本文主要是介绍CVPR2024 | 大核卷积新高度101x101,美团提出PeLK,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
https://arxiv.org/pdf/2403.07589.pdf
本文概述
最近,一些大核卷积网络以吸引人的性能和效率进行了反击。然而,考虑到卷积的平方复杂度,扩大内核会带来大量的参数,而大量的参数会引发严重的优化问题。由于这些问题,当前的 CNN 妥协以条带卷积的形式扩展到 (即 + ),并随着内核大小的持续增长而开始饱和。
在本文中,我们深入研究解决这些重要问题,并探讨我们是否可以继续扩展内核以获得更多性能提升。受人类视觉的启发,我们提出了一种类人外围卷积,通过参数共享有效减少了密集网格卷积 90% 以上的参数数量,并设法将内核尺寸扩大到极大。我们的外围卷积的行为与人类高度相似,将卷积的复杂性从降低到 而不会产生适得其反的性能。在此基础上,我们提出了参数高效的大核网络(PeLK)。我们的 PeLK 在各种视觉任务上(包括 ImageNet 分类、ADE20K 上的语义分割和 MS COCO 上的对象检测)优于现代视觉 Transformer 和 ConvNet 架构(如 Swin、ConvNeXt、RepLKNet 和 SLaK)。我们第一次成功地将 CNN 的内核大小扩展到前所未有的 并展示了持续的改进。
出发点
我们首先研究密集网格卷积是否比条纹卷积更好。我们采用统一的现代框架SLaK来进行这项研究。根据 RepLKNet,大内核卷积对下游任务的促进作用远大于 ImageNet 分类。因此,我们不仅在 ImageNet-1K 上进行评估,还以 ADE20K 作为基准进行评估。
遵循 SLaK,我们在 ImageNet 上训练所有模型以进行 120 轮训练。数据增强、正则化和超参数都设置相同。然后我们使用预训练模型作为 ADE20K 的骨干。具体来说,我们使用 MMSegmentation实现的 UperNet 和 80K 迭代训练计划。我们不使用任何先进技术或自定义算法,因为我们只寻求评估骨干网。

SLaK 介绍了将内核扩展为 51 × 51 的两步方法:1)将大内核分解为两个矩形、平行的内核; 2)使用动态稀疏性并扩展更多宽度。为了彻底分析卷积形式的效果,我们进行了带稀疏性和不带稀疏性的实验。默认情况下,我们重新参数化 5 × 5 卷积以缓解 SLaK 和 RepLKNet 所采取的优化问题。表1的结果表明,无论动态稀疏性如何,密集网格卷积都超过了条带卷积。

我们进一步探索不同内核大小下的卷积形式(即 K × K 与 K × N)。具体来说,我们将 SLaK 的 stripe conv 的短边固定为 5 作为默认设置(N=5),然后逐渐将 K 从 51 减少到 7。我们不使用动态稀疏性来对卷积形式进行纯粹的消融。如图2所示,密集网格卷积在多个内核尺寸下始终优于条带卷积,并且增益随着内核尺寸的增加而增加,展示了密集网格大内核卷积的本质优势。
然而,密集网格卷积的平方复杂度会带来参数激增。例如,如图 2 所示,将内核从 7 扩大到 51 只会为 stripe conv 带来 7.3 个 × 参数,而密集 conv 则为 53.1 × 参数。鉴于人类的周边视觉的周边区域只有极少量的感光细胞,我们认为密集的参数对于周边相互作用来说并不是必需的。受此启发,我们寻求通过引入周边视觉机制来降低参数复杂度,同时保留密集计算以保持密集卷积的强大性能。
本文方案

类似于人类的周边视觉,我们的周边卷积的共享网格主要由两个核心设计组成:
-
i)聚焦和模糊机制。如图1(b)所示,我们将细粒度参数保留在卷积核的中心区域,其中共享网格设置为1(即不共享)。对于外围区域,我们利用大范围参数共享来利用外围视觉的空间冗余。中心区域的细粒度至关重要,而外围区域可以承受大范围的参数共享,而不会产生适得其反的性能;
-
ii) 共享粒度呈指数级增加。人类视力以准指数模式下降[35]。受此启发,我们设计了以指数级增长的方式增长的共享网格。这种设计可以优雅地将卷积的参数复杂度从 𝑂 ( 𝐾 2 ) 降低到 𝑂 ( log 𝐾 ) ,从而可以进一步扩大密集卷积的内核大小。

尽管所提出的外围卷积有效地减少了密集卷积的参数,但大范围的参数共享可能会带来另一个问题:外围区域的局部细节模糊。尤其是当内核大小以外围卷积的形式放大到50以上甚至100以上时,当单个参数需要处理 8 × 8 甚至 16 × 16
为了解决这个问题,我们提出了基于内核的位置嵌入。形式上,给定一组输入特征 𝑋 ,我们通过与内核权重 w ∈ ℝ 𝑐 in × 𝑐 out × k × k 的卷积来处理这些特征。我们使用 trunc normal [53] 初始化来初始化嵌入 h ∈ ℝ 𝑐 in × k × k 的位置。
架构设计
基于上述设计和观察,我们现在详细阐述了参数高效的大型内核网络(PeLK)的架构。我们主要按照ConvNeXt和SLaK来构建多种尺寸的模型。具体来说,PeLK还采用了4阶段的框架。我们用带有 4 × 4 内核和 4 步幅的卷积层构建茎。对于微小尺寸,阶段的块编号为 [ 3 , 3 , 9 , 3 ] ;对于小尺寸/基本尺寸,阶段的块编号为 [ 3 , 3 , 27 , 3 ] 。 PeLK 不同阶段的内核大小默认为 [ 51 , 49 , 47 , 13 ] 。对于 PeLK-101,内核大小放大至 [ 101 , 69 , 67 , 13 ] 。
默认情况下,我们将中心 5 × 5 区域保持为细粒度。对于PeLK-101,我们将中心区域放大到 7 × 7 来调整增加的内核。继 SLaK 之后,我们还使用动态稀疏性来增强模型容量。所有超参数设置相同( 1.3 × 宽度,40% 稀疏度)。
本文实验
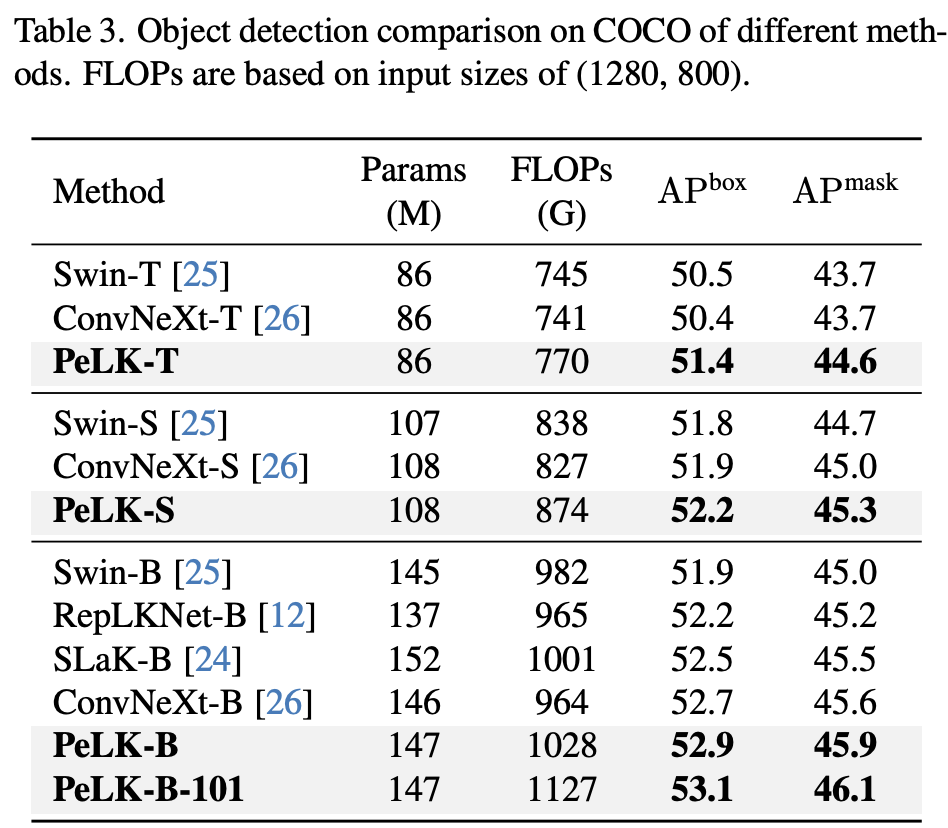

小结
本文探讨了超大核卷积神经网络的设计,我们提出了一种新的卷积形式,称为外围卷积,它可以将密集卷积的参数复杂度从 𝑂 ( 𝐾 2 ) 降低到 𝑂 ( log 𝐾 ) ,同时保持密集卷积的优点。基于所提出的外围卷积,我们设计了极大的密集内核 CNN,并在各种视觉任务中取得了显着的改进。我们强有力的结果表明,受生物学启发的机制可以成为促进现代网络设计的有前途的工具。
这篇关于CVPR2024 | 大核卷积新高度101x101,美团提出PeLK的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







