本文主要是介绍【眼科大模型】Ophtha-LLaMA2:视觉模型提取图像特征 + LLM基于特征生成眼底病变的诊断报告,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Ophtha-LLaMA2:视觉模型提取图像特征 + LLM基于特征生成眼底病变的诊断报告
- 提出背景
- 设计思路
- 选择大模型基座
- 生成诊断报告
论文:https://arxiv.org/pdf/2312.04906.pdf
提出背景
目标是开发一个全面的眼科模型,可以根据不同仪器的检查报告准确快速地诊断疾病。
Ophtha-LLaMA2,通过三种不同的眼科图像(OSA, OCT, CFP)进行诊断,并给出相应的诊断:
-
光学相干断层扫描(OCT):这种技术提供眼部组织的高分辨率横截面成像。
-
瞳孔面积分析仪(OSA):用于检测和评估睑板腺的功能和结构。
-
彩色眼底摄影(CFP):用于观察和记录眼底的状况。
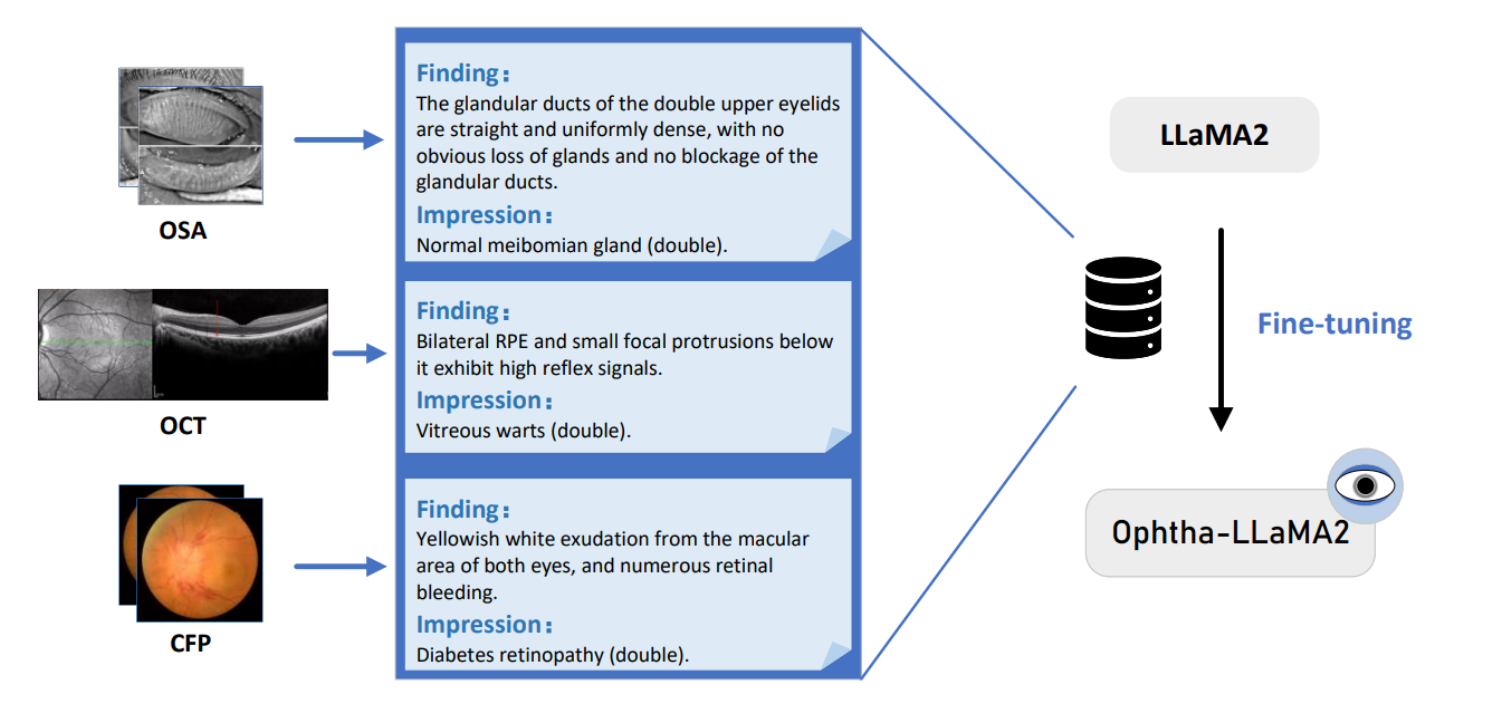
-
对于OSA图像(眼睑腺的图像),发现是上眼睑的腺体管道直且均匀密集,没有明显的腺体丢失也没有腺体管道的堵塞。是正常的睑板腺(双眼)。
-
对于OCT图像(光学相干断层扫描图像),发现是双侧视网膜色素上皮(RPE)和其下方小的突起,这些突起显示出高反射信号。是玻璃体疣(双眼)。
-
对于CFP图像(彩色眼底照相图像),发现是黄白色的渗出物从黄斑区域排出,两眼都有,并伴有多处视网膜出血。是糖尿病视网膜病变(双眼)。
具体到该模型能诊断的疾病种类,这将取决于模型训练时使用的数据集覆盖了多少种眼科疾病,以及模型设计时考虑了哪些诊断标准。
理论上,如果数据集足够广泛且包含多种疾病的代表性案例,模型就能学习到诊断这些疾病的能力。在实际应用中,模型的诊断能力还需要经过临床试验和验证。
效果测评
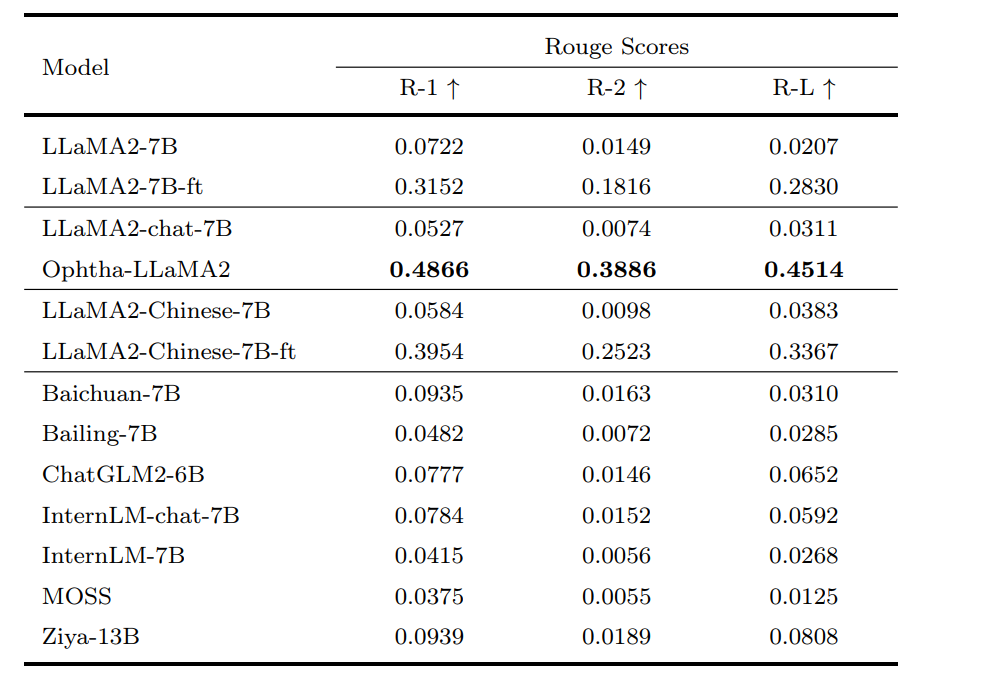
在主流大模型中,最强。
设计思路
-
数据准备:
- 从眼科数据库中收集大量眼底照片(CFP),每张照片都有详细的医生诊断报告。
- 使用预训练的计算机视觉模型(如ResNet、YOLO、医学方面视觉算法)从眼底照片中提取视网膜特征。
- 将图像特征和对应的医生诊断报告结合,生成一个训练数据集。
-
模型训练与微调:
- 使用收集的数据集对Ophtha-LLaMA2模型进行领域适应性微调,特别关注眼底病变的特征和相关术语。
- 通过多任务学习策略,让模型学习如何从视网膜特征生成结构化的诊断文本。
-
推理与报告生成:
- 当收到新的眼底照片时,模型首先使用同样的计算机视觉模型(ResNet、YOLO、医学方面视觉算法)提取图像特征。
- 然后,Ophtha-LLaMA2基于这些特征生成一份详细的诊断报告,报告中包含可能的病变类型、严重程度和建议的后续步骤。
-
评估与验证:
- 通过与眼科医生的诊断报告进行对比,评估模型生成报告的准确性和可靠性。
- 采用匿名化的真实患者数据进行测试,以确保评估的真实性和合规性。
-
反馈循环:
- 根据医生的反馈和模型在实际应用中的表现,不断调整和优化模型的性能。
选择大模型基座
眼科数据的特点是高度专业化和细节丰富,这就要求模型能够处理和理解长距离依赖关系,并且在训练和推理过程中保持高效和准确。
假设我们的目标是开发一个能够根据眼底图像生成详细文本描述的模型,这种描述能够帮助眼科医生快速了解患者的可能病变情况。
为什么选取LLaMA2 ?
-
RMSNorm层:增加 RMSNorm 层有助于模型在训练过程中保持更稳定的梯度流,这对于训练深层模型尤为重要,因为它可以减少训练过程中的梯度消失或爆炸问题。
-
RoPE位置编码:使用 RoPE 增强了模型对长距离依赖的理解,这在处理医学图像描述时特别重要,因为细微的病变特征及其在文本描述中的正确表达往往需要对图像上下文的全面理解。
-
KV Cache和GQA机制:引入 KV Cache 可以减少重复计算,提高模型运行效率;而 GQA(Grouped Query Attention)机制则通过对注意力查询进行分组处理,提高了模型处理复杂查询时的精度和效率。
通过这些结构,模型现在能够更准确地从眼底图像中识别出细小的病变特征,并将这些特征准确地映射到专业的医学术语上,生成的文本描述不仅准确,而且包含了丰富的细节,为医生提供了更有价值的信息。
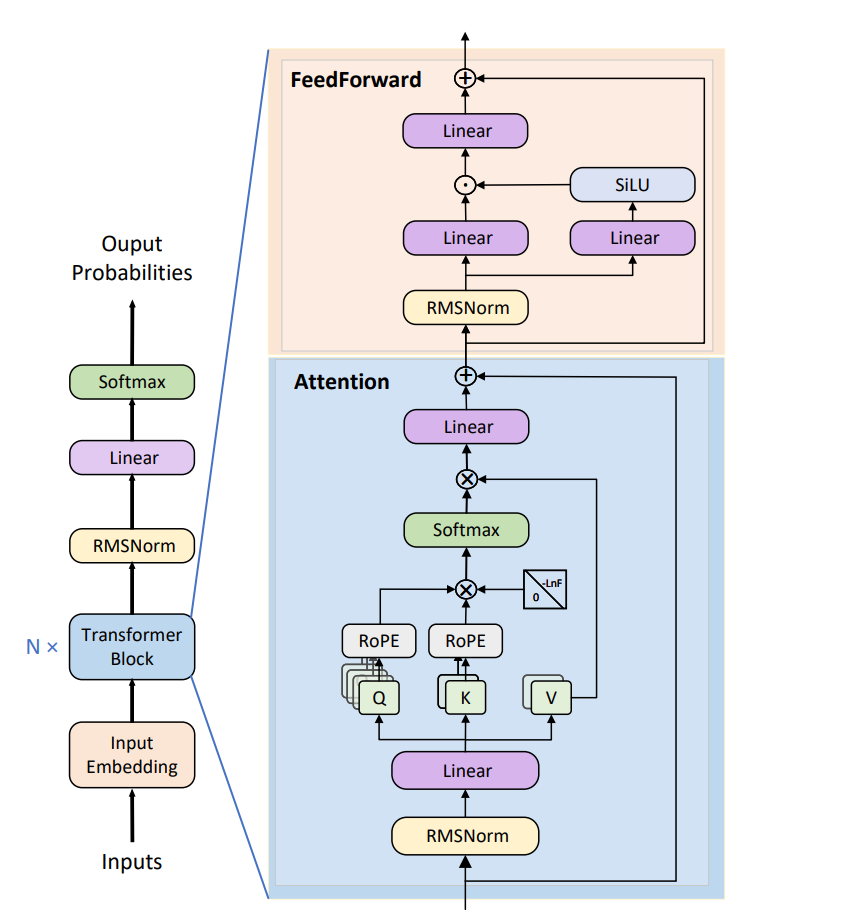
-
Input Embedding: 这是模型接收输入的第一层,将输入词或标记转换为嵌入向量。
-
Transformer Block: 这是模型核心,通常由多个相同的块堆叠而成(在图中以 “N x” 表示)。每个块通常包含两个主要部分:多头自注意力机制(Attention)和前馈神经网络(FeedForward)。
-
RMSNorm: 根源均方归一化(Root Mean Square Layer Normalization)是一种归一化技术,用于在Transformer块的不同层之间稳定训练。它在多头自注意力和前馈网络之前被应用。
-
RoPE: 相对位置编码(Relative Positional Encoding)是一种用于捕捉序列中元素间相对位置关系的技术。
-
Softmax: 在自注意力机制中使用,用于将注意力分数转换为概率分布。
-
FeedForward Network: 包含线性层和激活函数,通常在经过自注意力机制处理后进一步转换特征。
-
Output Probabilities: 最后的输出层,通常是线性层后跟一个Softmax函数,用于将Transformer的输出转换为预测概率。
生成诊断报告
生成适用于LLMs的完整提示:
- 例子:为模型设计提示,如“根据以下OCT和CFP图像数据,生成病人的眼科诊断报告”,引导模型专注于关键信息。
利用LLMs的文本摘要能力生成医疗报告的诊断部分:
- 例子:模型分析输入的图像描述和检查结果,自动生成一份包含病变类型、推荐治疗方法的诊断报告摘要。
大模型的摘要能力是无敌的好。
这篇关于【眼科大模型】Ophtha-LLaMA2:视觉模型提取图像特征 + LLM基于特征生成眼底病变的诊断报告的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





