本文主要是介绍[文献阅读]——Prefix-Tuning: Optimizing Continuous Prompts for Generation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
task-specific的Fine-tuning需要为一个下游任务保存一个模型(只fine-tune task-specific的网络,参数量也不是很多啊?),而本文提出的prefix-tuning为不同任务设置一个向量,插入到输入中,减少需要保存的参数。
该问题的相关工作:
- fine-tuning:微调整个模型
- lightweight fine-tuning:选择一些参数(问题是选哪些)、或者插入一些层与层之间的参数来微调(ADAPTER)
- prompting:给输入插入一些触发词,来充分利用语言模型的优势
- 离散的(显式的、可解释性的):
- 人为设定的标识符,比如在摘要任务中,插入:“summarize the following table in one sentence”,效果不好
- 数据驱动的搜索标识符,效果会更好,但计算困难
- 连续的(隐式的、不可解释性的):
- 插入向量标识符,微调更新
- 离散的(显式的、可解释性的):
任务介绍
使用autoregressive模型来做生成:

使用encoder-decoder模型来做生成:

训练目标:
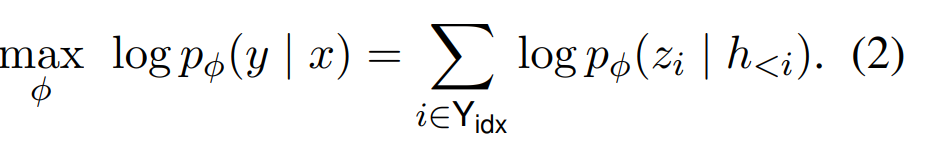
我的理解为:自回归模型将完整的X和Y作为输入,通过mask attention的方式,让生成的第i步,只能关注到前i步的信息;encoder-decoder的架构首先用一个encoder来把编码获得上下文信息,利用这个不变的上下文信息于decoder中
Prefix-Tuning
直觉:向量标识符能够指示模型1. 更好的从x中进行编码 2. 更好的影响y生成的概率分布
定义一个向量指示符的集合{p_1, p_2,…p_n},对应的参数为p_θ。对于自回归模型,输入为[p_i; x; y],encoder-decoder的输入为[p_i;x;p_j;y]。第i个时间部的计算结果为:
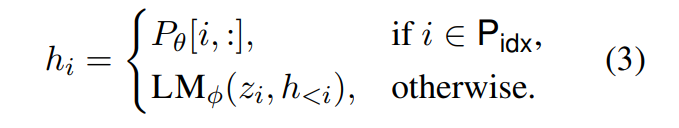
可以看到,p_j的位置保留了原来p_θ中的参数向量(通过mask attention实现,即掩盖掉对其它所有位置的attention),非p的位置i则attend to在i之前的所有位置,包括p_j,所以说,所有位置的输出,都是a output produced by a function of the trainable parameters p_θ。
如何设置p_θ?就设置一个 |p_i|(指示符个数) x dim 的矩阵就可以了吗?
实验表明,直接这么做,对学习率、初始化非常敏感,文中的做法为,同时设置两个参数矩阵:
- p_θ’ : |p_i| x k
- MLP:k x dim
每一次取出p_i的向量表示时,都需要MLP(p_θ’[i,:]),而当这两个参数矩阵训练完毕之后,保留p_θ = MLP(p_θ’)
实验
Table-to-text
比较了Prefix 和 Fine-Tune-all、Fine-Tune-Top2、ADAPTER-tuning,发现不上不下。疑问:为什么没有比较prompting?
Summarization
只比较了Prefix和Fine-Tune,发现效果更差。
Low-data Setting
低资源情况下,效果更好。
Extrapolation
即,在特定类别训练,在其它类别预测,发现ADAPTER和Prefix都不错,可能是都原封不动地使用了预训练的所有层,而对新加入的内容进行微调。
其它
改变prefix的长度,发现随着长度的增大,性能先上升、再下降
比较了finetune embedding layer的方法,发现效果很差
比较了改变指示符位置(插入到中间)的方法,发现效果有所下降,可能是因为插入在开始的位置,能够:“1. 更好的从x中进行编码 2. 更好的影响y生成的概率分布”
比较了不同的初始化方法,发现用原预训练词表中的任务相关的词,效果更好
这篇关于[文献阅读]——Prefix-Tuning: Optimizing Continuous Prompts for Generation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!