本文主要是介绍【RT-DETR有效改进】大核注意力 | LSKAttention助力极限涨点,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、本文介绍
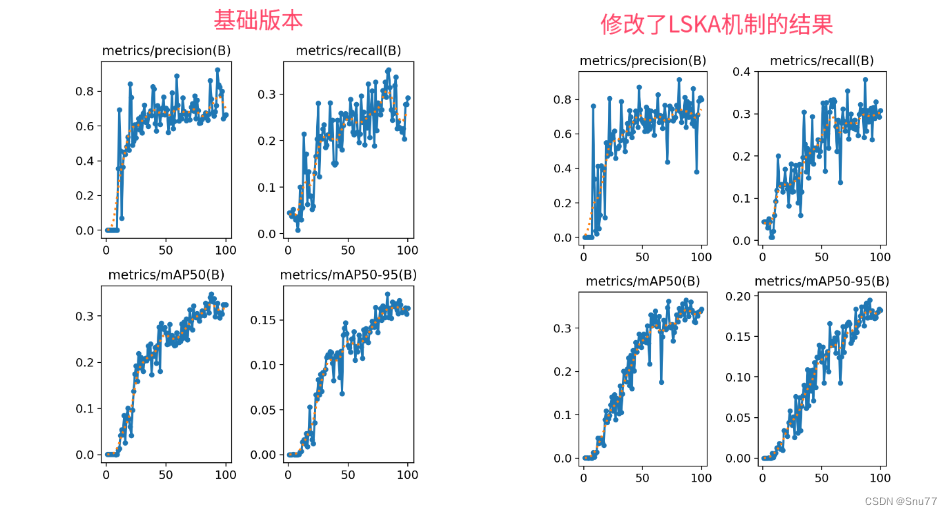
在这篇文章中,我们将讲解如何将LSKAttention大核注意力机制应用于RT-DETR,以实现显著的性能提升。首先,我们介绍LSKAttention机制的基本原理,它主要通过将深度卷积层的2D卷积核分解为水平和垂直1D卷积核,减少了计算复杂性和内存占用。接着,我们介绍将这一机制整合到RT-DETR的方法,以及它如何帮助提高处理大型数据集和复杂视觉任务的效率和准确性。本文改进是基于ResNet18、ResNet34、ResNet50、ResNet101,文章中均以提供,本专栏的改进内容全网独一份深度改进RT-DETR非那种无效Neck部分改进,同时本文的改进也支持主干上的即插即用,本文内容也支持PP-HGNetV2版本的修改。
这篇关于【RT-DETR有效改进】大核注意力 | LSKAttention助力极限涨点的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






