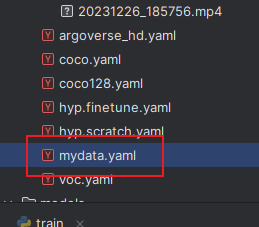
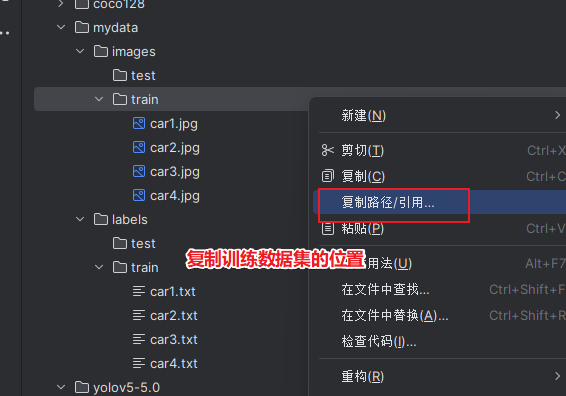
更改如图
更改train.py里的数据集路径

开始训练

4. 测试训练效果
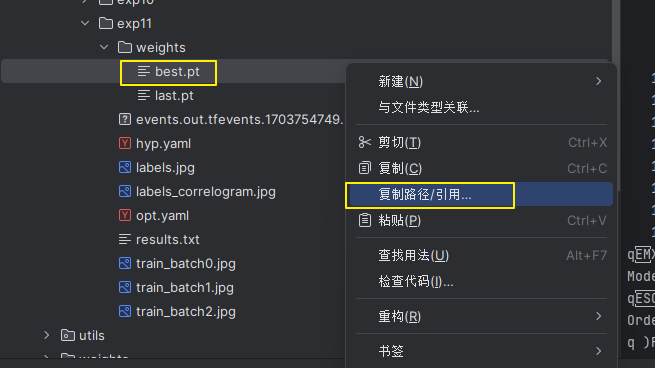
拷贝到 detect.py
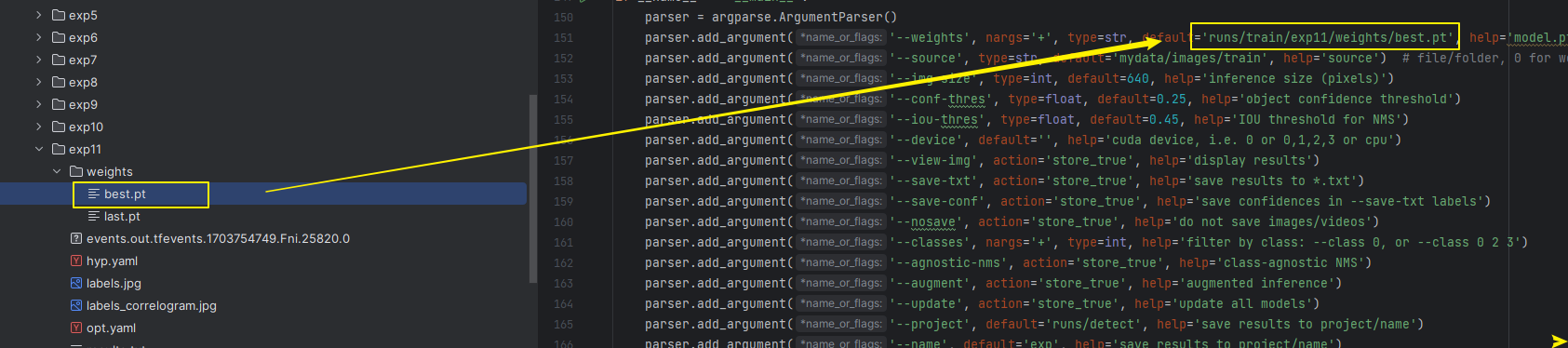

更改后

点击运行
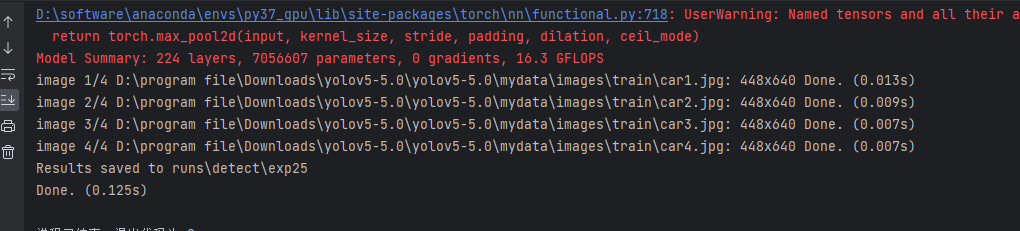
防止pychram检索数据集的方法
这篇关于【 YOLOv5】目标检测 YOLOv5 开源代码项目调试与讲解实战(4)-自制数据集及训练(使用makesense标注数据集)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



