本文主要是介绍【kubernetes】二进制部署k8s集群之cni网络插件flannel和calico工作原理(中),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
↑↑↑↑接上一篇继续部署↑↑↑↑
目录
一、k8s集群的三种接口
二、k8s的三种网络模式
1、pod内容器之间的通信
2、同一个node节点中pod之间通信
3、不同的node节点的pod之间通信
Overlay Network
VXLAN
三、flannel网络插件
1、flannel插件模式之UDP模式(8285端口)
2、flannel插件模式之VXLAN模式
3、总结flannel插件的三大模式
4、拓展:关于vlan和vxlan的区别
四、calico网络插件
1、calico插件模式之IPIP模式
2、calico插件模式之BGP模式
3、总结calico插件三大模式
五、对比flannel和calico的区别
六、在所有node节点部署cni网络插件之flannel的vxlan模式
七、在所有node节点上部署coreDNS
八、最后拓展calico插件部署
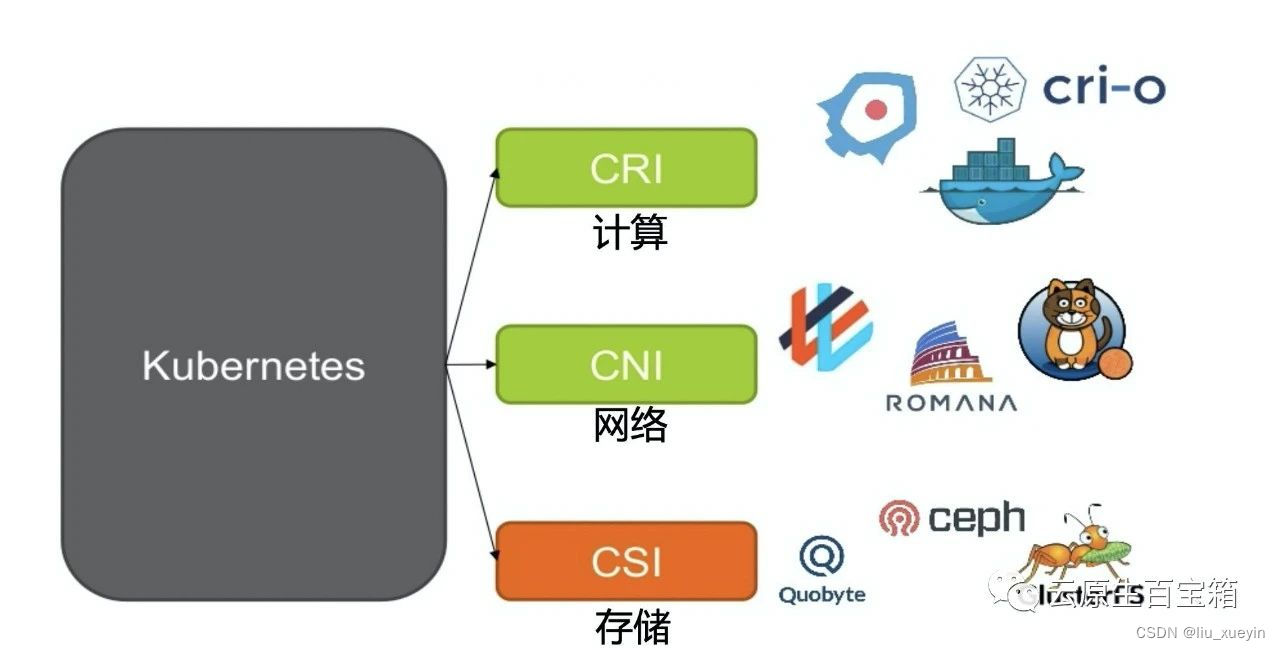
一、k8s集群的三种接口
前言,k8s集群有三大接口:
CRI:容器进行时接口,连接容器引擎--docker、containerd、cri-o、podman
CNI:容器网络接口,用于连接网络插件如:flannel、calico、cilium
CSI:容器存储接口,如nfs、ceph、gfs、oss、s3、minio
二、k8s的三种网络模式
k8s集群中pod网络通信分类
1、pod内容器之间的通信
在同一个 Pod 内的容器(Pod 内的容器是不会跨宿主机的)共享同一个网络命令空间,相当于它们在同一台机器上一样,可以用 localhost 地址访问彼此的端口。

2、同一个node节点中pod之间通信
每个 Pod 都有一个真实的全局 IP 地址,同一个 Node 内的不同 Pod 之间可以直接采用对方 Pod 的 IP 地址进行通信,Pod1 与 Pod2 都是通过 Veth 连接到同一个 docker0 网桥,网段相同,所以它们之间可以直接通信。
3、不同的node节点的pod之间通信
Pod 地址与 docker0 在同一网段,docker0 网段与宿主机网卡是两个不同的网段,且不同 Node 之间的通信只能通过宿主机的物理网卡进行。
要想实现不同 Node 上 Pod 之间的通信,就必须想办法通过主机的物理网卡 IP 地址进行寻址和通信。因此要满足两个条件:①Pod 的 IP 不能冲突;将 Pod 的 IP 和所在的 Node 的 IP 关联起来,②通过这个关联让不同 Node 上 Pod 之间直接通过内网 IP 地址通信。
总结:因此引入了cni网络插件的核心原因实际上就是为了解决不同node节点上的不同pod之间的通信,即pod跨主机通信

关于k8s的三种类型的网络IP
节点网络:nodeIP---node节点的物理网卡ip,实现node节点之间的通信
Pod网络:PodIP---Pod与Pod之间通过PodIP进行通信
service网络:clusterIP---k8s集群内部,service资源的clusterIP实现对Pod集群的网络代理
Overlay Network
叠加网络,在二层或者三层基础网络上叠加的一种虚拟网络技术模式,该网络中的主机通过虚拟链路隧道连接起来(类似于VPN)
个人理解为正常的数据包是一层 也就是【mac头+ip头+udp/tcp头+真实数据】,这种叠加网络就是说把【mac头+ip头+udp/tcp头+真实数据】看做一个整体,作为真实数据 再次封装,{【mac头+ip头+udp/tcp头】+【mac头+ip头+udp/tcp头+真实数据】} 这种看成一个整体
VXLAN
将源数据包封装到UDP中,并使用基础网络的IP/MAC作为外层报文头进行封装,然后在以太网上传输,到达目的地后由隧道端点解封装并将数据发送给目标地址。
三、flannel网络插件
Flannel 的功能是让集群中的不同节点主机创建的 Docker 容器都具有全集群唯一的虚拟 IP 地址。
Flannel 是 Overlay 网络的一种,也是将 TCP 源数据包封装在另一种网络包里面进行路由转发和通信,目前支持 udp、vxlan、 host-GW 3种数据转发方式。
1、flannel插件模式之UDP模式(8285端口)


第一步:原始的数据包从pod容器发送给cni0网桥,cni0网桥将数据包发送给flannel0虚拟接口
第二步:flanneld服务进程会监听flannel.0接口接收的数据,flanneld服务进程将数据包封装到UDP的报文中(叠加封装)
第三步:flanneld服务进程会通过etcd数据库查询路由表信息,找到关于目标pod所在的node节点的ip,然后在UDP报文外再次封装nodeip头部、mac头部,并通过物理网卡发送给目标node节点
第四步:UDP报文通过8285端口送达到目标node节点的flanneld进程进行解封装,在根据本地的路由表规则通过flannel0接口发送到cni0网桥,再由cni0发送给目标pod容器
总结:udp模式的工作核心是基于flanneld应用进行原始数据包封装在udp报文中,属于overlay网络的一种
#ETCD 之 Flannel 提供说明:
①功能1:存储管理Flannel可分配的IP地址段资源
②功能2:监控 ETCD 中每个 Pod 的实际地址,并在内存中建立维护 Pod 节点路由表
由于 udp 模式是在用户态做转发,会多一次报文隧道封装,因此性能上会比在内核态做转发的 vxlan 模式差。
2、flannel插件模式之VXLAN模式

第一步:原始数据帧从源主机的pod容器发出到cni0网桥,再由cni0转发给flannel.1虚拟接口
第二步:flannel.1接口接收数据帧以后先添加vxlan头部,然后在内核将原始数据帧封装在UDP报文中
第三步:flanneld会查询etcd中的路由表信息获取目标pod的nodeip,然后再udp报文外封装nodeip头部和mac头部,通过物理网卡发送给目标node节点
第四步:报文会通过8472端口到目标node节点的flannel.1接口,并在内核中解封装,最后根据本地的路由规则转发到cni0网桥,再发送到目标pod容器
3、总结flannel插件的三大模式
UDP——出现最早,性能最差。基于flanneld应用程序实现原始数据包的封装和解封装
VXLAN——是flannel的默认模式,也是推荐使用模式。(与udp模式比:)性能比udp好,基于内核实现原始数据帧的封装和解封装;(与HOST-GW模式比:)配置简单使用方便。
HOST-GW——性能最好的模式,但是配置复杂,且不能跨网段(通过静态路由实现)

4、拓展:关于vlan和vxlan的区别
(1)作用不同:
vlan是用于在交换机上实现逻辑划分广播域,还可以配合stp生成树协议阻塞路径接口,避免产生环路和广播风暴
vxlan是将数据帧封装在udp报文中,通过网络层传输给其他网络,实现虚拟大二层网络通信
(2)数量不同:
vxlan支持更多的二层网络,最多支持2^24个
vlan最多支持2^12个
(3)mac表中的记录不同
vxlan采用的是隧道机制,mac物理地址不需要记录在交换机中
vlan需要在mac表中记录mac地址
四、calico网络插件
●flannel方案
需要在每个节点上把发向容器的数据包进行封装后,再用隧道将封装后的数据包发送到运行着目标Pod的node节点上。目标node节点再负责去掉封装,将去除封装的数据包发送到目标Pod上。数据通信性能则大受影响。
●calico方案
Calico不使用隧道或NAT来实现转发,而是把Host当作Internet中的路由器,使用BGP同步路由,并使用iptables来做安全访问策略,完成跨Host转发来。
#Calico 主要由三个部分组成:
Calico CNI插件:主要负责与kubernetes对接,供kubelet调用使用。
Felix:负责维护宿主机上的路由规则、FIB转发信息库等。
BIRD:负责分发路由规则,类似路由器。
Confd:配置管理组件。
1、calico插件模式之IPIP模式

第一步:原始数据包从源主机的pod发出,通过veth pair设备送达到tunl0接口,再被内核的ipip驱动封装在node节点网络的ip报文中
第二步:根据felix维护的路由规则通过物理网卡发送到目标的node节点
第三步:数据包到达目标node节点的tunl0接口后再通过内核的ipip驱动解封装得到原始数据包,再根据本地的路由规则通过veth pair设备送达到目标pod容器
2、calico插件模式之BGP模式
calico的BGP模式工作原理(本质就是通过路由规则来实现Pod之间的通信)
每个Pod容器都有一个 veth pair 设备,一端接入容器,另一个接入宿主机网络空间,并设置一条路由规则。
这些路由规则都是 Felix 维护配置的,由 BIRD 组件基于 BGP 动态路由协议分发路由信息给其它节点。
1)原始数据包从源主机的Pod容器发出,通过 veth pair 设备送达到宿主机网络空间
2)根据Felix维护的路由规则通过物理网卡发送到目标node节点
3)目标node节点接收到数据包后,会根据本地路由规则通过 veth pair 设备送达到目标Pod容器
3、总结calico插件三大模式
五、对比flannel和calico的区别
(1)从模式来讲
- flannel插件的模式有:udp、vxlan、host-gw
- calico插件的模式有:IPIP、BGP、CrossSubnet(混合模式)
(2)从默认网段来讲
- flannel默认的网段是10.244.0.0/16
- calico默认的网段是192.168.0.0/16
(3)从模式的性能来讲
flannel
- 通常会采用VXLAN模式,用的是叠加网络、IP隧道方式传输数据,对性能有一定的影响。
- Flannel产品成熟,依赖性较少,易于安装,功能简单,配置方便,利于管理。但是不具备复杂的网络策略配置能力。
calico
- 使用IPIP模式可以实现跨子网传输,但是传输过程中需要额外的封包和解包过程,对性能有一定的影响。
- 使用BGP模式会把每个node节点看作成路由器,通过Felix、BIRD组件来维护和分发路由规则,可实现直接通过BGP路由协议实现路由转发,传输过程中不需要额外封包和解包过程,因此性能较好,但是只能在同一个网段里使用,无法跨子网传输。
- calico不使用cni0网桥,而使通过路由规则把数据包直接发送到目标主机,所以性能较高;而且还具有更丰富的网络策略配置管理能力,功能更全面,但是维护起来较为复杂。
(4)从使用场景来讲
- 对于较小规模且网络要求简单的K8S集群,可以采用flannel作为cni网络插件;
- 对于K8S集群规模较大且要求更多的网络策略配置时,可以考虑采用性能更好功能更全面的calico或cilium。
六、在所有node节点部署cni网络插件之flannel的vxlan模式
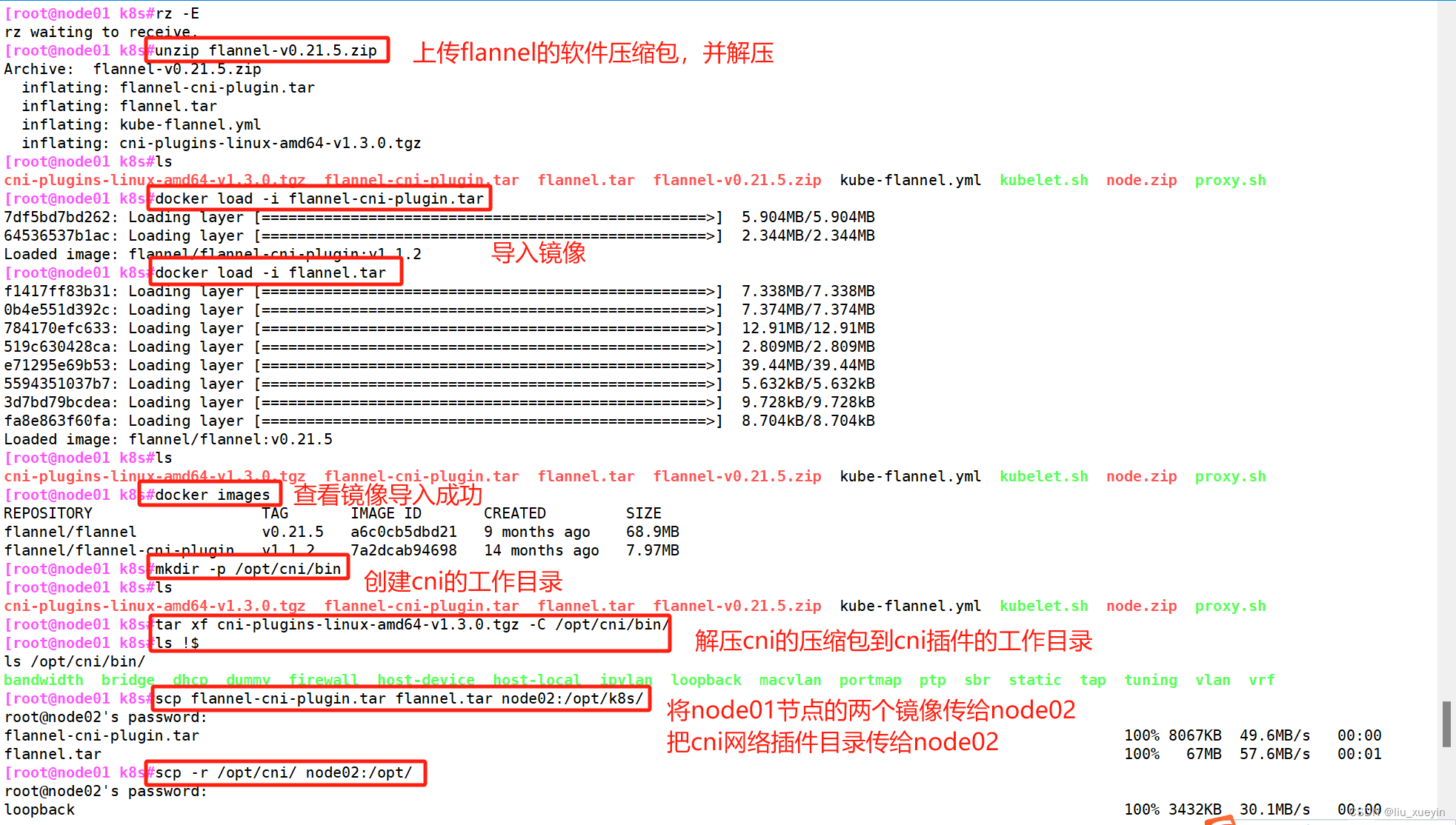
上传flannel-v0.21.5.zip
[root@node01 k8s#unzip flannel-v0.21.5.zip
##上传 flannel-v0.21.5.zip 到 /opt/k8s 目录中,并完成解压[root@node01 k8s#ls
cni-plugins-linux-amd64-v1.3.0.tgz flannel-cni-plugin.tar flannel.tar flannel-v0.21.5.zip kube-flannel.yml kubelet.sh node.zip proxy.sh##导入镜像
[root@node01 k8s#docker load -i flannel-cni-plugin.tar
[root@node01 k8s#docker load -i flannel.tar ##查看镜像是否导入成功
[root@node01 k8s#docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
flannel/flannel v0.21.5 a6c0cb5dbd21 9 months ago 68.9MB
flannel/flannel-cni-plugin v1.1.2 7a2dcab94698 14 months ago 7.97MB##创建cni网络插件的工作目录
[root@node01 k8s#mkdir -p /opt/cni/bin#将flannel-v0.21.5.zip解压后的cni-plugins-linux-amd64-v1.3.0.tgz解压到cni网络插件的工作目录
[root@node01 k8s#tar xf cni-plugins-linux-amd64-v1.3.0.tgz -C /opt/cni/bin/
[root@node01 k8s#ls !$
ls /opt/cni/bin/
bandwidth bridge dhcp dummy firewall host-device host-local ipvlan loopback macvlan portmap ptp sbr static tap tuning vlan vrf##将2个镜像和cni工作目录传输给node02节点
[root@node01 k8s#scp flannel-cni-plugin.tar flannel.tar node02:/opt/k8s/
[root@node01 k8s#scp -r /opt/cni/ node02:/opt/
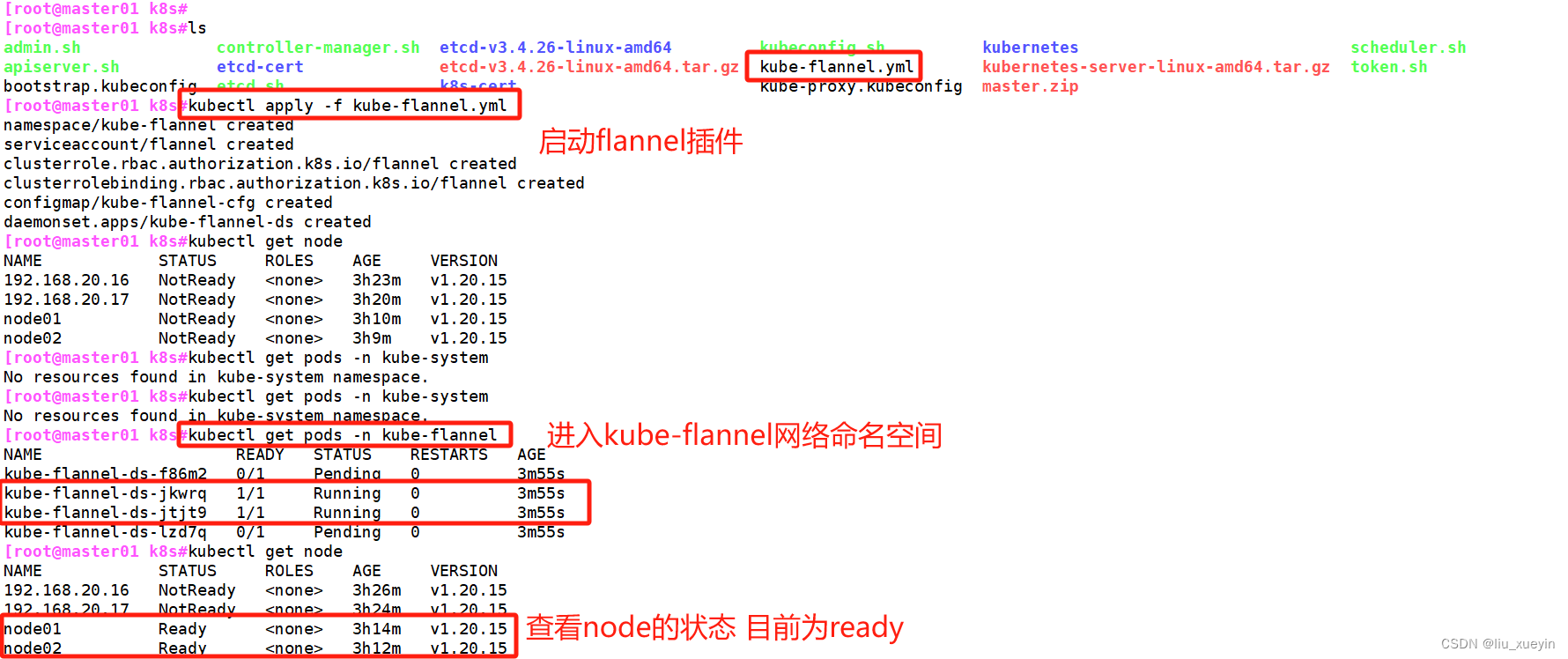
[root@node01 k8s#scp kube-flannel.yml master01:/opt/k8s/

//在 master01 节点上操作
#上传 kube-flannel.yml 文件到 /opt/k8s 目录中,部署 CNI 网络
cd /opt/k8s
kubectl apply -f kube-flannel.yml kubectl get pods -n kube-flannel
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-hjtc7 1/1 Running 0 7skubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.20.16 Ready <none> 81m v1.20.11
ip -d addr show flannel.1 要知道网络插件的目的是为了解决跨node节点的pod进行通信,那么验证一下
要知道网络插件的目的是为了解决跨node节点的pod进行通信,那么验证一下
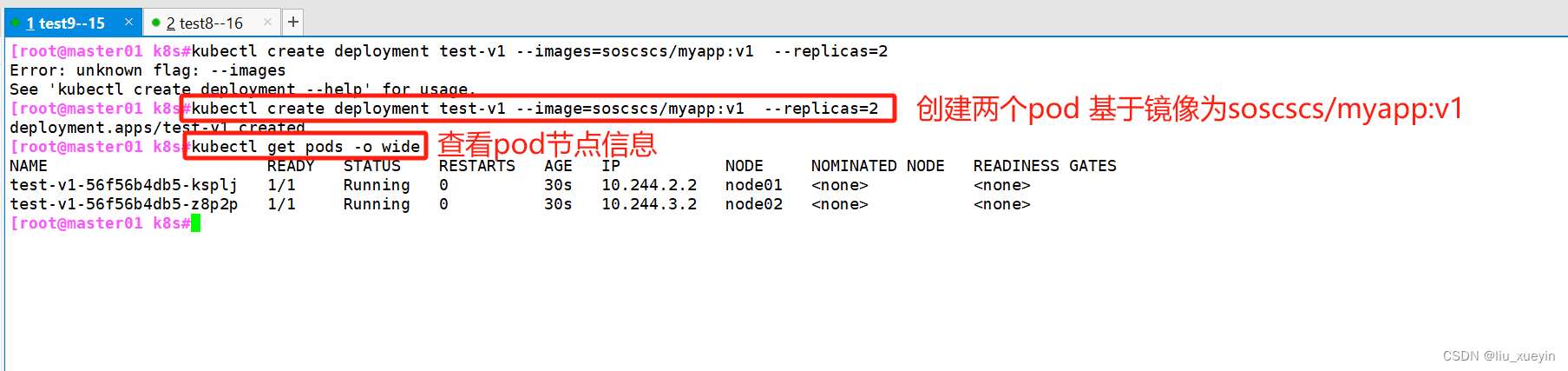
1.在master01节点创建pod资源
##创建pod
[root@master01 k8s#kubectl create deployment test-v1 --image=soscscs/myapp:v1 --replicas=2#查看pod状态
[root@master01 k8s#kubectl get pods -o wide
2.在node节点查看容器情况

3.进入容器中 查看是否可以完成跨主机pod通信

注意:有几个文件中的网段设置需要一致
kube-flannel.yml中的网段设置
与controller manager以及kube-proxy脚本中设置的网段需要保持一致
kube-flannel.yml

controller manager脚本

kube-proxy脚本

七、在所有node节点上部署coreDNS
CoreDNS 是 K8S 默认的集群内部 DNS 功能实现,为 K8S 集群内的 Pod 提供 DNS 解析服务
- 根据 service 的资源名称 解析出对应的 clusterIP
- 根据 statefulset 控制器创建的Pod资源名称 解析出对应的 podIP
在所有node节点上上传coredns.tar软件包
//在所有 node 节点上操作
#上传 coredns.tar 到 /opt 目录中
cd /opt
docker load -i coredns.tar
在master01节点上部署coredns
//在 master01 节点上操作
#上传 coredns.yaml 文件到 /opt/k8s 目录中,部署 CoreDNS
cd /opt/k8s
kubectl apply -f coredns.yamlkubectl get pods -n kube-system 
验证可以通过service的名称进行通信
[root@master01 k8s#kubectl get pods --show-labels
##查看当前的pod资源 并展示其label标签
NAME READY STATUS RESTARTS AGE LABELS
test-v1-56f56b4db5-ksplj 1/1 Running 0 25m app=test-v1,pod-template-hash=56f56b4db5
test-v1-56f56b4db5-z8p2p 1/1 Running 0 25m app=test-v1,pod-template-hash=56f56b4db5##查看当前的service资源有哪些
[root@master01 k8s#kubectl get service
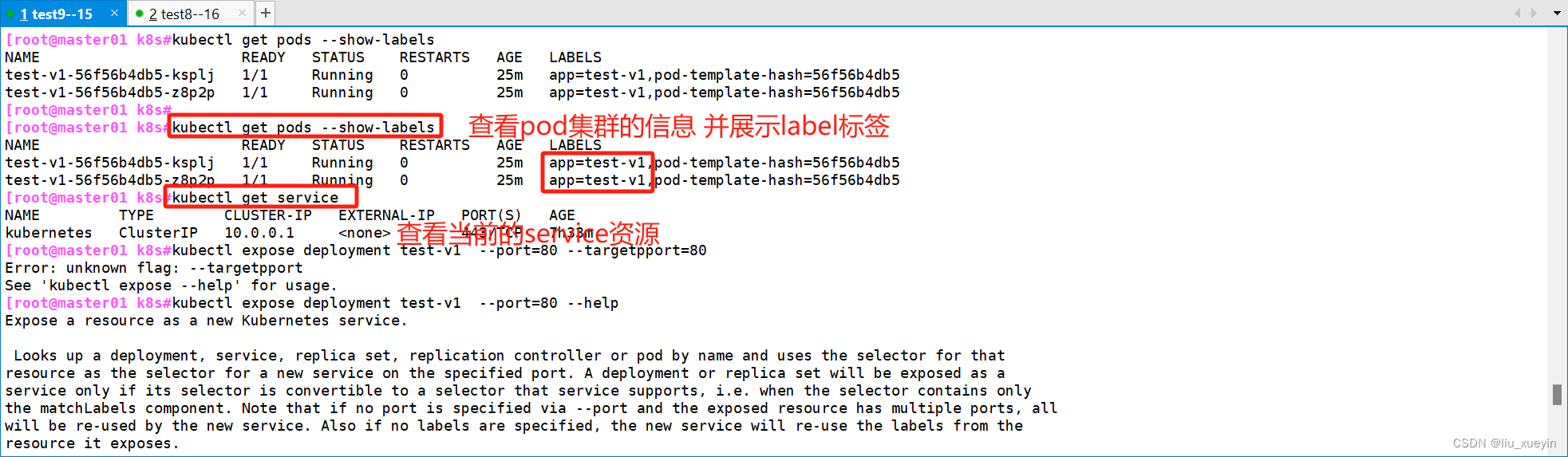
[root@master01 k8s#kubectl expose deployment test-v1 --port=80 --target-port=80
##创建service资源
service/test-v1 exposed
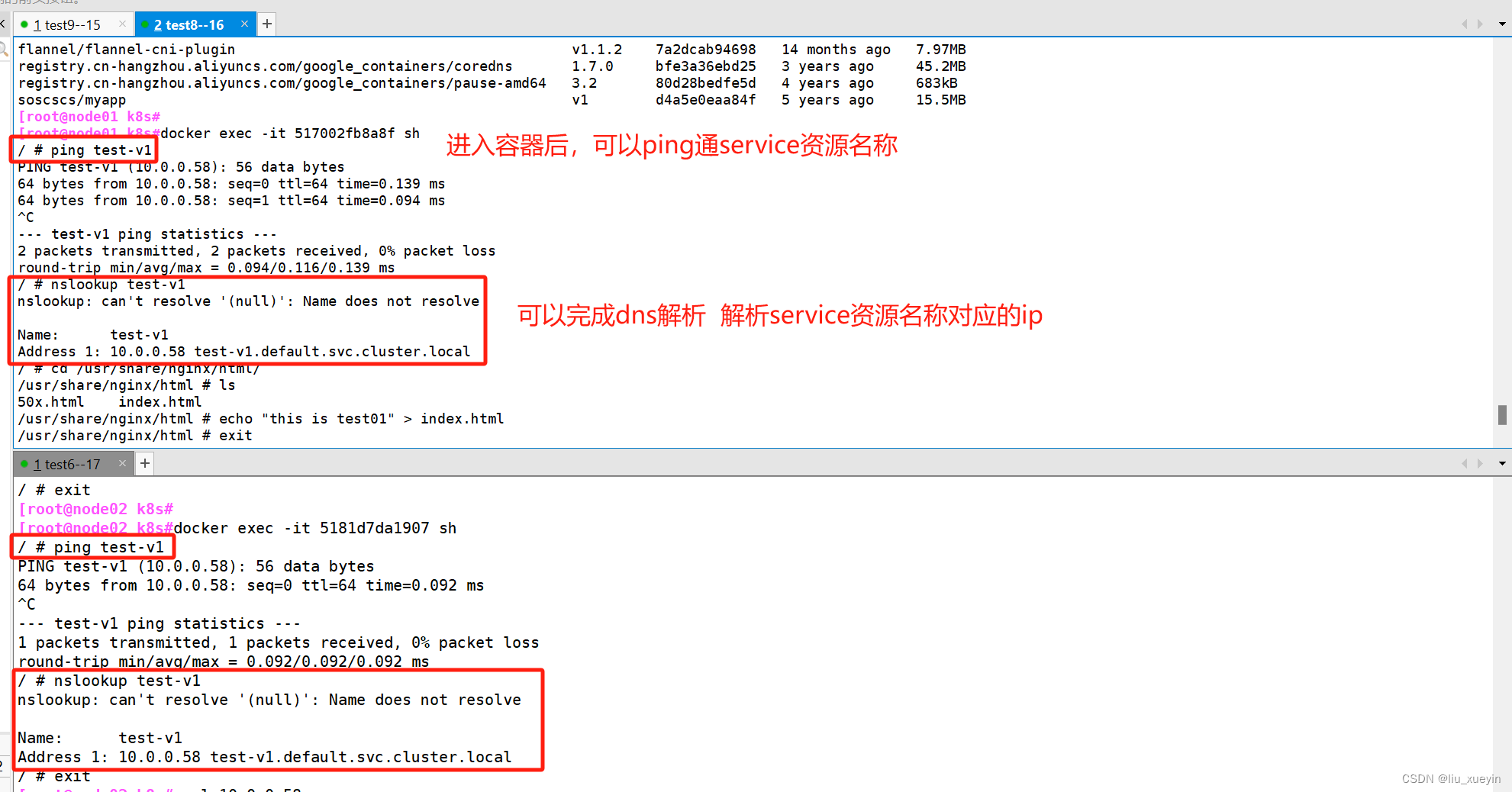
在node节点中进入容器,验证可以通过service资源名称通信 以及可以实现nslookup
验证service资源可以实现pod集群的四层网络代理,实现负载均衡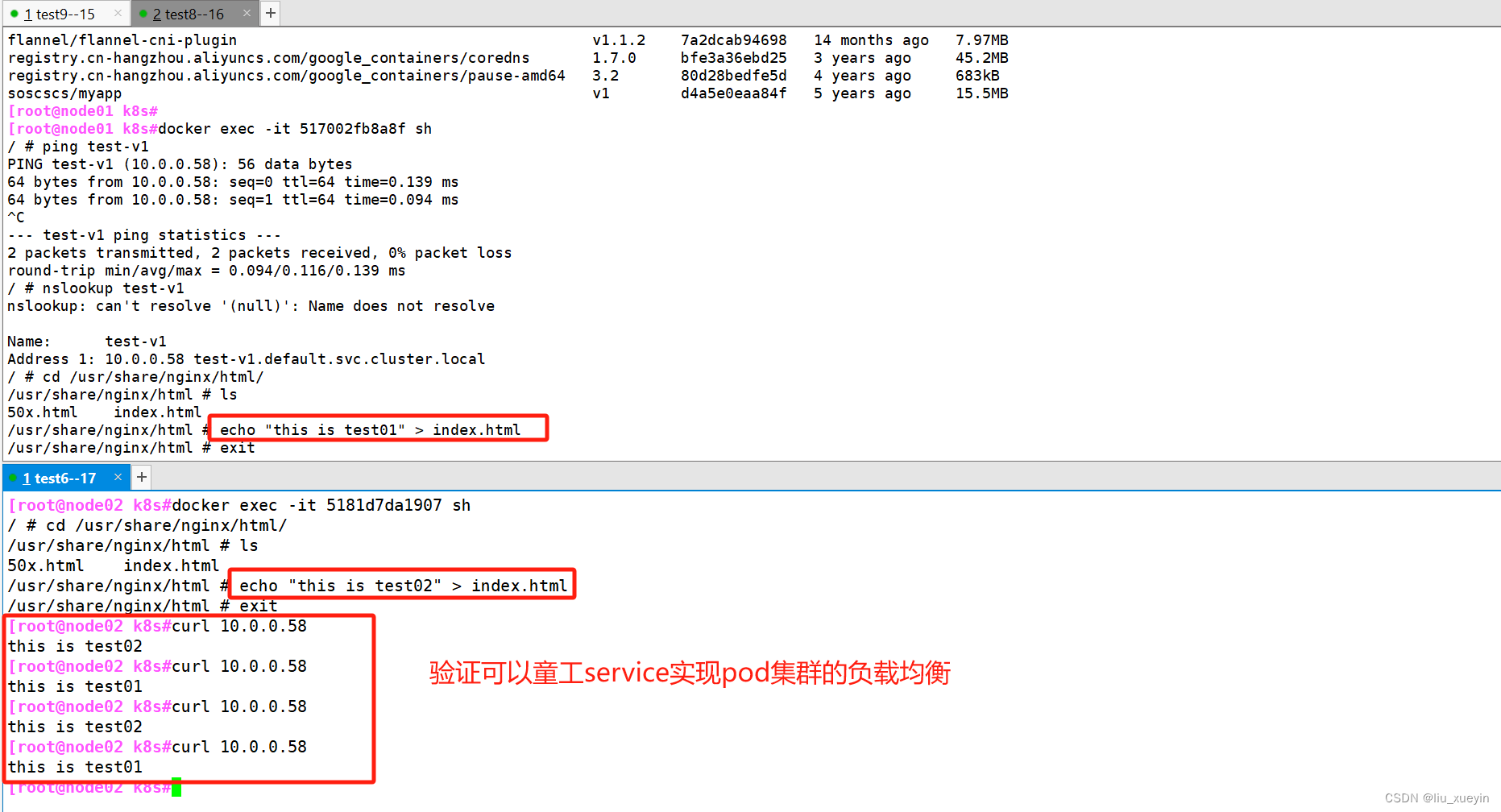
八、最后拓展calico插件部署
//在 master01 节点上操作
#上传 calico.yaml 文件到 /opt/k8s 目录中,部署 CNI 网络
cd /opt/k8s
vim calico.yaml
#修改里面定义Pod网络(CALICO_IPV4POOL_CIDR),与前面kube-controller-manager配置文件指定的cluster-cidr网段一样- name: CALICO_IPV4POOL_CIDRvalue: "192.168.0.0/16"kubectl apply -f calico.yamlkubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-659bd7879c-4h8vk 1/1 Running 0 58s
calico-node-nsm6b 1/1 Running 0 58s
calico-node-tdt8v 1/1 Running 0 58s#等 Calico Pod 都 Running,节点也会准备就绪
kubectl get nodes---------- node02 节点部署 ----------
//在 node01 节点上操作
cd /opt/
scp kubelet.sh proxy.sh root@192.168.20.17:/opt/
scp -r /opt/cni root@192.168.20.17:/opt///在 node02 节点上操作
#启动kubelet服务
cd /opt/
chmod +x kubelet.sh
./kubelet.sh 192.168.20.17//在 master01 节点上操作
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
node-csr-BbqEh6LvhD4R6YdDUeEPthkb6T_CJDcpVsmdvnh81y0 10s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending
node-csr-duiobEzQ0R93HsULoS9NT9JaQylMmid_nBF3Ei3NtFE 85m kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Approved,Issued#通过 CSR 请求
kubectl certificate approve node-csr-BbqEh6LvhD4R6YdDUeEPthkb6T_CJDcpVsmdvnh81y0kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
node-csr-BbqEh6LvhD4R6YdDUeEPthkb6T_CJDcpVsmdvnh81y0 23s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Approved,Issued
node-csr-duiobEzQ0R93HsULoS9NT9JaQylMmid_nBF3Ei3NtFE 85m kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Approved,Issued#加载 ipvs 模块
for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done#使用proxy.sh脚本启动proxy服务
cd /opt/
chmod +x proxy.sh
./proxy.sh 192.168.20.17#查看群集中的节点状态
kubectl get nodes这篇关于【kubernetes】二进制部署k8s集群之cni网络插件flannel和calico工作原理(中)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








