大核专题
新一代大核卷积反超ViT和ConvNet!同参数量下性能、精度、速度完胜
大核卷积网络是CNN的一种变体,也是深度学习领域的一种重要技术,它使用较大的卷积核来处理图像数据,以提高模型对视觉信息的理解和处理能力。 这种类型的网络能够捕捉到更多的空间信息,因为它的大步长和大感受野可以一次性覆盖图像的更多区域。比如美团提出的PeLK网络,内核大小可以达到101x101,同参数量下性能反超 ViT,目前已被CVPR 2024收录。 更值得一提的,大核卷积网络不仅在性能上有所

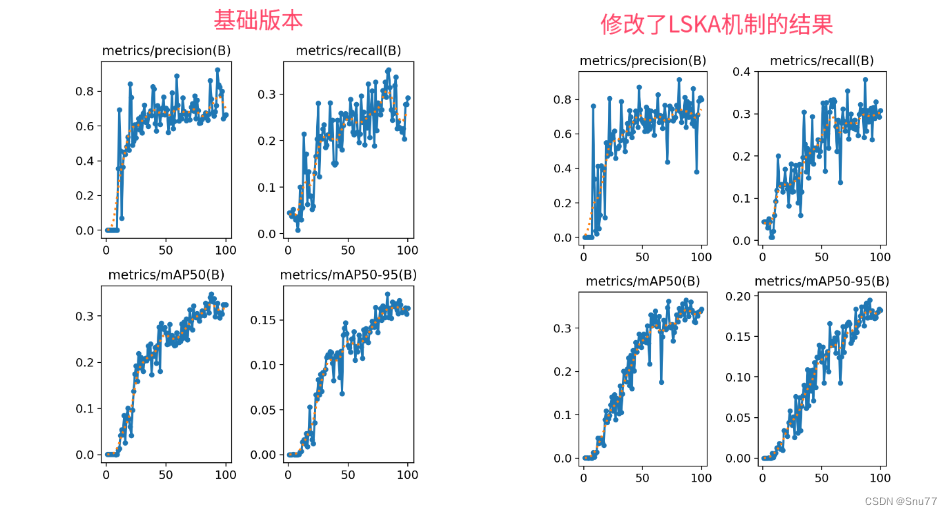
YOLOv9改进策略 | 添加注意力篇 | LSKAttention大核注意力机制助力极限涨点 (附多个位置添加教程)
一、本文介绍 本文给大家带来的改进机制是LSKAttention大核注意力机制应用于YOLOv9。它的主要思想是将深度卷积层的2D卷积核分解为水平和垂直1D卷积核,减少了计算复杂性和内存占用。接着,我们介绍将这一机制整合到YOLOv9的方法,以及它如何帮助提高处理大型数据集和复杂视觉任务的效率和准确性。本文还将提供代码实现细节和使用方法,展示这种改进对目标检测等方面的效果。通过实验YOLOv

CVPR2024 | 大核卷积新高度101x101,美团提出PeLK
https://arxiv.org/pdf/2403.07589.pdf 本文概述 最近,一些大核卷积网络以吸引人的性能和效率进行了反击。然而,考虑到卷积的平方复杂度,扩大内核会带来大量的参数,而大量的参数会引发严重的优化问题。由于这些问题,当前的 CNN 妥协以条带卷积的形式扩展到 (即 + ),并随着内核大小的持续增长而开始饱和。 在本文中,我们深入研究解决这些重要问题,并探讨我们
【RT-DETR有效改进】大核注意力 | LSKAttention助力极限涨点
一、本文介绍 在这篇文章中,我们将讲解如何将LSKAttention大核注意力机制应用于RT-DETR,以实现显著的性能提升。首先,我们介绍LSKAttention机制的基本原理,它主要通过将深度卷积层的2D卷积核分解为水平和垂直1D卷积核,减少了计算复杂性和内存占用。接着,我们介绍将这一机制整合到RT-DETR的方法,以及它如何帮助提高处理大型数据集和复杂视觉任务的效率和准确性。本文改进是

Shift-ConvNets:具有大核效应的小卷积核
摘要 https://arxiv.org/pdf/2401.12736.pdf 最近的研究表明,Vision transformers (ViTs)的卓越性能得益于大的感受野。因此,大型卷积核设计成为使卷积神经网络(CNNs)再次变得出色的理想解决方案。然而,典型的大的卷积核被证明是对硬件不友好的操作,导致与各种硬件平台的兼容性降低。因此,简单地增大卷积核的大小是不明智的。在本文中,我们揭示了小
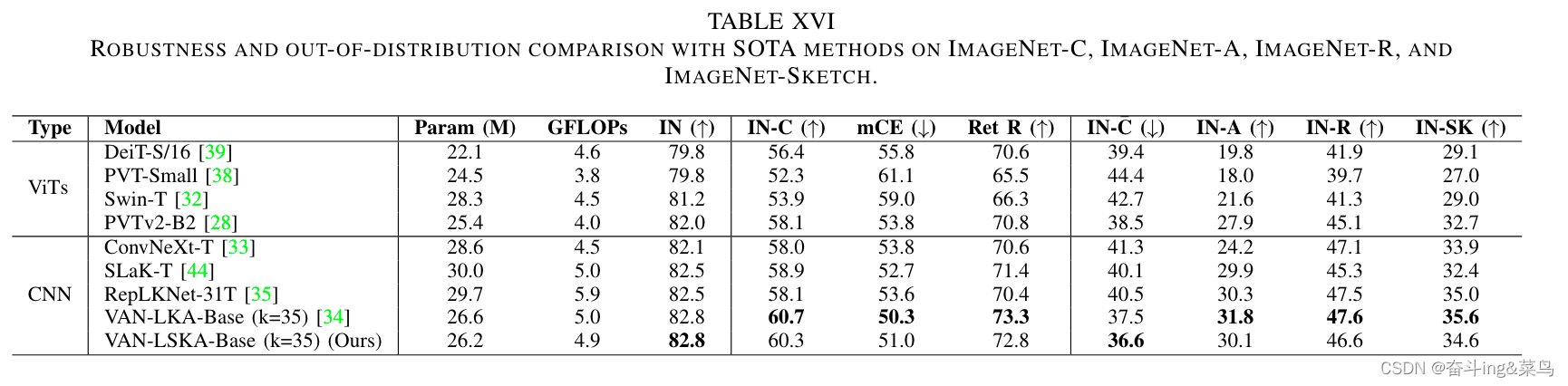
大可分离核注意力: 重新思考 CNN 中的大核注意力设计
今天刚读大可分离核注意力这篇论文,可与大家一起学习。感兴趣的可以下载论文看一下。 论文下载地址:https://arxiv.org/pdf/2309.01439.pdf 代码地址:https://github.com/StevenLauHKHK/Large-Separable-Kernel-Attention/blob/main/mmsegmentation/van.py 摘要 带有大内核注意力(
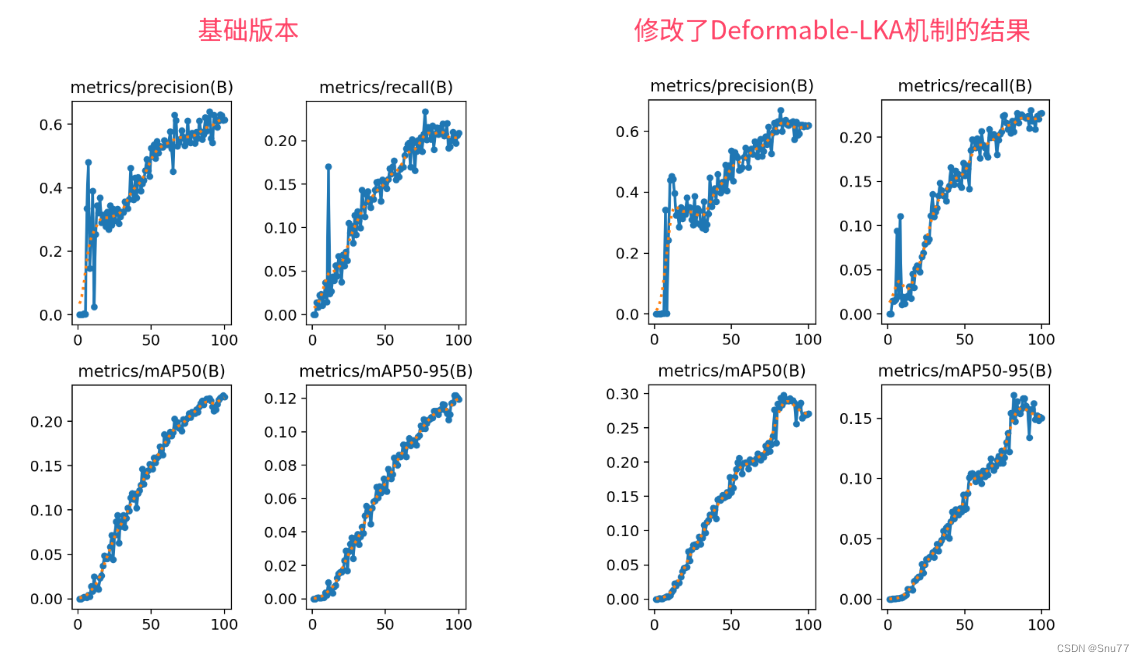
YOLOv5改进 | 注意力篇 | Deformable-LKA(DLKA)可变形的大核注意力(附多个位置添加教程)
一、本文介绍 本文给大家带来的改进内容是Deformable-LKA(可变形大核注意力)。Deformable-LKA结合了大卷积核的广阔感受野和可变形卷积的灵活性,有效地处理复杂的视觉信息。这一机制通过动态调整卷积核的形状和大小来适应不同的图像特征,提高了模型对目标形状和尺寸的适应性。在YOLOv5中,Deformable-LKA可以被用于提升对小目标和不规则形状目标的检测能力,特别是在复杂背

Android 主线程绑定 CPU 大核(提升应用整体性能)
在 Android 开发中,主线程是负责处理用户界面操作的线程。绑定 CPU 大核的作用是为主线程提供更高的计算性能和更快的响应速度。 通常情况下,Android 设备的 CPU 由多个小核和少量大核组成,小核主要负责处理低功耗的后台任务,而大核则拥有更高的性能和更大的计算能力。 通过绑定,主线程可以充分利用大核的计算能力,提升程序的运行速度和响应性能。这对于需要处理大量计算或需要实时更新界面

Android 主线程绑定 CPU 大核(提升应用整体性能)
在 Android 开发中,主线程是负责处理用户界面操作的线程。绑定 CPU 大核的作用是为主线程提供更高的计算性能和更快的响应速度。 通常情况下,Android 设备的 CPU 由多个小核和少量大核组成,小核主要负责处理低功耗的后台任务,而大核则拥有更高的性能和更大的计算能力。 通过绑定,主线程可以充分利用大核的计算能力,提升程序的运行速度和响应性能。这对于需要处理大量计算或需要实时更新界面
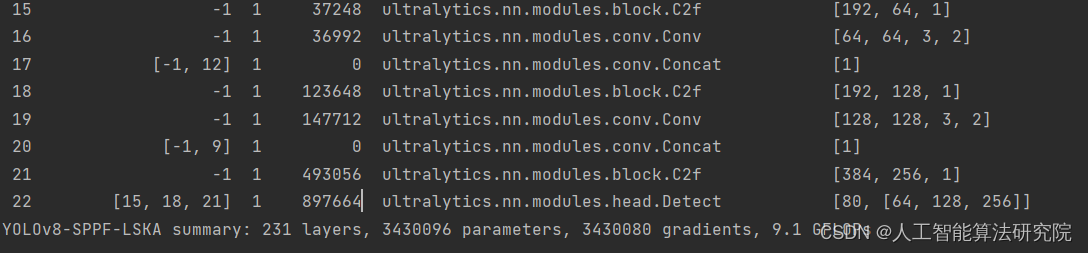
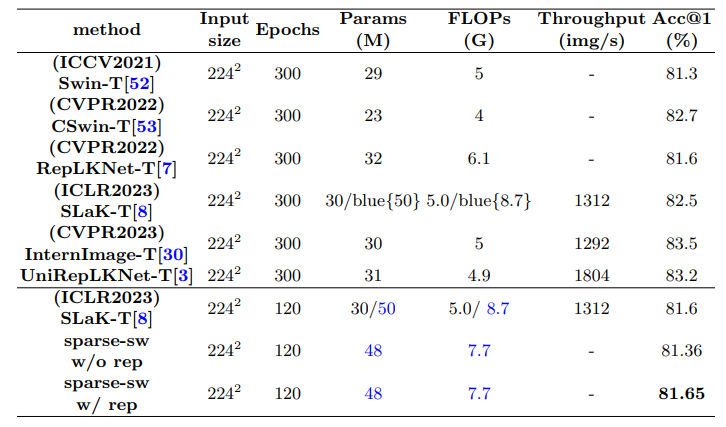
YOLOv8算法改进【NO.92】使用大核分离卷积注意力模块Large Separable Kernel Attention(LSKA)改进SPPF模块
前 言 YOLO算法改进系列出到这,很多朋友问改进如何选择是最佳的,下面我就根据个人多年的写作发文章以及指导发文章的经验来看,按照优先顺序进行排序讲解YOLO算法改进方法的顺序选择。具体有需求的同学可以私信我沟通: 第一,创新主干特征提取网络,将整个Backbone改进为其他的网络,比如这篇文章中的整个方法,直接将Backbone替换掉,理由是这种改进如果有效果,那么改进点就很
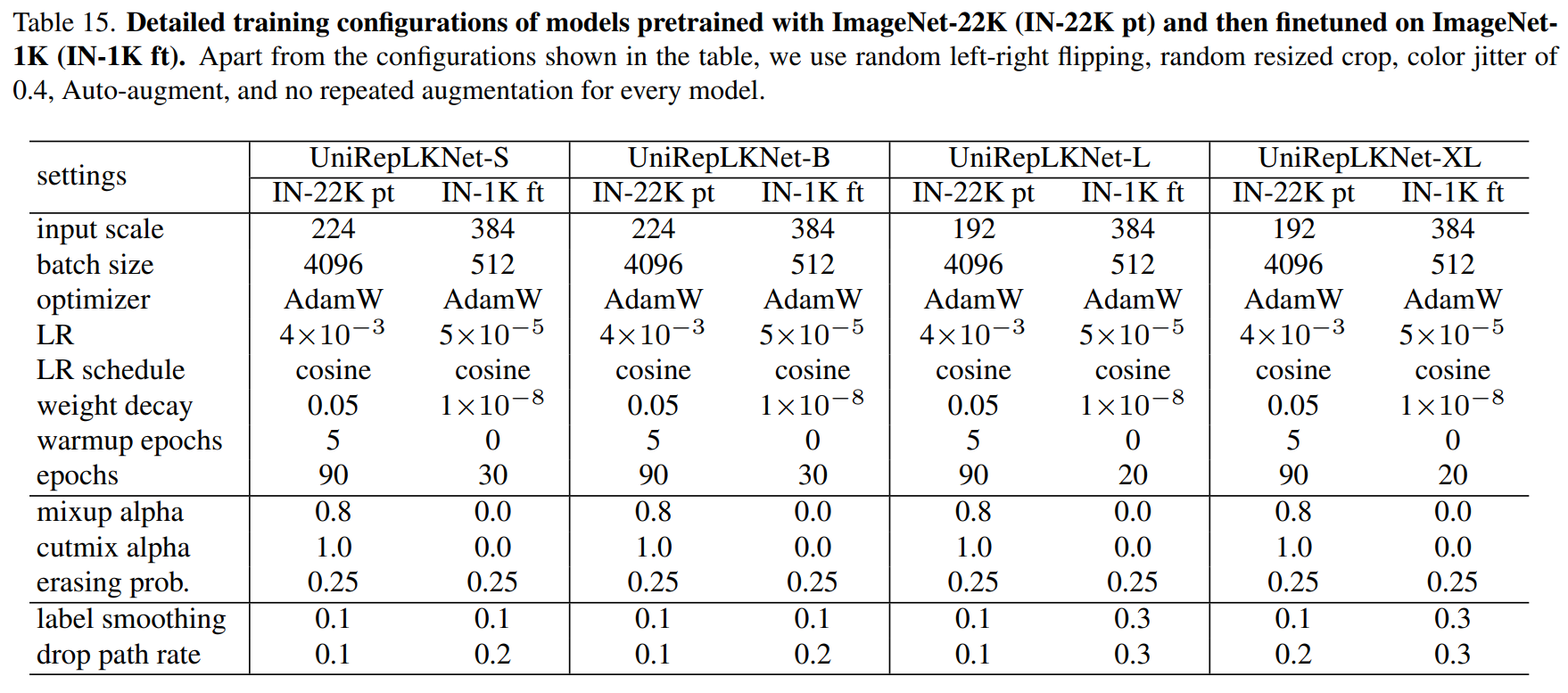
RT-DERT改进策略:UniRepLKNet,大核卷积的最新成果,轻量高效的首选(全网首发)
摘要 将UniRepLKNet应用到RT-DERT的改进中,经过测试,涨点明显,运算量也有下降! 论文:《UniRepLKNet:用于音频、视频、点云、时间序列和图像识别的通用感知大内核ConvNet》 https://arxiv.org/abs/2311.15599 大核卷积神经网络(ConvNets)最近受到了广泛的研究关注,但存在两个未解决的关键问题需要进一步研究。(1)现有大核Con

YOLOv8改进 | 2023 | LSKAttention大核注意力机制助力极限涨点
论文地址:官方论文地址 代码地址:官方代码地址 一、本文介绍 在这篇文章中,我们将讲解如何将LSKAttention大核注意力机制应用于YOLOv8,以实现显著的性能提升。首先,我们介绍LSKAttention机制的基本原理,它主要通过将深度卷积层的2D卷积核分解为水平和垂直1D卷积核,减少了计算复杂性和内存占用。接着,我们介绍将这一机制整合到YOLOv8的方法,以及它如何帮助

Android Fingerprint 通过提高CPU主频及绑定大核提高 Android 手机指纹识别性能
通过提高CPU主频及绑定大核提高 Android 手机指纹识别性能 背景 各大厂商追求手机指纹解锁以及识别快速流畅性,提升用户体验。对指纹解锁提出给快的要求,因此想办法从三个角度优化指纹识别的速度,提升手机解锁以及是指纹识别流畅性。以自己的经验做个marker。 一,提高指纹通讯速率 目前部分指纹解锁速率最高可达24MHz/s, 单提高spi 速率可能会导致通信失败,会展传输数据校验失败,

YOLOv8血细胞检测(5):可变形大核注意力(D-LKA Attention),超越自注意力| 2023.8月最新发表
💡💡💡本文独家改进:可变形大核注意力(D-LKA Attention),采用大卷积核来充分理解体积上下文的简化注意力机制,来灵活地扭曲采样网格,使模型能够适当地适应不同的数据模式 D-LKA Attention | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.903 收录专栏: 💡💡💡YOLO医学影像检测:http://t.csdnimg.cn/N4