lskattention专题

YOLOv9改进策略 | 添加注意力篇 | LSKAttention大核注意力机制助力极限涨点 (附多个位置添加教程)
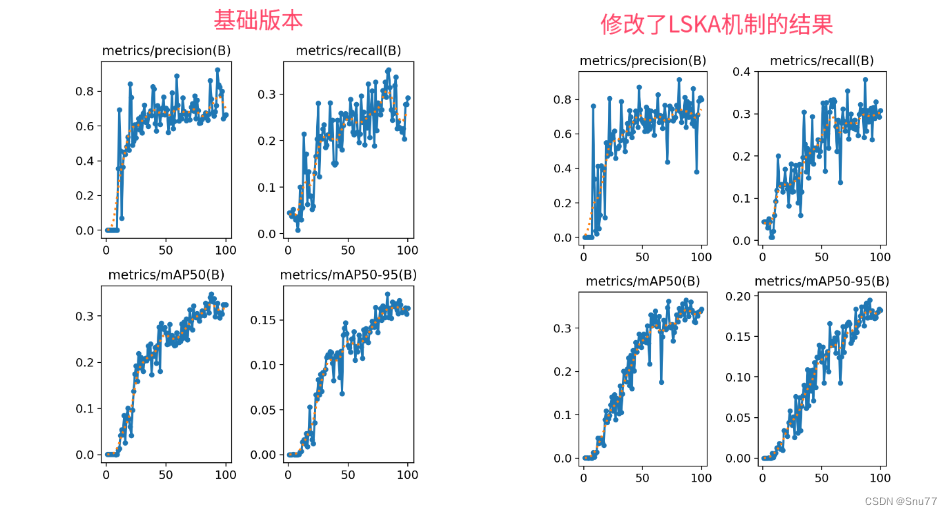
一、本文介绍 本文给大家带来的改进机制是LSKAttention大核注意力机制应用于YOLOv9。它的主要思想是将深度卷积层的2D卷积核分解为水平和垂直1D卷积核,减少了计算复杂性和内存占用。接着,我们介绍将这一机制整合到YOLOv9的方法,以及它如何帮助提高处理大型数据集和复杂视觉任务的效率和准确性。本文还将提供代码实现细节和使用方法,展示这种改进对目标检测等方面的效果。通过实验YOLOv
【RT-DETR有效改进】大核注意力 | LSKAttention助力极限涨点
一、本文介绍 在这篇文章中,我们将讲解如何将LSKAttention大核注意力机制应用于RT-DETR,以实现显著的性能提升。首先,我们介绍LSKAttention机制的基本原理,它主要通过将深度卷积层的2D卷积核分解为水平和垂直1D卷积核,减少了计算复杂性和内存占用。接着,我们介绍将这一机制整合到RT-DETR的方法,以及它如何帮助提高处理大型数据集和复杂视觉任务的效率和准确性。本文改进是

YOLOv8改进 | 2023 | LSKAttention大核注意力机制助力极限涨点
论文地址:官方论文地址 代码地址:官方代码地址 一、本文介绍 在这篇文章中,我们将讲解如何将LSKAttention大核注意力机制应用于YOLOv8,以实现显著的性能提升。首先,我们介绍LSKAttention机制的基本原理,它主要通过将深度卷积层的2D卷积核分解为水平和垂直1D卷积核,减少了计算复杂性和内存占用。接着,我们介绍将这一机制整合到YOLOv8的方法,以及它如何帮助