llama2专题

一文看懂Llama2:原理、模型及训练
#llama Llama2(Language Learning and Understanding Model Architecture 2)是一个由Meta AI(原Facebook AI)开发的自然语言处理模型。这款模型的目标是通过深度学习技术来实现高效的自然语言理解和生成。本文将从原理、模型结构和训练方法三个方面深入探讨Llama2。 一、原理 Llama2的核心原理是基于变压器(Tr

深入Llama2:掌握未来语言模型的秘密
Llama2是一个基于Transformer架构的大型语言模型,它旨在处理和理解大规模的文本数据。作为技术人员,了解Llama2的工作原理、模型结构和训练方法对于有效利用该模型至关重要。本文将详细介绍Llama2的基本概念、主要作用、使用方法及注意事项。 一、简介 1. Llama2是什么? Llama2是一个大型的自回归的稀疏Transformer语言模型,由Meta AI发布。它基于Tr
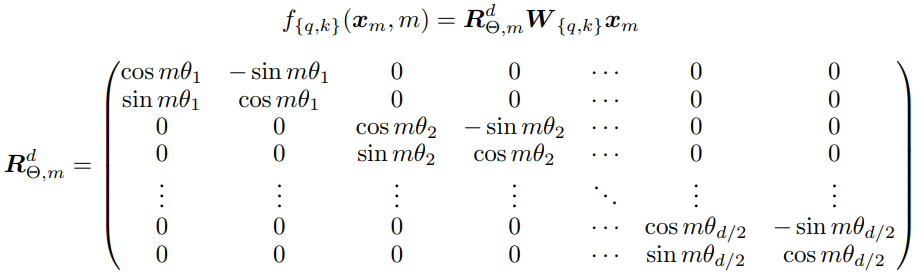
LLama2源码分析——Rotary Position Embedding分析
参考:一文看懂 LLaMA 中的旋转式位置编码(Rotary Position Embedding) 原理推导参考自上文,以下结合huggingface代码分析公式计算过程 1 旋转角度计算 计算公式如下,其中d为词嵌入维度,这部分和论文原文一样 θ j = 1000 0 − 2 ( j − 1 ) / d , j ∈ [ 1 , 2 , … , d / 2 ] \theta_j=1000
一文看懂llama2(原理模型训练)
Llama 2是一款强大的人工智能语言模型,它就像是一个超级聪明的聊天机器人,能够理解人类的语言,进行对话、回答问题、甚至创作故事。想象一下,你对着空气说话,空气不仅听懂了,还能回应你,这就是Llama 2的魅力所在。 原理:自然语言处理的魔法 Llama 2的核心原理基于深度学习,尤其是自然语言处理技术。想象一下,模型就像一个巨大的图书馆,里面存放着海量的书籍(这里是互联网上的文本数据)。模
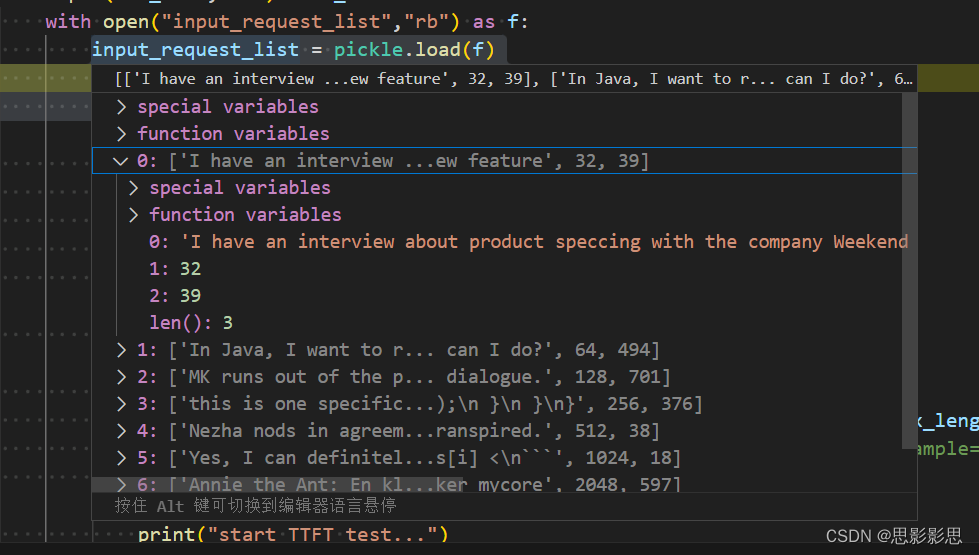
05-28 周二 TTFT, ITL, TGS 计算过程以及LLama2推理代码调试过程
05-28 周二 LLama2推理代码调试过程 时间版本修改人描述2024年5月28日15:03:49V0.1宋全恒新建文档 简介 本文主要用于求解大模型推理过程中的几个指标: 主要是TTFT,ITL, TGS 代码片段 import osdata_dir = "/workspace/models/"model_name = "Llama-2-7b-hf"data_di
大模型额外篇章二:基于chalm3或Llama2-7b训练酒店助手模型
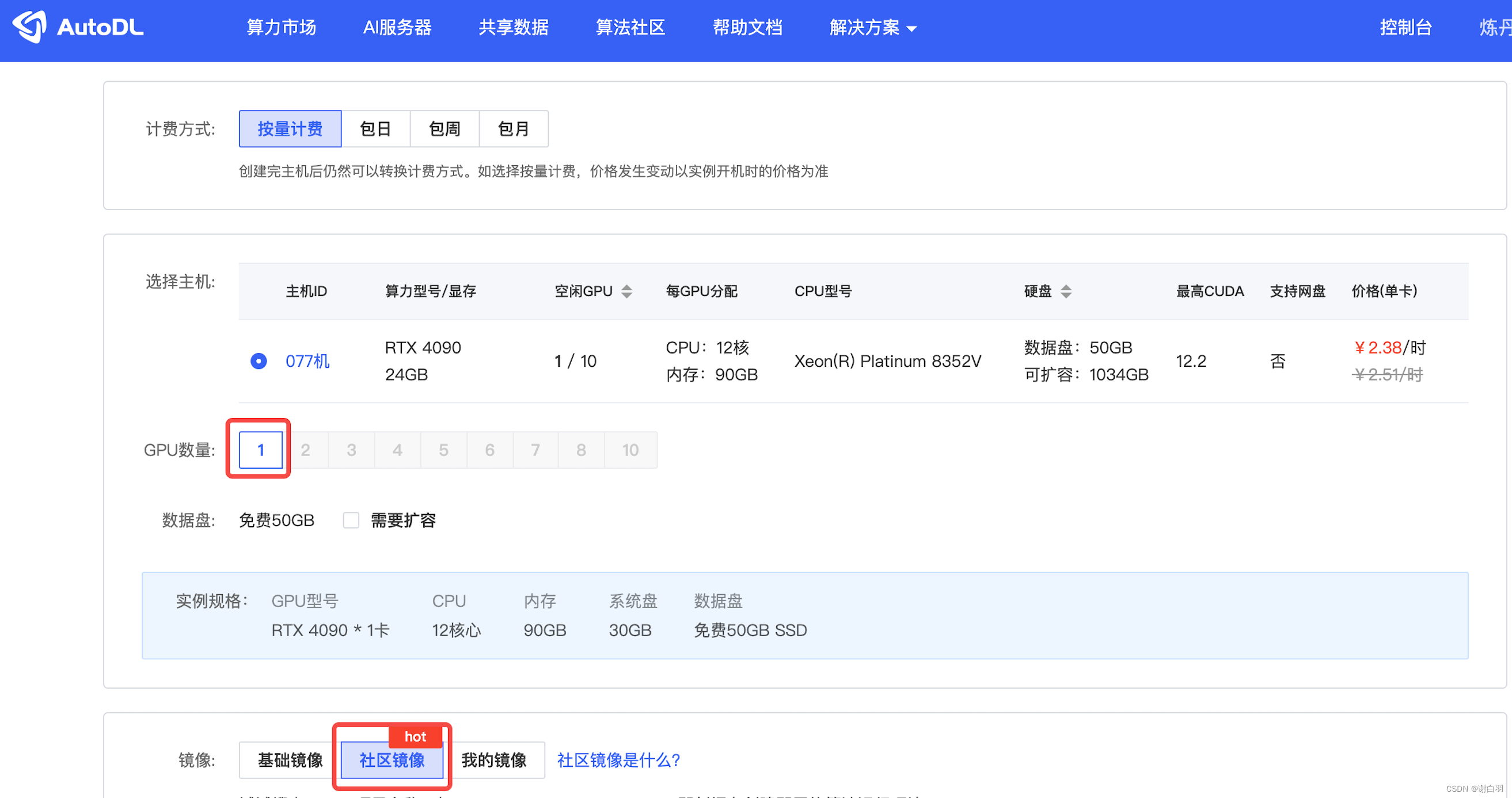
文章目录 一、代码部分讲解二、实际部署步骤(CHALM3训练步骤)1)注册AutoDL官网实名认证2)花费额度挑选GPU3)准备实验环境4)开始执行脚本5)从浏览器访问6)可以开始提问7)开始微调模型8)测试训练后的模型 三、基于Llama2-7b的训练四、额外补充1)修改参数后2)如果需要访问科学的彼岸 一、代码部分讲解 二、实际部署步骤(CHALM3训练步骤) 1)注册
如何在huggingface上申请下载使用llama2/3模型
1. 在对应模型的huggingface页面上提交申请 搜索对应的模型型号 登录huggingface,在模型详情页面上,找到这个表单,填写内容,提交申请。需要使用梯子,country填写梯子的位置吧(比如美国) 等待一小时左右,会有邮件通知。 创建access token 在huggingface上登录后,点击头像,选择setting,点击左侧的access tokens,新建一个,然

用 C 语言进行大模型推理:探索 llama2.c 仓库(二)
文章目录 前提如何构建一个Transformer Model模型定义模型初始化 如何构建tokenzier 和 sampler如何进行推理总结 前提 上一节我们介绍了llama2.c中如何对hugging face的权重进行处理,拿到了llama2.c想要的权重格式和tokenizer.bin格式。这一节我们分析下在llama2.c如何解析这两个.bin文件。这一节的所有代码都在
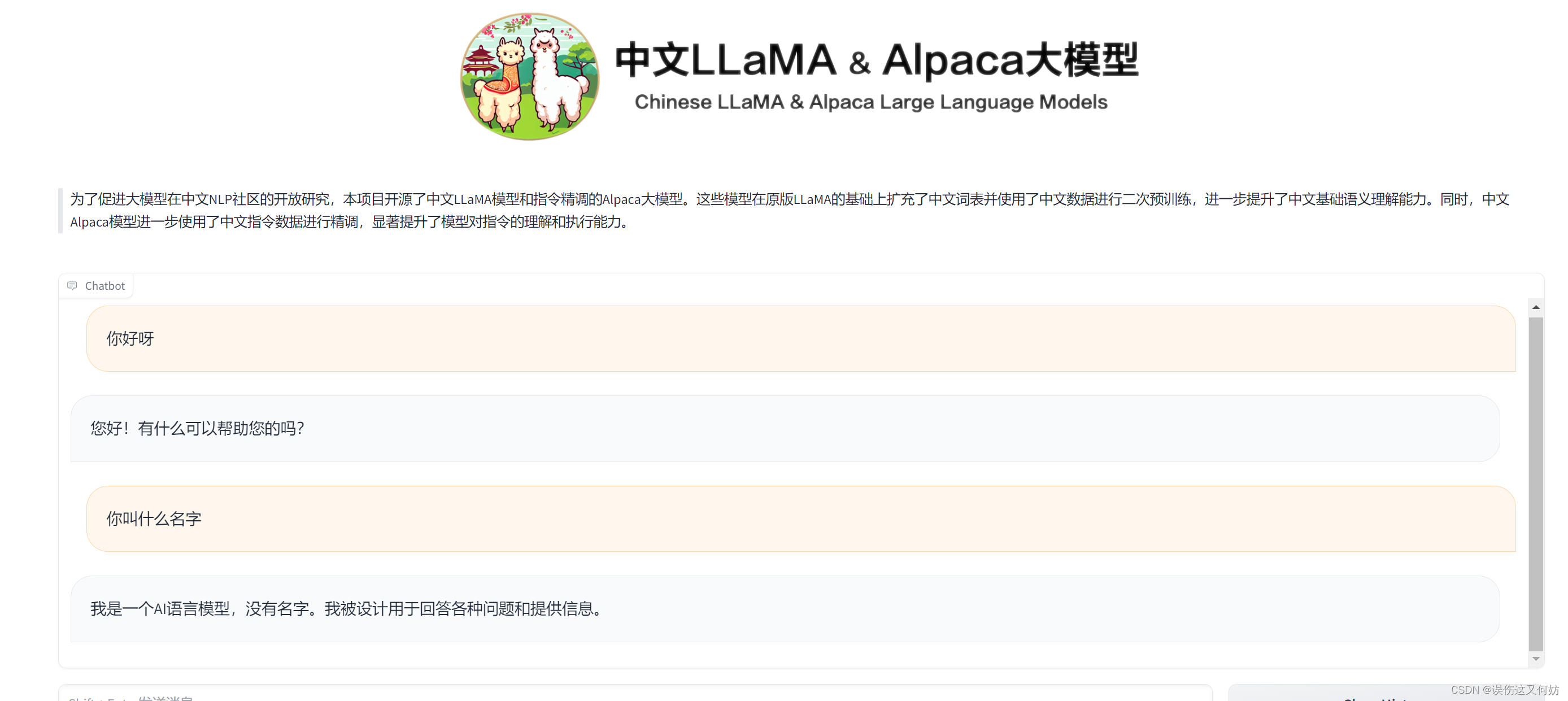
liunx服务器部署Llama2大模型
模型:Llama2-chat-13B-Chinese-50W 01 下载安装 Llama2 模型 Huggingface在国内是访问不了的,需要使用代理。在这里推荐使用 clash-for-liunx 配置代理。 安装 git-lfs,用于大文件下载 sudo apt-get install git-lfsgit lfs install Huggingface 下载 Llama2
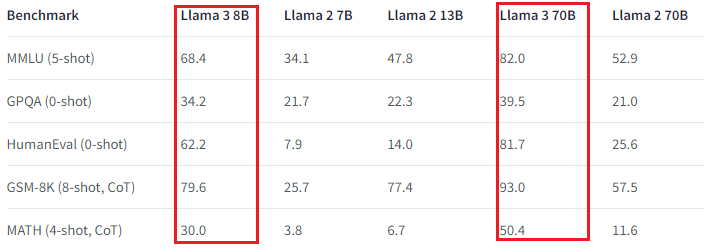
llama2 与 llama3比较
Llama 3 刚刚在4月18号推出,距 Llama 2 发布正好 9 个月。它已经可以在 Meta 网站上进行聊天,可以从 Huggingface 以 safetensors 或 GGUF 格式下载。 llama 2 与 llama3 比较 1. 模型输出(model output) llama 2 输出只能是文本(Models generate text only.) ,llama
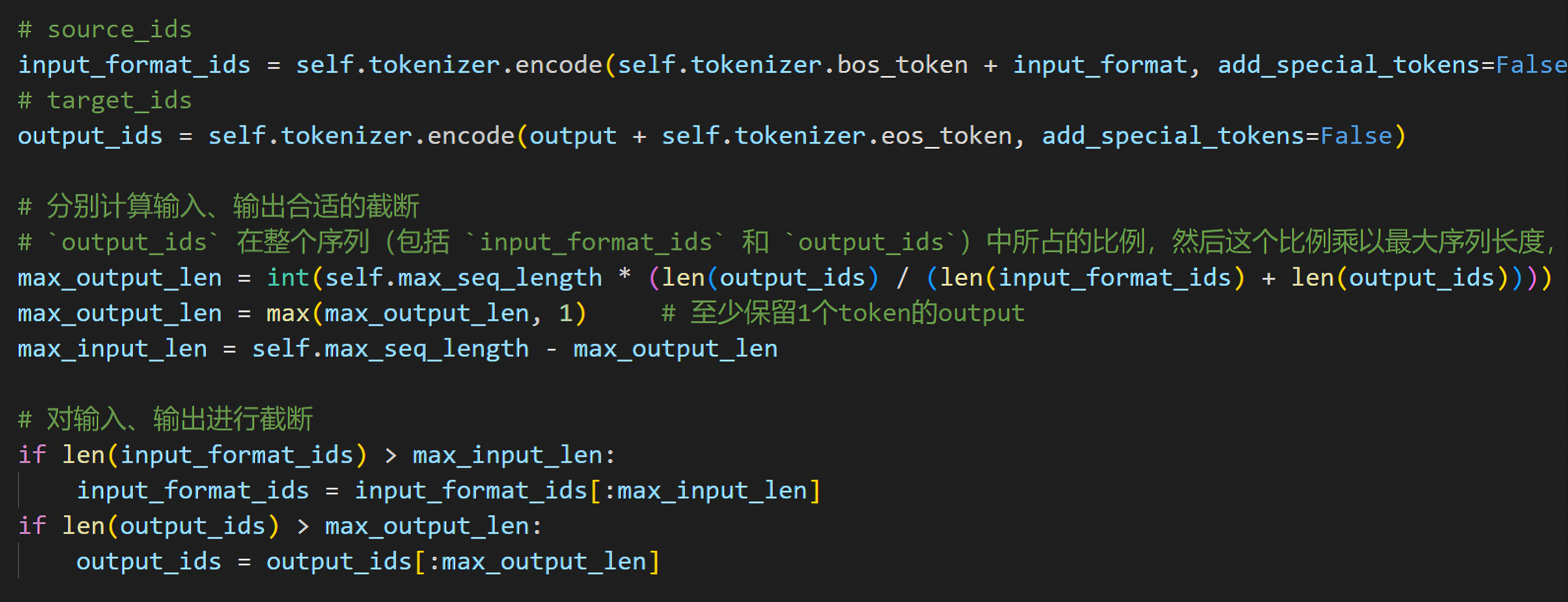
七月论文审稿GPT第4.5版:通过15K条paper-review数据微调Llama2 70B(含各种坑)
前言 当我们3月下旬微调完Mixtral 8x7B之后(更多详见:七月论文大模型:含论文的审稿、阅读、写作、修订 ),下一个想微调的就是llama2 70B 因为之前积攒了不少微调代码和微调经验,所以3月底apple便通过5K的paper-review数据集成功微调llama2 70B,但过程中也费了不少劲考虑到最后的成功固然令人欣喜,但真正让一个人或一个团队快速涨经验的还是那些在训练过程中走

Docker一键快速私有化部署(Ollama+Openwebui) +AI大模型(gemma,llama2,qwen)20240417更新
几行命令教你私有化部署自己的AI大模型,每个人都可以有自己的GTP 第一步:安装Docker(如果已经有了可以直接跳第二步) ####下载安装Dockerwget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O/etc/yum.repos.d/docker-ce.repo##更新yum软件包索引y
Trl SFT: llama2-7b-hf使用QLora 4bit量化后ds zero3加上flash atten v2单机多卡训练(笔记)
目录 一、环境 1.1、环境安装 1.2、安装flash atten 二、代码 2.1、bash脚本 2.2、utils.py 注释与优化 2.3、train.py 注释与优化 2.4、模型/参数相关 2.4.1、量化后的模型 2.4.1.1 量化后模型结构 2.4.1.2 量化后模型layers 2.4.2
在个人电脑上,本地部署llama2-7b大模型
文章目录 前言原理效果实现 前言 我想也许很多人都想有一个本地的ai大语言模型,当然如果能够摆脱比如openai,goole,baidu设定的语言规则,可以打破交流界限,自由交谈隐私之类的,突破规则,同时因为部署在本地也不担心被其他人知道,那最好不过了 那究竟有没有这样的模型呢? llama2-7b模型就可以 同时你也可以为他设定角色, 这是一个支持可进行身份定义的本地语言模型
Trl: llama2-7b-hf使用QLora 4bit量化后ds zero3加上flash atten v2单机多卡训练(笔记)
目录 一、环境 1.1、环境安装 1.2、安装flash atten 二、代码 2.1、bash脚本 2.2、utils.py 注释与优化 2.3、train.py 注释与优化 2.4、模型/参数相关 2.4.1、量化后的模型 a) 量化后模型结构 b) 量化后模型layers 2.4.2、参数
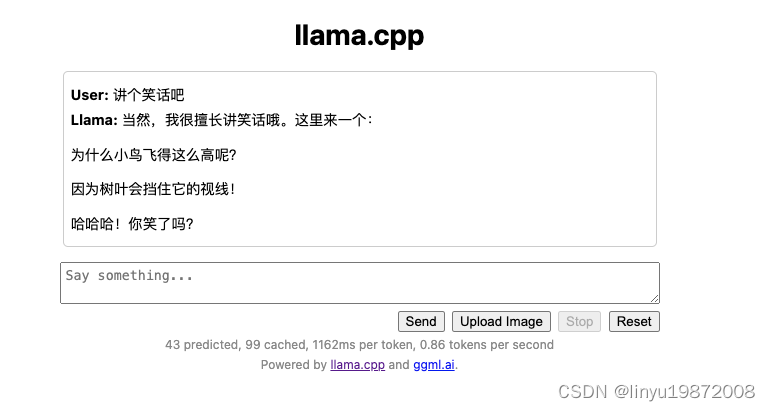
Llama2模型本地部署(Mac M1 16G)
环境准备 环境:Mac M1 16G、Conda Conda创建环境配置 使用Anaconda-Navigator创建python 3.8环境 切换到新建的conda环境: conda activate llama38 llama.cpp 找一个目录,下载llama.cpp git clone https://github.com/ggerganov/llama.cpp

llama2.c与chinese-baby-llama2语言模型本地部署推理
文章目录 简介Github文档克隆源码英文模型编译运行中文模型(280M)main函数 简介 llama2.c是一个极简的Llama 2 LLM全栈工具,使用一个简单的 700 行 C 文件 ( run.c ) 对其进行推理。llama2.c涉及LLM微调、模型构建、推理端末部署(量化、硬件加速)等众多方面,是学习研究Open LLM的很好切入点。 Github http
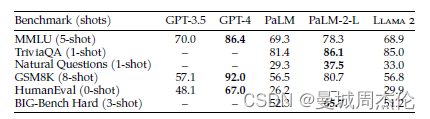
自然语言处理: 第二十一章大模型基底之llama2
文章地址: LLaMA:OpenandEfficient Foundation Language Models 项目地址: meta-llama/llama: Inference code for Llama models (github.com) 前言 在LLaMa1的基础之上有兴趣的可以看看我上一篇博客自然语言处理: 第二十一章大模型基底之llama1。Meta 又继续推出了LLaMa2
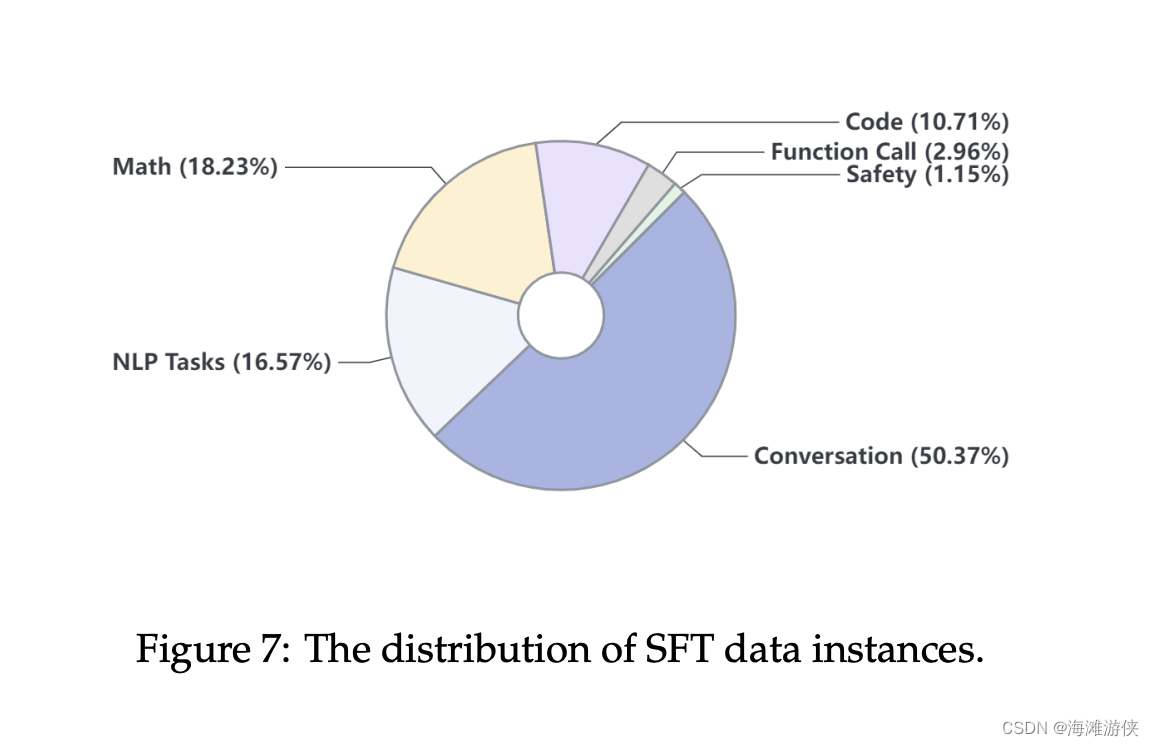
GPT3, llama2, InternLM2技术报告对比
GPT3(September 22, 2020)是大语言应用的一个milestone级别的作品,Llama2(February 2023)则是目前开源大模型中最有影响力的作品,InternLM2(2023.09.20)则是中文比较有影响力的作品。 今天结合三篇技术汇报,尝试对比一下这三个方案的效果。 参考GPT3,关于模型(Model and Architectures)的介绍分为了几个部

1320亿参数,性能超LLaMA2、Grok-1!开源大模型DBRX
3月28日,著名数据和AI平台Databricks在官网正式开源大模型——DBRX。 DBRX是一个专家混合模型(MoE)有1320亿参数,能生成文本/代码、数学推理等,有基础和微调两种模型。 根据DBRX在MMLU、HumanEval和 GSM8K公布的测试数据显示,不仅性能超过了LLaMA2-70B和马斯克最近开源的Grok-1,推理效率比LLaMA2-70B快2倍,总参数却只有Grok-

【LLM】LLama2模型(RMSNorm、SwiGLU、RoPE位置编码)
note 预训练语言模型除了自回归(Autoregressive)模型GPT,还有自编码模型(Autoencoding)BERT[1]、编-解码(Encoder-Decoder)模型BART[67],以及融合上述三种方法的自回归填空(Autoregressive Blank Infilling)模型GLM(General Language Model)[68]。ChatGPT的出现,使得目前几乎
【AI】实现在本地Mac,Windows和Mobile上运行Llama2模型
【AI】实现在本地Mac,Windows和Mobile上运行Llama2模型 目录 【AI】实现在本地Mac,Windows和Mobile上运行Llama2模型**Llama 2模型是什么?****技术规格和能力****Llama 2中的专门模型****在人工智能开发中的意义** **如何在本地使用Llama 2运行Llama.cpp****Llama.cpp的设置** 如何在Mac上
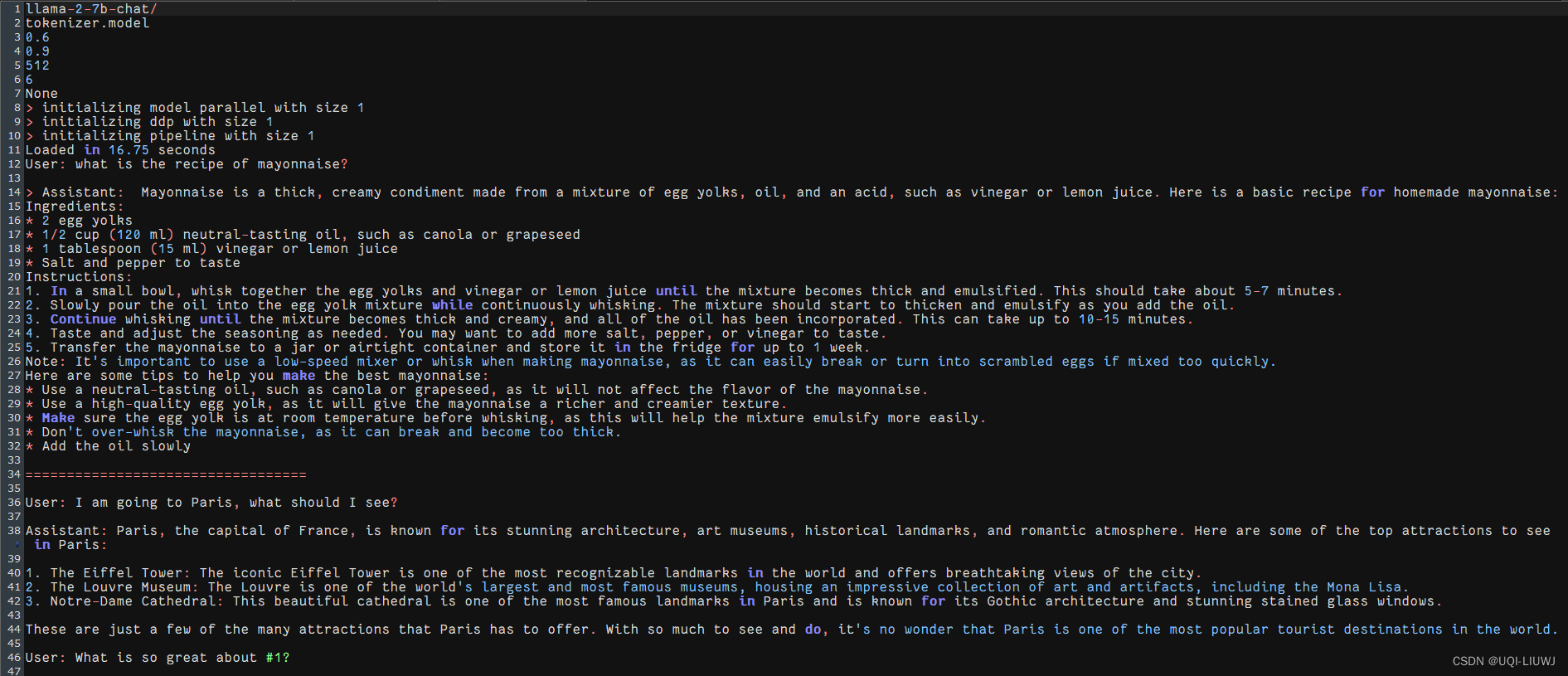
llamma笔记:部署Llama2
1 申请Llama2 许可 Download Llama (meta.com) 地址似乎不能填中国 1.1 获取url 提交申请后,填的那个邮箱会受到一封meta发来的邮件,打码部分的url,之后会用得上 2 ubuntu/linux 端部署Llama2 2.1 git clone Llama2的github 仓库 bash git clone https://githu
【个人开发】llama2部署实践(四)——llama服务接口调用方式
1.接口调用 import requestsurl = 'http://localhost:8000/v1/chat/completions'headers = {'accept': 'application/json','Content-Type': 'application/json'}data = {'messages': [{'content': 'You are a helpf
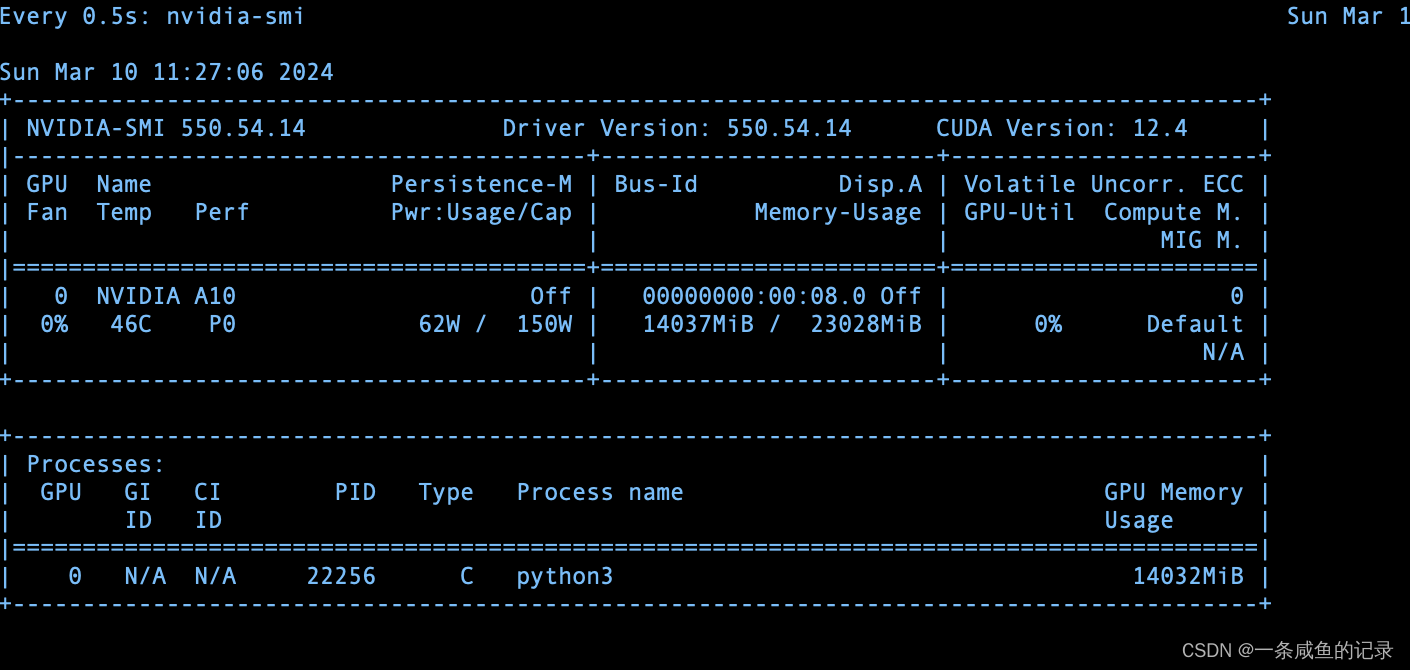
【个人开发】llama2部署实践(三)——python部署llama服务(基于GPU加速)
1.python环境准备 注:llama-cpp-python安装一定要带上前面的参数安装,如果仅用pip install装,启动服务时并没将模型加载到GPU里面。 # CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install llama-cpp-pythonCMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMA