optimizing专题
Optimizing FPGA-based Accelerator Design for Deep Convolutional Neural Networks ,2015 论文阅读笔记
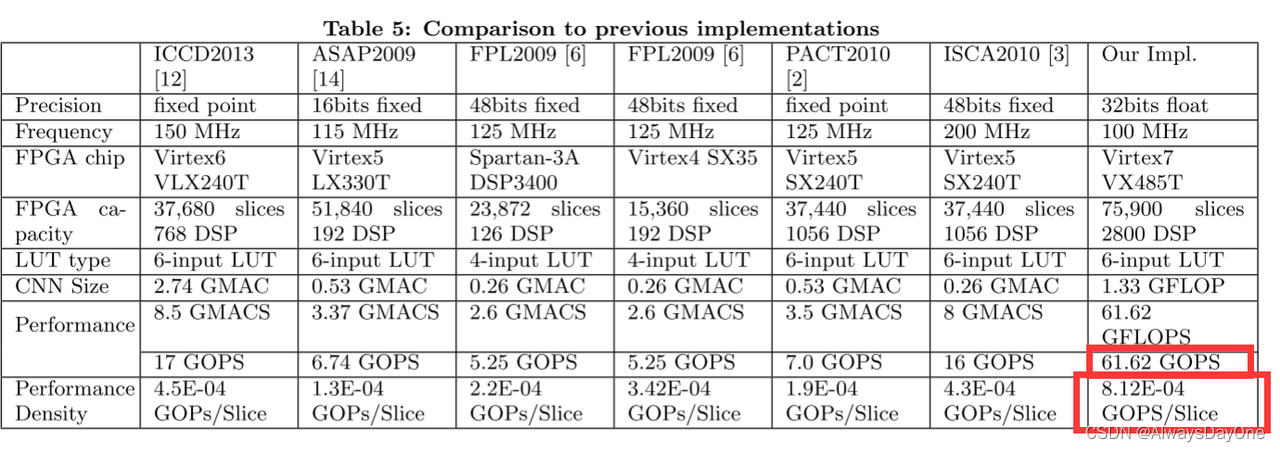
简述:这篇文章的贡献在于 对CNN FPGA加速器的技术 (例如循环平铺和转换) 优化,同时进行了定量分析计算吞吐量和片内外I/0带宽和建模 通过roof-line模型搜索加速器硬件参数设计空间中最优的方案, 最后通过此建模方案设计了一个加速器,获得当时最优性能密度的CNN加速器。 背景与动机 回答Paper 背景和解决什么问题? 背景 卷积神经网络 (CNN) 已被广泛
![[文献阅读]——Prefix-Tuning: Optimizing Continuous Prompts for Generation](https://img-blog.csdnimg.cn/10c125d5ba034ab7aa9cdbaebab182d0.png)
[文献阅读]——Prefix-Tuning: Optimizing Continuous Prompts for Generation
前言 task-specific的Fine-tuning需要为一个下游任务保存一个模型(只fine-tune task-specific的网络,参数量也不是很多啊?),而本文提出的prefix-tuning为不同任务设置一个向量,插入到输入中,减少需要保存的参数。 该问题的相关工作: fine-tuning:微调整个模型lightweight fine-tuning:选择一些参数(问题是选哪

DOT--A Matrix Model for Analyzing,Optimizing and Deploying Software for Big Data Analytics in Distri
1. Abstract Traditional parallel processing models, such as BSP, are “scale up” based, aiming to achieve high performance by increasing computing power, interconnection network bandwidth, and

TMS320F280049C 学习笔记32 TMS320C28x Optimizing C/C++ Compiler 阅读随笔
文章目录 前言1 Introduction to the Software Development Tools2 Using the C/C++ Compiler2.3 Changing the Compiler's Behavior with Options2.5 Controlling the Preprocessor2.7 Understanding Diagnostic Messag

论文阅读Optimizing Task Placement and Online Scheduling for Distributed GNN Training Acceleration
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、背景二、问题与挑战1.挑战2.问题 三、调度与任务部署方法1.在线调度算法OES2.探索性部署IFS算法3.搜索更好的部署计划ETP4.整体流程 四.实验结果总结 前言 Optimizing Task Placement and Online Scheduling for Distri

LLMs:《Optimizing your LLM in production在生产环境中优化您的LLM》翻译与解读—LLM在实际应用中面临的两大挑战(内存需求+对更长上下文输入需求)+提升LLM部署
LLMs:《Optimizing your LLM in production在生产环境中优化您的LLM》翻译与解读—LLM在实际应用中面临的两大挑战(内存需求+对更长上下文输入需求)+提升LLM部署效率的三大技术(低精度量化+更高效的自注意力算法Flash Attention+优化模型结构【位置嵌入/键-值缓存】) 导读:总结了LLM在实际应用中面临的两大挑战,以及提升LLM部署效率的三大技
Unity3D优化之Optimizing Script Performance
Optimizing Script Performance 优化脚本性能 This page gives some general hints for improving script performance on iOS. 这一页给出了一些在iOS系统上增强脚本性能的一般方法。 Reduce Fixed Delta Time 减少固定增量时间 Use