本文主要是介绍Optimizing FPGA-based Accelerator Design for Deep Convolutional Neural Networks ,2015 论文阅读笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简述:这篇文章的贡献在于
-
对CNN FPGA加速器的技术 (例如循环平铺和转换) 优化,同时进行了定量分析计算吞吐量和片内外I/0带宽和建模
-
通过roof-line模型搜索加速器硬件参数设计空间中最优的方案,
-
最后通过此建模方案设计了一个加速器,获得当时最优性能密度的CNN加速器。
背景与动机
回答Paper 背景和解决什么问题?
背景
-
卷积神经网络 (CNN) 已被广泛应用
-
基于FPGA平台提出了各种用于深度CNN的加速器,因为它具有高性能、可重构、快速开发等优点
动机
尽管当时的FPGA加速器已显示出比通用处理器更好的性能,但加速器设计空间尚未得到很好的利用。由于逻辑资源或内存带宽的利用不足,现有方法无法实现最佳性能。
需求一个对CNN FPGA加速器的建模方案来探索设计空间中的最优设计方案。
CNN加速器技术优化和计算性能与资源需求建模
对于一个典型的CNN模型卷积层如下所示。
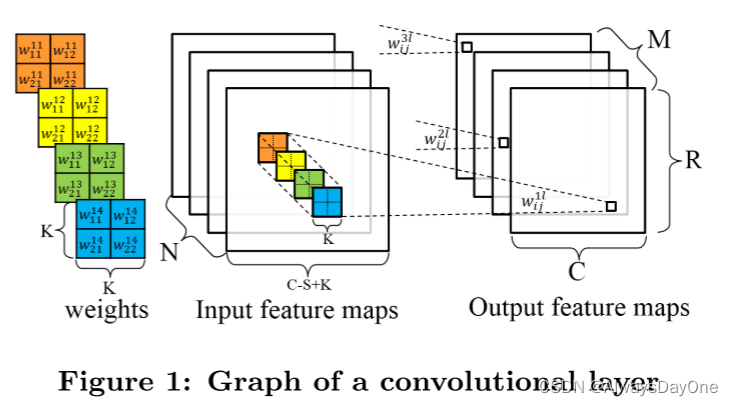
卷积层接收 N 个 feature map 作为输入。每个输入特征图都由具有K × K卷积核的移位窗口卷积,以在一个 Output feature map中生成一个像素。移动窗口的步幅为 S ,通常小于 K 。总共 M 个 Output feature map 将构成下一个卷积层的输入特征图集。
卷积层的伪代码可以写为代码1中的伪代码。

常见的一般是加速计算的设计方法是loop tiling技术,将code 1转化为如下代码,区分片上片外的循环,使得片上操作数据高吞吐量。
请注意,循环迭代器i和j没有平铺,因为CNN中卷积窗口大小K的大小相对较小 (通常范围为3到11)。

polyhedral-based 数据依赖分析方法
标准的polyhedral-based 数据依赖分析方法是参考引用的其他文章,后面的对加速方法的优化会用此分析方法的结果。
给定数组上循环维度的不同循环迭代之间的数据共享关系可以分为三类:
-
Irrenlevant 不相关:循环的迭代变量i并未出现在数组的索引中,则该循环维度与此数组无关
-
Independent 独立:数组的一个索引维度只与一个循环维度相关,数组可以沿着从循环维度可拆分
-
Dependent 依赖:数组中的一个索引维度与多个循环维度相关,数组不可能沿着其中任意一个循环维度拆分
不同数据共享关系生成的硬件实现如图6所示:
-
Irrenlevant的数据共享关系会生成广播连接。
-
Independent 数据共享关系在缓冲区和计算引擎之间生成直接连接。
-
Dependent 数据共享关系生成具有复杂拓扑的互连。
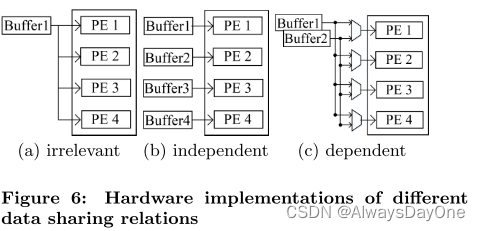
由此可以注意到:数据共享关系依赖关系越强,对应的硬件实现就越复杂,需要的硬件资源更多。
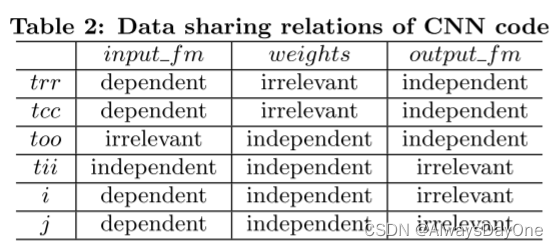
如figure 5中的 input_fm[tii][Strr+i][Stcc+j]:
-
由于数组的索引位中未出现too,则与too与infut_fm是Irrenlevant数据共享关系
-
由于tii是单独的索引关系,故tii与infut_fm是Independent 数据共享关系
-
由于trr 和 i , tcc 和 j 两组循环迭代变量分别关联在数组同一个索引位置,故他们两个都形成Dependent 数据共享关系
对figure 5中所有数据和循环的数据共享依赖总结可以得到如下表:
片上计算优化与建模
这一部分主要是对片上的加速器计算模块进行优化和建模。
在figure 5中已经有常用的tiling优化技术,下面是其他的优化。
优化 loop unrolling
循环展开可用于提高FPGA设备中大量计算资源的利用率,更多的资源也意味着计算吞吐的提高。但沿着不同的循环维度展开时,两个展开的执行硬件之间的数据共享程度将影响硬件的复杂程度。
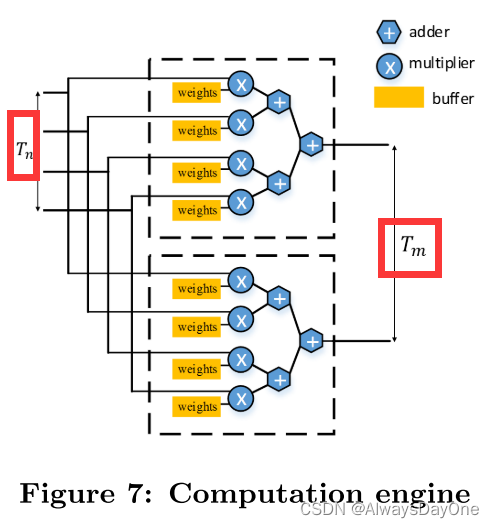
基于前面polyhedral-based 数据依赖分析可以知道,将figure 5 中代码的too和tii循环是所有循环中数据共享依赖最低的,将这两个循环置换到最里面的循环等价生成的硬件更简单。其代码如下Code 3。生成的硬件实现如figure 7.
优化 loop pilelining
循环流水线是高级综合中的关键优化技术,可通过重叠执行来自不同循环迭代的操作来提高系统吞吐量。
但所实现的吞吐量受到程序中的资源约束和数据依赖性的限制。循环的依赖将阻止完全流水线化。
因此polyhedral-based 数据依赖分析可以将并行环路电平置换为最内层,将最少关系数据依赖关系的循环放在最内层进行流水。

建模计算性能
在基于上面三种(tiling, unrolling, pipelining)的计算优化,对其进行计算性能进行建模。
首先是分片大小的约束。由于Tm,Tn是被循环展开的,故其映射到了计算PE单元,受PE资源数量的约束,tiling分片的大小也都必须小于其循环的上界。
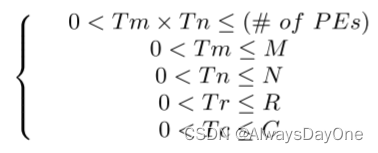
在如上的约束下计算code 3的计算性能:

-
计算性能=总的循环计算操作数(2表示乘累加的操作数为2)/加速器实际执行的周期数 = 每cycle的计算量
-
注意到加速器的实际执行周期数是考虑(片外的循环大小) X (片内循环大小) X (循环展开的每个PE的流水周期数)
片外存储访问优化和建模
Local Memory Promotion 本地内存提升
如果通信部分中的最内层循环 (figure 9中的循环维度ti) 与数组无关,则在不同的循环迭代之间会有冗余的内存操作。
如在片外的循环中,ti与输出特征图是无关的,那么可以将Store 输出特征图提升到to级循环,则可以提升片内的数据重用,不再每一次循环ti就做一次load和store操作。这时候load操作也不需要了。

但这样做我理解片上的存储量会更大。
Loop Transformations for Data Reuse 面向数据重用的循环转换
利用polyhedral-based 数据依赖分析方法来进行loop transformation,可以充分的使用Local Memory Promotion优化。
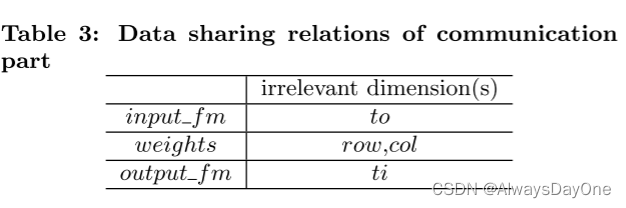
如表3中所示的Irrenlevant 数据共享依赖关系,表示数组和循环不相关,则可以进行Local Memory Promotion优化。
片外存储访问建模
**CTC比率:**计算与通信 (Computation to communication,CTC) 比率用于描述每个内存单位访问量的计算操作数量。数据重用优化将减少内存数据访问的总量,从而增加CTC比率。其计算公式如下:
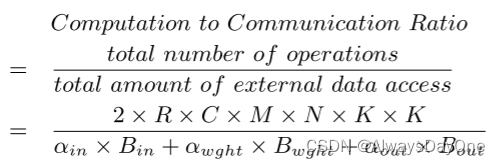
-
其中分子是总的计算操作数,其中2我理解为乘累加算2个操作数。
-
其中α表示对输入/输出特征图和权重的外部存储器的访问次数
-
B表示输入/输出特征图和权重在片上暂存的数据量大小,也表示一次片内外交互的数据量大小,其具体计算如下式子
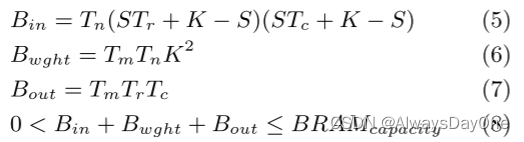
-
B输入/输出特征图和权重在片上暂存的数据量大小必须受到片上BRAM资源大小的限制
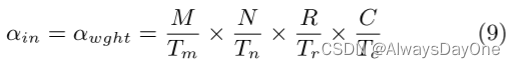
- 输入特征图和权重数据在figure 9的load 操作是一致的,都被4外片外的循环包含,所以访问外存的次数等于片外的四层循环数
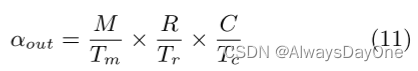
- 输出特征图的由于通过Local Memory Promotion优化,在外部只需要被三层循环包含,只需要一次store操作,访问外存的次数等于片外的最外三层循环数
设计空间搜索Roof-line模型
在基于如上对片上计算量建模、片内外数据访问量的建模,有了资源约束和性能目标,接下来的工作是希望通过一个模型能够利用如上公式解得最优的分片、循环展开、流水线和访存优化方案。
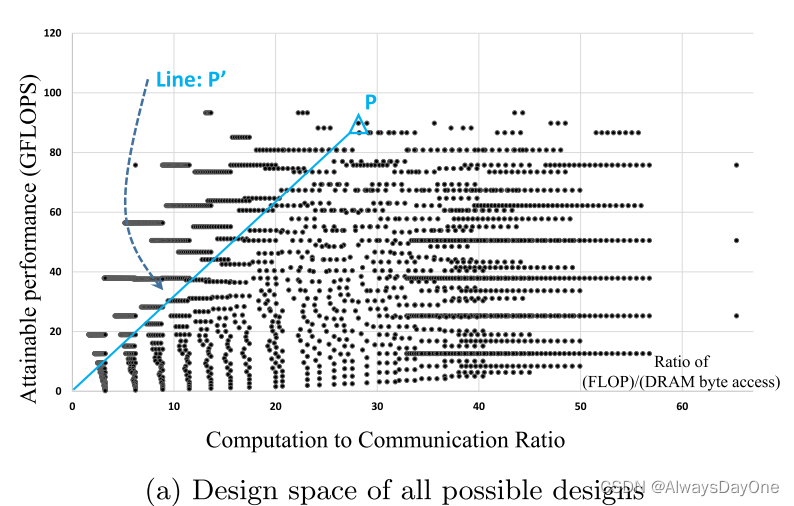
这里是通过roof-line模型来求解,如下图:
-
横坐标是 CTC比率,单位是每byte的外存DRAM访问可以进行的计算操作数FLOP
-
纵坐标是计算性能GFLOPS(Giga Floating-point Operations Per Second,每秒十亿次浮点运算数)
-
图中的点计算方法如下公式中,计算性能是片上计算能力和与内存通信带宽限制下的计算能力中最小值。其中CTC Ratio是内存建模的结果,BW是硬件平台提供的带宽。
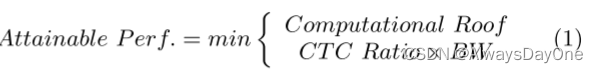
由此可以看到上图(a)有一些特点:
-
点P的斜率是等于其I/O带宽
-
纵坐标计算性能相同时,CTC Ratio越大,数据重用越多,斜率下降,则需要的I/O带宽资源越少
-
横坐标CTC Ratio相同时,计算性能越高,其斜率相同,需要的I/O带宽资源越高
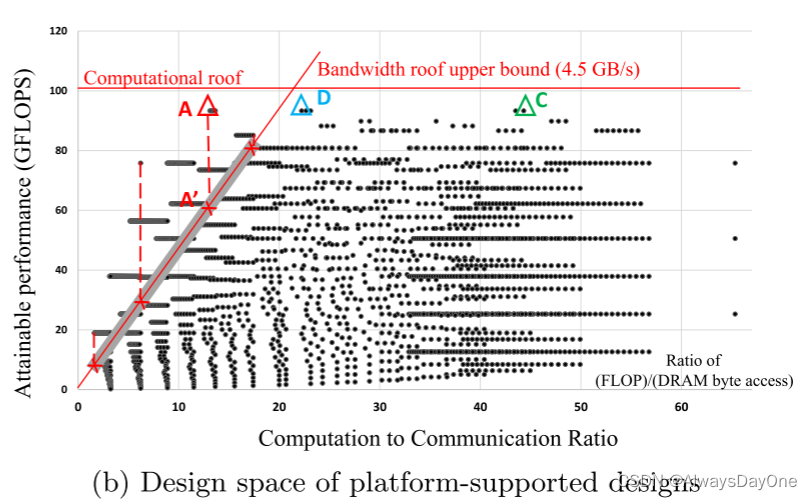
由图的性质分析图b:
-
红色的线是硬件平台的带宽限制和加速器最高提供的计算性能
-
其中以A点为代表的超过了计算性能,这时候虽然未达到计算性能天花板,但其斜率代表的I/O带宽>硬件平台的带宽上限,故只能映射到A’点,片上计算性能收到带宽限制发挥不出来
-
点C和点D都有相同的计算性能,但C的斜率比D的小,说明对I/O带宽需求小,所以选择C点更合适
由此总结在roof-line模型中,在硬件平台资源的限制中,越靠右上的点,性能越好,同时I/O带宽需求更低。
加速器实现
通过上述的roof-line模型,对figure2 中的示例CNN程序进行加速器设计空间探索,得到了Table 4中的最优选择结果。
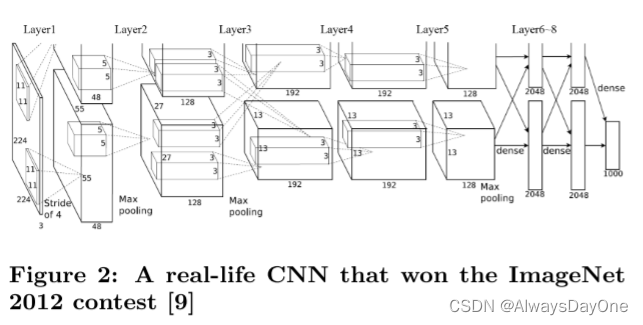
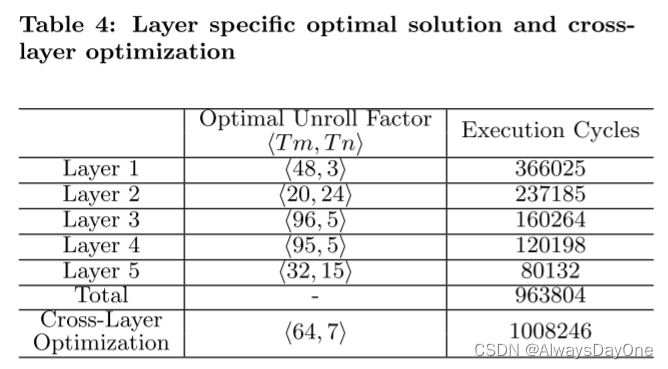
在统一展开因子 < 64,7> 的情况下,与每个优化卷积层的总执行周期相比,退化在5% 以内。文章的实验中选择了跨卷积层具有统一展开因子的CNN加速器。文章提到枚举空间大小的上限是98,000合法设计,可以在普通笔记本电脑上在10分钟内完成。
注意文章设计的加速器支持单个展开因子,设计硬件加速器以支持具有不同展开因子的多个卷积层将具有挑战性,需要复杂的硬件结构来重新配置计算引擎和互连。
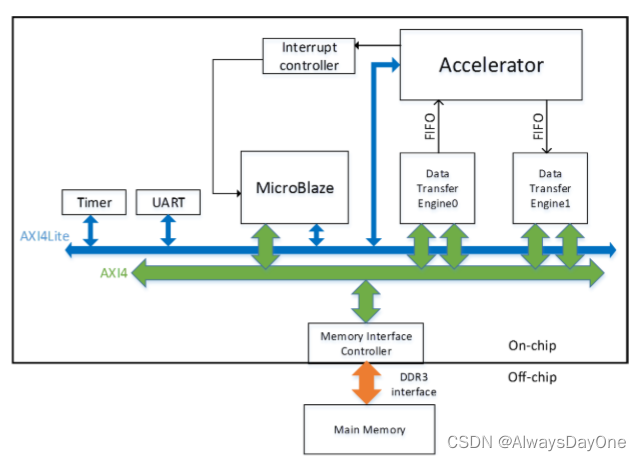
如下图是整个加速器的总览图。
-
外部存储使用的DDR3
-
MicroBlaze是为Xilinx fpga开发的RISC软处理器核心,用于协助CNN加速器启动,与主机CPU的通信和时间测量等
-
AXI4lite总线用于命令传输,AXI4总线用于数据传输
-
CNN加速器通过AXI4lite总线从MicroBlaze接收命令和配置参数,并通过FIFO接口与定制的数据传输引擎进行通信。
-
传输引擎可以通过AXI4总线访问外部存储器。
-
MicroBlaze和CNN加速器之间启用了中断机制,以提供准确的时间测量。
计算引擎如下图:
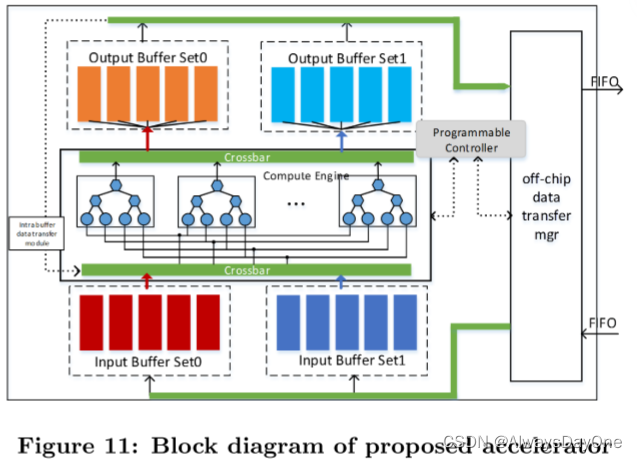
-
两级展开循环 (Figure 2中的Tm,Tn) 被实现为同时执行的计算引擎,使用如图7所示的树形聚结构。
-
对于展开因子 < 64,7> ,计算引擎被实现为树形多边形结构,具有来自输入特征图的7个输入和来自权重的7个输入和一个来自偏置的输入,存储在输出特征图的缓冲区中。
-
片上buffer建立在双缓冲的基本思想之上,其中双缓冲区以乒乓方式运行,使得数据传输时间与计算重叠。片上buffer它们分为四组: 两组用于输入特征图和权重,两组用于输出特征图。
乒乓机制可以如下图所示:

-
输入特征图和权重buffer和输出特征图buffer都有乒乓机制
-
在计算正在读输入特征图和权重buff时,可以同时从外存load数据到另一个buff,下一次读和load交换buff,如此可以计算数据使用和load数据同时操作
-
同理输出特征图buffer的计算数据写和往外存写也是同时进行的乒乓机制
实验
加速器设计采用Vivado HLS (v2013.4) 实现。
实现建立在具有Xilinx FPGA芯片Virtex7 485t的VC707板上。它的工作频率是100 MHz。软件实现在具有15MB缓存的英特尔至强CPU E5-2430 (@ 2.20GHz) 上运行。
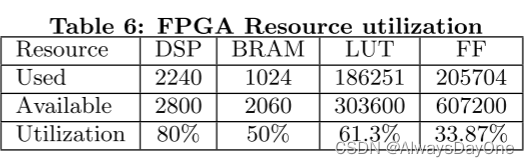
其设计CNN加速器几乎已经充分利用了FPGA的硬件资源。
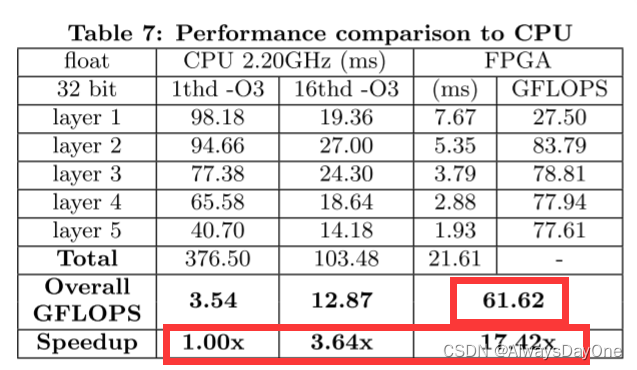
加速器是和CPU下的相同CNN应用程序进行对比,软件实现分别使用带有-O3优化选项的gcc在1个线程和16个线程中实现
总体而言,我们基于FPGA的实现比1个线程的软件实现提高了17.42x的速度。与16个线程的软件实现相比,它还实现了4.8倍的加速。我们的加速器的整体性能达到61.62的GFLOPS。
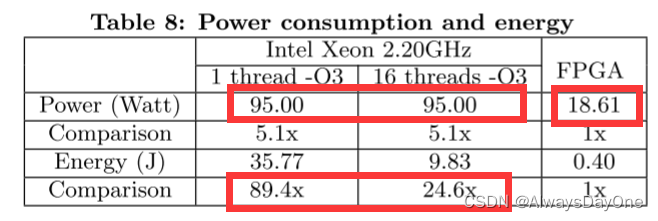
在能耗方面加速器FPGA实现比软件实现使用的能量少得多。
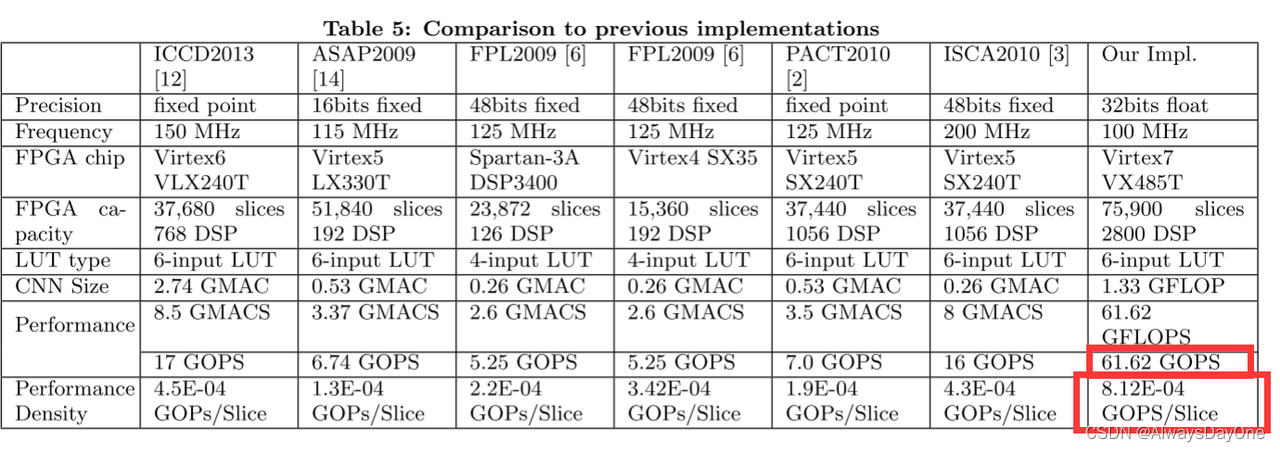
在与其他已实现的FPGA加速器进行对比,如Tbale 5。
-
该加速器的性能61.62GOPS比以往的工作至少高3.62倍
-
由于不同工作的FPGA平台是不一样的,由此转化为性能密度(每单位面积的平均GOPS)衡量会更准确,可以看到该工作性能密度是最高的,至少高出1.8倍
-
值得注意的是很多以往工作是定点数,资源消耗会更少,所以实际本文的工作效果会更好
总结与思考
这篇文章的贡献在于
-
对CNN FPGA加速器的技术 (例如循环平铺和转换) 优化,同时进行了定量分析计算吞吐量和片内外I/0带宽和建模
-
通过roof-line模型搜索加速器硬件参数设计空间中最优的方案,
-
最后通过此建模方案设计了一个加速器,获得当时最优性能密度的CNN加速器。
我个人读了之后觉得其值得学习亮点如下:
-
利用polyhedral-based 数据依赖分析方法来优化现有常用的加速器技术(Tiling、Unroll、pipeline和loop transformation)
-
roof-line 模型对于设计空间的探索
文章中还有待继续的工作如下:
-
对于Tiling分片大小实现时固定在了硬件上,不可变,所以对于各conv层是折中选用了<64,7>综合最好的参数。但对于复杂实际应用的神经网络,这个效果不会很好。而后来的如2017年的FlexFlow: A Flexible Dataflow Accelerator Architecture for Convolutional Neural Networks这类文章是实现在硬件上可配置分片参数的,每个conv层都可以达到最优的硬件设计参数。
-
其只做了conv层加速设计,因为conv层占总计算量90%以上。对于其他pooling层未做兼容。
-
对于设计空间的搜索算法,在面对更大的模型设计空间下,和更多的优化技术参数引入,其搜索规模更大,如后来的TVM这类中使用的是机器学习方法更优的寻找最优设计
这篇关于Optimizing FPGA-based Accelerator Design for Deep Convolutional Neural Networks ,2015 论文阅读笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








