本文主要是介绍Llama2模型本地部署(Mac M1 16G),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
环境准备
环境:Mac M1 16G、Conda
Conda创建环境配置
使用Anaconda-Navigator创建python 3.8环境
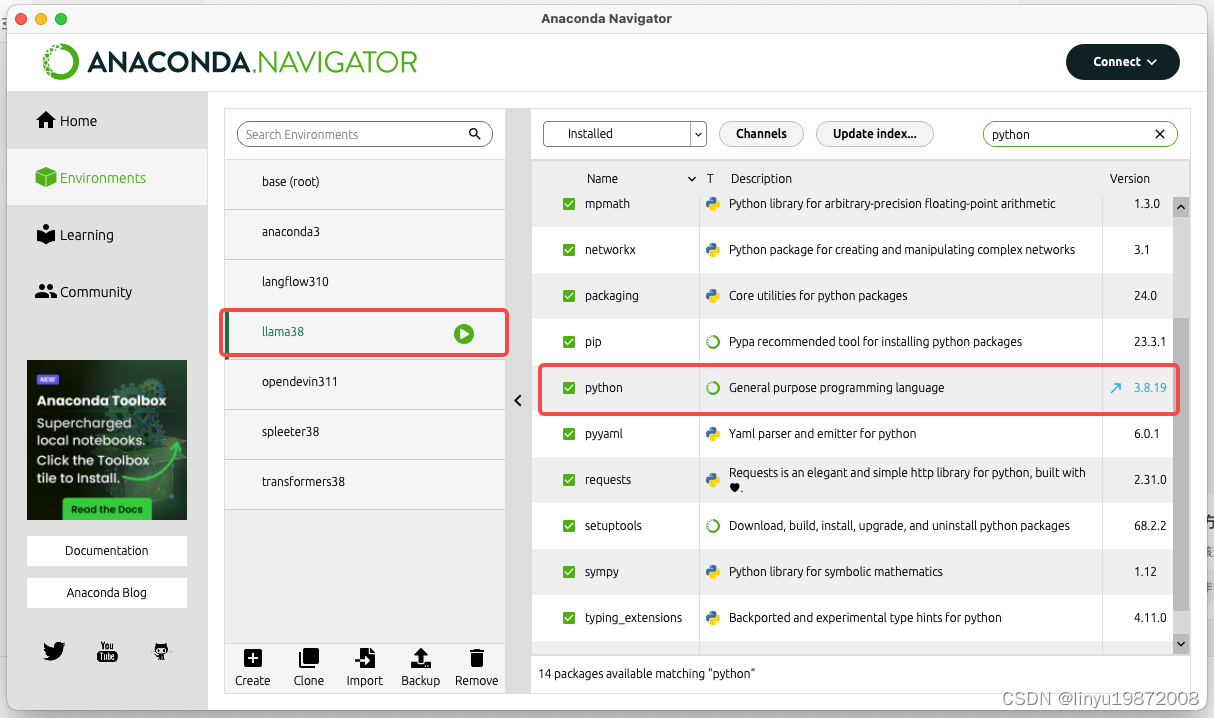
切换到新建的conda环境:
conda activate llama38
llama.cpp
找一个目录,下载llama.cpp
git clone https://github.com/ggerganov/llama.cpp进入llama.cpp目录
cd llama.cpp安装依赖环境
pip install -r requirements.txt编译代码
LLAMA_METAL=1 make下载中文模型 chinese-alpaca-2-7b-64k-hf,可以去下面的地址查找GitHub - ymcui/Chinese-LLaMA-Alpaca-2: 中文LLaMA-2 & Alpaca-2大模型二期项目 + 64K超长上下文模型 (Chinese LLaMA-2 & Alpaca-2 LLMs with 64K long context models)
我这边选用的7b模型,再大就不好运行起来了
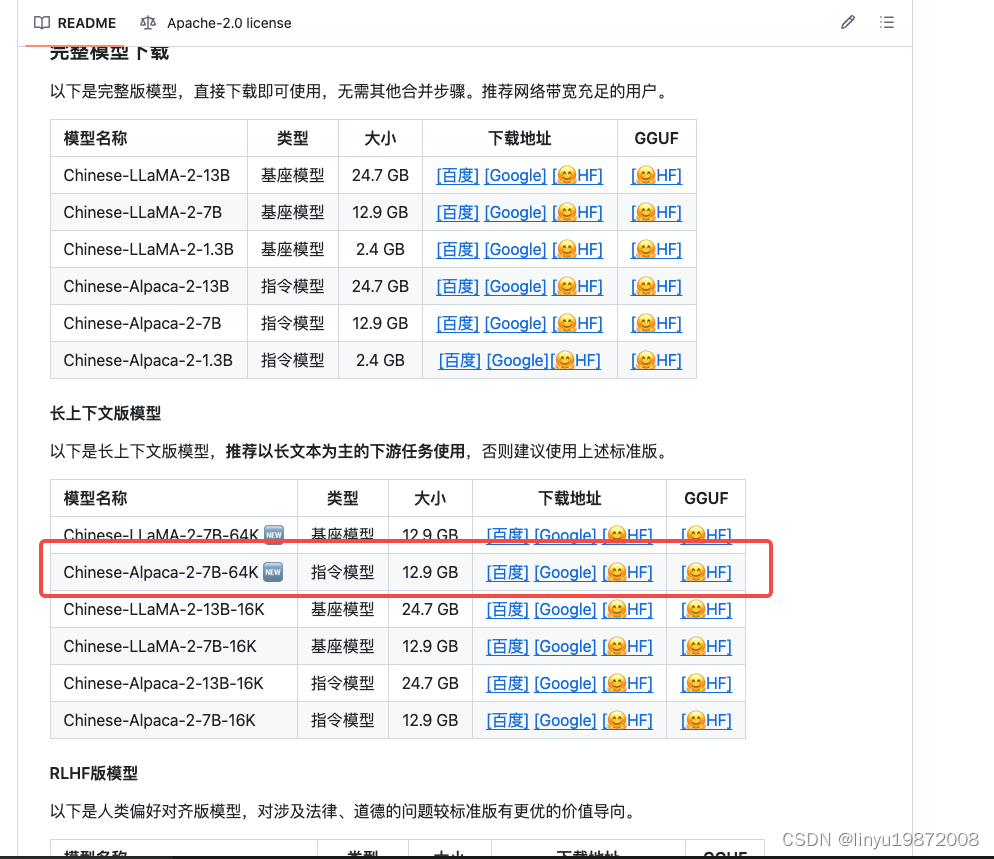
下载后放置在llama.cpp/models目录下

模型转换
python convert.py models/chinese-alpaca-2-7b-64k-hf/量化模型
./quantize ./models/chinese-alpaca-2-7b-64k-hf/ggml-model-f16.gguf ./models/chinese-alpaca-2-7b-64k-hf/ggml-model-q4_0.gguf q4_0Server方式启动, host和port可选, 不写则启动127.0.0.1 8080
./server --host 0.0.0.0 --port "$port" -m ./models/chinese-alpaca-2-7b-64k-hf/ggml-model-q4_0.gguf -c 4096 -ngl 1启动成功直接打开页面,我这边没有指定host和port,http://localhost:8080/
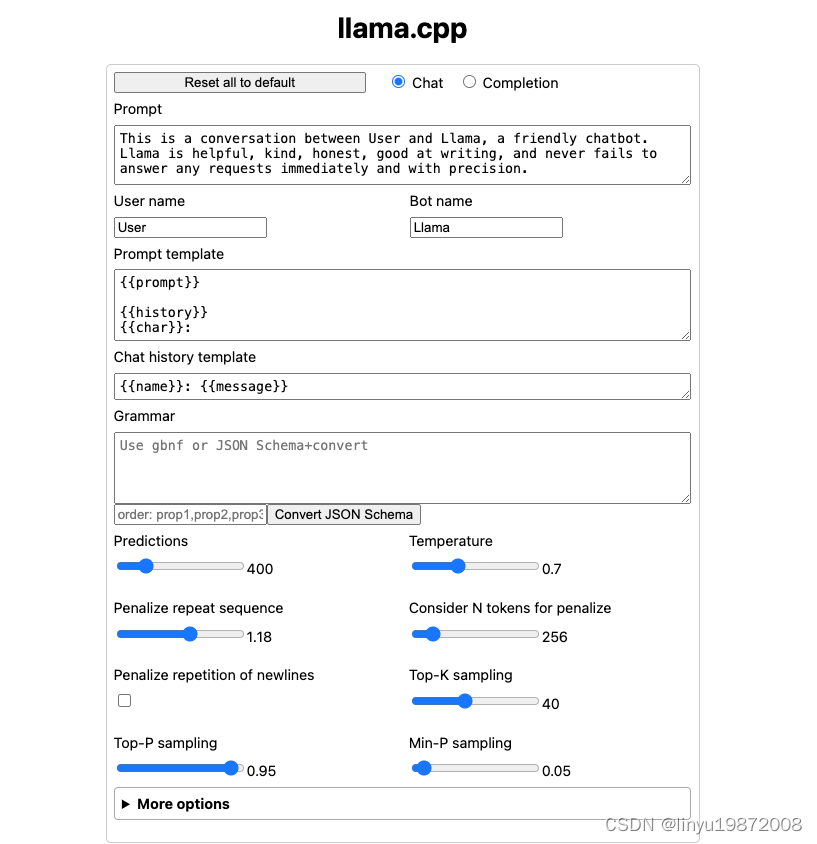
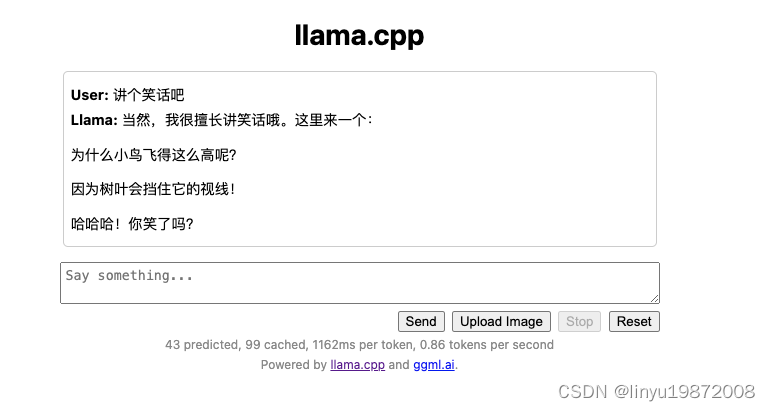
开始对话

这篇关于Llama2模型本地部署(Mac M1 16G)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








