cvpr2024专题

YOLOv8改进实战 | 注意力篇 | 引入CVPR2024 PKINet 上下文锚点注意力CAAttention
YOLOv8专栏导航:点击此处跳转 前言 YOLOv8 是由 YOLOv5 的发布者 Ultralytics 发布的最新版本的 YOLO。它可用于对象检测、分割、分类任务以及大型数据集的学习,并且可以在包括 CPU 和 GPU 在内的各种硬件上执行。 YOLOv8 是一种尖端的、最先进的 (SOTA) 模型,它建立在以前成功的 YOLO 版本的基础上,并引入了新的功能和改进,以

CVPR2024|UniPAD:一种自动驾驶的统一的预训练范式
本文章仅用于学术分享 论文标题丨 UniPAD: A Universal Pre-training Paradigm for Autonomous Driving 论文地址丨 https://arxiv.org/abs/2310.08370 代码地址 | https://github.com/Nightmare-n/UniPAD 关注「AI前沿速递」公众号,获取更多前沿资讯 01总
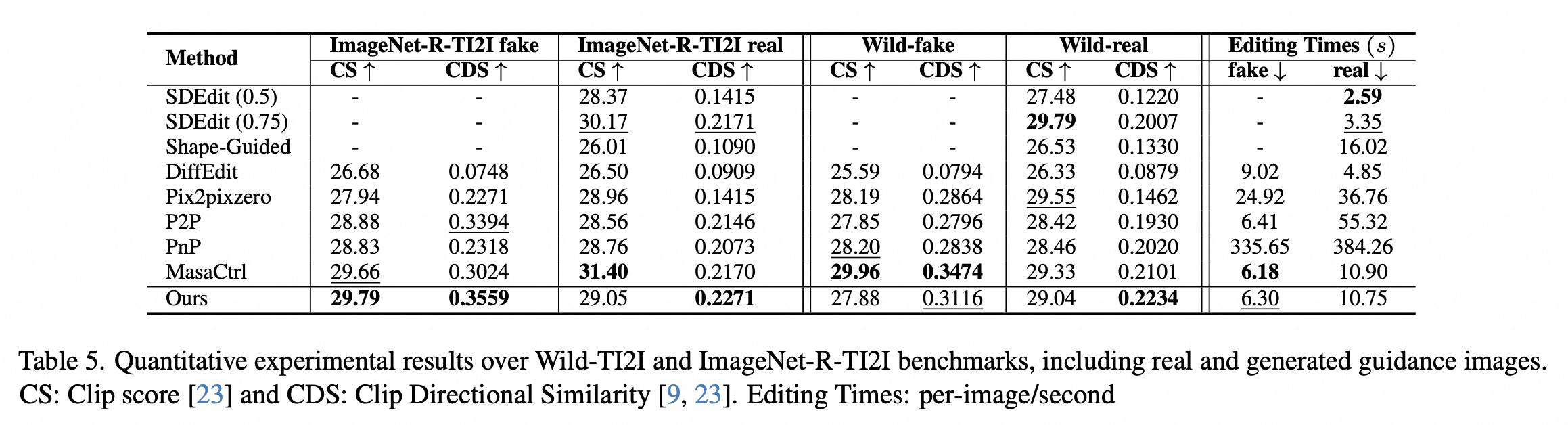
【CVPR2024】面向StableDiffusion的编辑算法FreePromptEditing,提升图像编辑效果
近日,阿里云人工智能平台PAI与华南理工大学贾奎教授团队合作在深度学习顶级会议 CVPR2024 上发表 FPE(Free-Prompt-Editing) 算法,这是一种面向StableDiffusion的图像编辑算法。在这篇论文中,StableDiffusion可用于实现图像编辑的本质被挖掘,解释证明了基于StableDiffusion编辑的算法本质,并基于此设计了新的图像编辑算法,大幅度提升了

【CVPR2024】阿里云人工智能平台PAI图像编辑算法论文入选CVPR2024
近期,阿里云人工智能平台PAI发表的图像编辑算法论文在CVPR-2024上正式亮相发表。论文成果是阿里云与华南理工大学贾奎教授领衔的团队共同研发。CVPR(计算机视觉与模式识别会议)是计算机视觉和模式识别领域的顶级国际会议,旨在展示最新的研究进展和技术成就,推动这一领域理论与应用的前沿进展,并通过精选提交的高水平学术论文和实践工作,对学术界和工业界产生深远的影响。此次入选标志着阿里云人工智能平台P

CVPR2024知识蒸馏Distillation论文49篇速通
Paper1 3D Paintbrush: Local Stylization of 3D Shapes with Cascaded Score Distillation 摘要小结: 我们介绍了3DPaintbrush技术,这是一种通过文本描述自动对网格上的局部语义区域进行纹理贴图的方法。我们的方法直接在网格上操作,生成的纹理图能够无缝集成到标准的图形管线中。我们选择同时生成一个定位图(指定编辑
OpenBayes 一周速览|Apple 开源大模型 OpenELM 上线;字节发布 COCONut 首个全景图像分割数据集,入选 CVPR2024
公共资源速递 This Weekly Snapshots ! 5 个数据集: * COCONut 大规模图像分割数据集 * THUCNews 新闻数据集 * DuConv 对话数据集 * 安徽电信知道问答数据集 * Sentiment Analysis 中文情感分析数据集 2 个模型: * OpenELM-3B-Instruct * OpenWebUI 代码库 3 个教程:
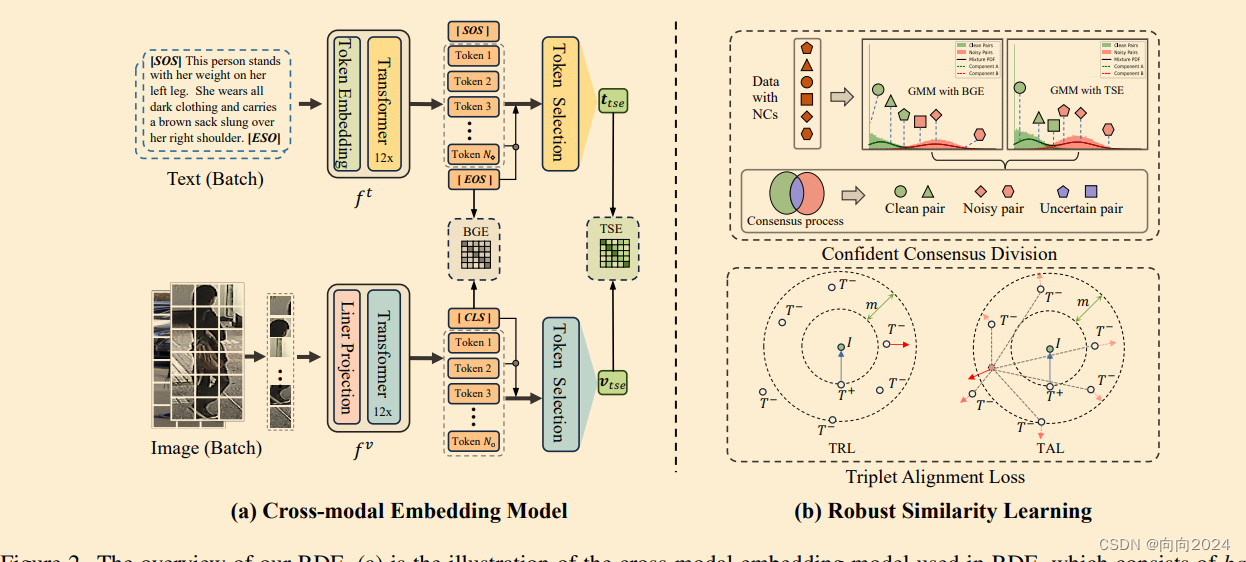
【CVPR2024】文本到图像的行人再识别中的噪声对应学习
这篇论文的标题是《Noisy-Correspondence Learning for Text-to-Image Person Re-identification》,作者是来自中国四川大学、英国诺森比亚大学、新加坡A*STAR前沿人工智能研究中心和高性能计算研究所的研究人员。论文主要研究了文本到图像的行人再识别(Text-to-Image Person Re-identification, TIR

YOLOv8改进 | Conv篇 | CVPR2024最新DynamicConv替换下采样(包含C2f创新改进,解决低FLOPs陷阱)
一、本文介绍 本文给大家带来的改进机制是CVPR2024的最新改进机制DynamicConv其是CVPR2024的最新改进机制,这个论文中介绍了一个名为ParameterNet的新型设计原则,它旨在在大规模视觉预训练模型中增加参数数量,同时尽量不增加浮点运算(FLOPs),所以本文的DynamicConv被提出来了,使得网络在保持低FLOPs的同时增加参数量,从而允许这些网络从大规模视觉预训练中
YOLOv8结合CVPR2024最新图像增强算法!让你的模型无惧风雨【含端到端推理脚本】
篇博客的算法来自于CVPR2024,代码刚刚开源没几天~ 原图去雨去雨+检测 如何有效地探索雨痕的多尺度表示对于图像去雨是很重要的。与现有的基于Transformer的方法相比,这些方法主要依赖于单一尺度的雨痕外观,我们开发了一个端到端的多尺度Transformer,利用各种尺度中潜在有用的特征来促进高质量的图像重建。为了更好地探索空间变化的雨痕的常见退化表示,我们在像素坐标上结合了基于

番外篇 | YOLOv8改进之在C2f中引入即插即用RepViTBlock模块 | CVPR2024清华RepViT
前言:Hello大家好,我是小哥谈。YOLOv8是一种基于深度学习的实时物体检测算法,其通过将物体检测任务转化为目标框回归问题,并使用卷积神经网络实现高效的特征提取和目标分类。然而,YOLOv8在处理一些复杂场景和小目标时可能存在一定的性能限制。为了克服YOLOv8的局限性,清华大学在ICCV会议上发布了名为RepViT的移动端网络架构。RepViT通过自注意力机制(self-attenti

YOLOv9改进策略:卷积魔改 | DCNv4更快收敛、更高速度、更高性能,效果秒杀DCNv3、DCNv2等 ,助力检测 | CVPR2024
💡💡💡本文改进内容: DCNv4来自CVPR2024 的论文,它不仅收敛速度明显快于DCNv3,而且正向速度提高了3倍以上。这一改进使DCNv4能够充分利用其稀疏特性,成为最快的通用核心视觉算子之一。 改进结构图如下: YOLOv9魔术师专栏 ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁

YOLOv5全网首发改进: 注意力机制改进 | 上下文锚点注意力(CAA) | CVPR2024 PKINet 遥感图像目标检测
💡💡💡本文独家改进:引入了CAA模块来捕捉长距离的上下文信息,利用全局平均池化和1D条形卷积来增强中心区域的特征,从而提升检测精度,CAA和C3进行结合实现二次创新,改进思路来自CVPR2024 PKINet,2024年前沿最新改进,抢先使用 💡💡💡小目标数据集,涨点近两个点,强烈推荐 改进结构图如下: 收录 YOLOv5原创自研 https://

《InfMAE: A Foundation Model in Infrared Modality》CVPR2024
基础模型vs大模型:大模型,也称基础模型,是指具有大规模参数和复杂计算结构的机器学习模型 以后的研究中必须把大模型和基础模型耦合进来 总结:占坑 1. A+B 多光谱的基础模型 红外的基础模型 可见光的基础模型 整体架构差不多,不一样的地方值得研究,就可以考虑A+B 2. 利用跨模态的基础模型去做我们领域的基础研究
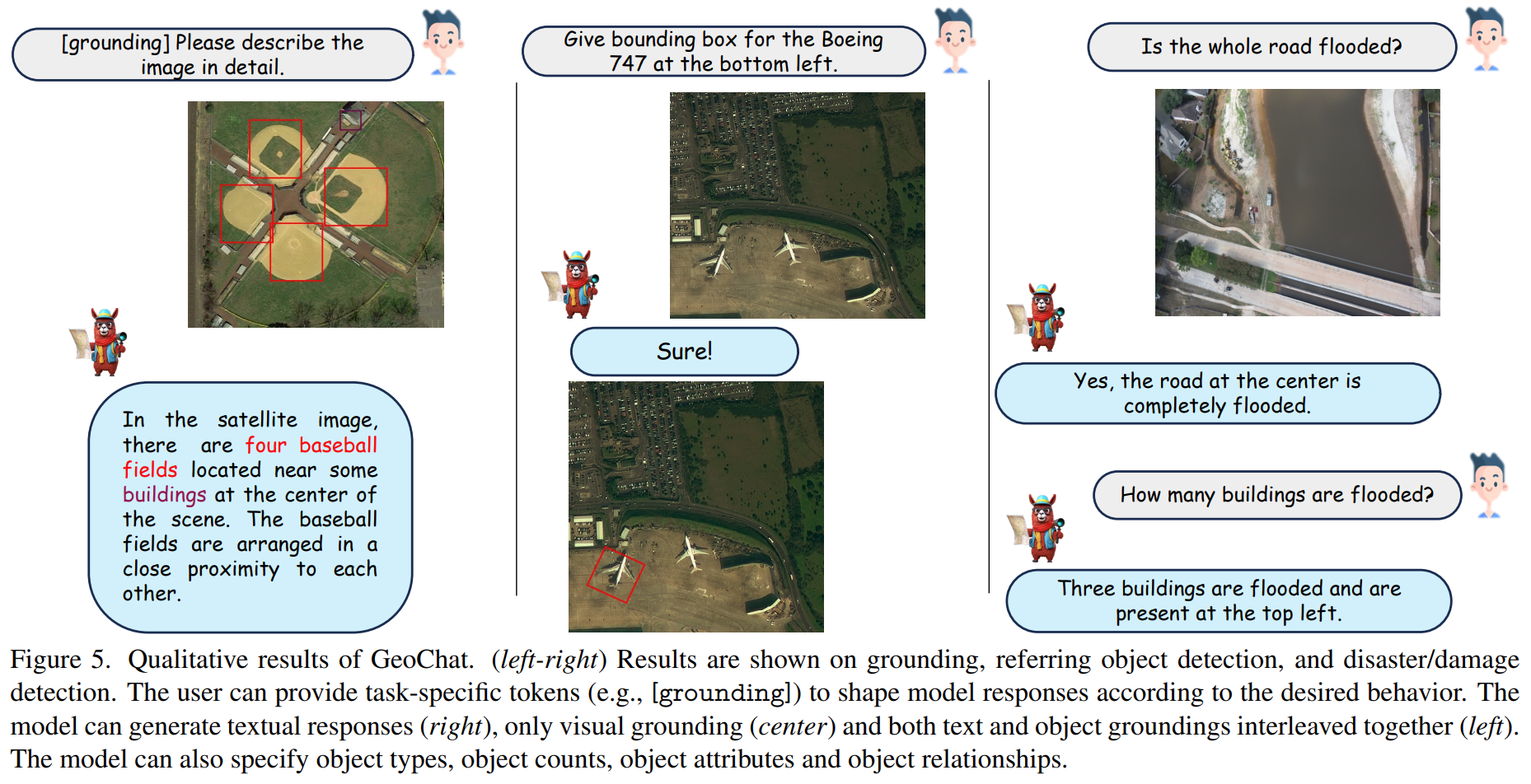
论文阅读——GeoChat(cvpr2024)
GeoChat : Grounded Large Vision-Language Model for Remote Sensing 一、引言 GeoChat,将多模态指令调整扩展到遥感领域以训练多任务会话助理。 遥感领域缺乏多模式指令调整对话数据集。受到最近指令调优工作的启发,GeoChat 使用 Vicuna-v1.5和自动化管道来生成包含近 318k 指令的各种遥感多模式指令跟踪数

CVPR2024 | 大核卷积新高度101x101,美团提出PeLK
https://arxiv.org/pdf/2403.07589.pdf 本文概述 最近,一些大核卷积网络以吸引人的性能和效率进行了反击。然而,考虑到卷积的平方复杂度,扩大内核会带来大量的参数,而大量的参数会引发严重的优化问题。由于这些问题,当前的 CNN 妥协以条带卷积的形式扩展到 (即 + ),并随着内核大小的持续增长而开始饱和。 在本文中,我们深入研究解决这些重要问题,并探讨我们
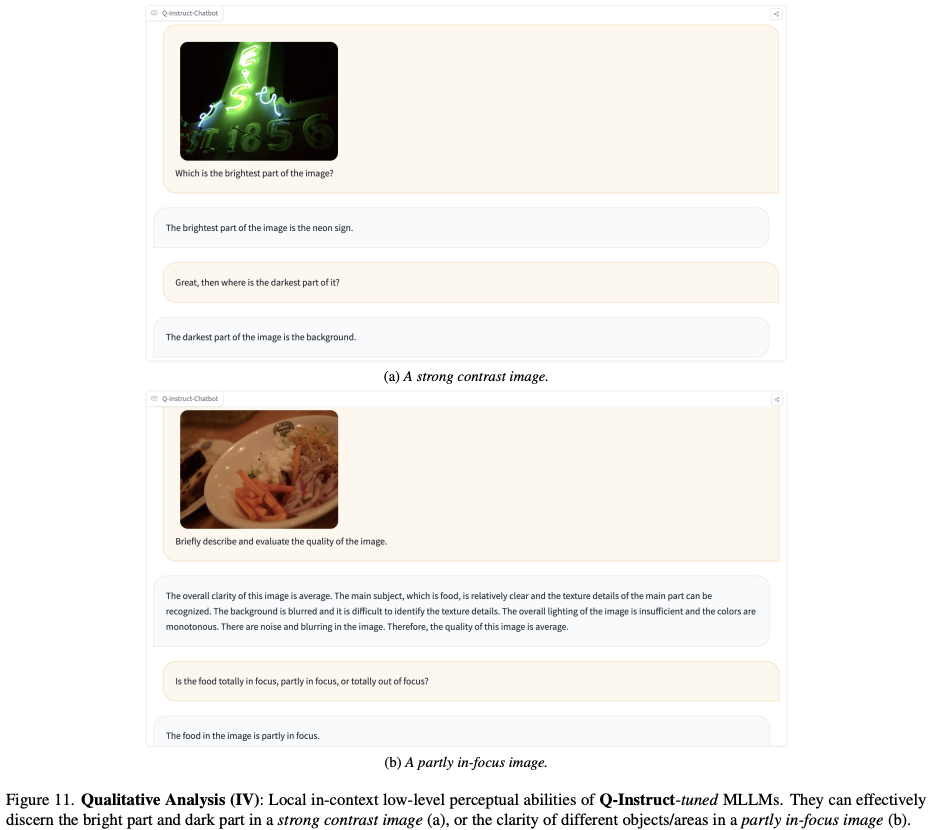
CVPR2024 | 改善多模态大模型底层视觉能力,NTU与商汤联合提出Q-Instruct,已开源
https://arxiv.org/pdf/2311.06783.pdf https://github.com/Q-Future/Q-Instruct 以 GPT-4V 为代表的多模态大语言模型(MLLM)为视觉感知和理解任务引入了范式转变,即可以在一个基础模型中实现多种能力。虽然当前的 MLLM 表现出了从低级视觉属性(例如清晰度、亮度)识别到图像质量评估的初级低级视觉能力,但仍

YOLOv8独家改进:backbone改进 | TransXNet:聚合全局和局部信息的全新CNN-Transformer视觉主干| CVPR2024
💡💡💡本文独家改进:CVPR2024 TransXNet助力检测,代替YOLOv8 Backbone 改进结构图如下: 收录 YOLOv8原创自研 https://blog.csdn.net/m0_63774211/category_12511737.html?spm=1001.2014.3001.5482 💡💡💡全网独家首发创新(原创),适合paper !!!
YOLOv8独家改进:backbone改进 | 最新大卷积核CNN架构UniRepLKNet,ImageNet 88% | CVPR2024
💡💡💡本文独家改进:大核卷积一统多种模态!RepLK正统续作UniRepLKNet,代替YOLOv8 Backbone 改进结构图如下: 收录 YOLOv8原创自研 https://blog.csdn.net/m0_63774211/category_12511737.html?spm=1001.2014.3001.5482 💡💡💡全网独家首发创新(原创),适合p
YOLOv5独家改进:backbone改进 | 最新大卷积核CNN架构UniRepLKNet,ImageNet 88% | CVPR2024
💡💡💡本文独家改进:大核卷积一统多种模态!RepLK正统续作UniRepLKNet,代替YOLOv5 Backbone 改进结构图如下: 收录 YOLOv5原创自研 https://blog.csdn.net/m0_63774211/category_12511931.html 💡💡💡全网独家首发创新(原创),适合paper !!! 💡💡💡 2024年

CVPR2024 进一步提升超分重建质量,中科大提出用于图像超分的语义感知判别器SeD,即将开源
本文首发: AIWalker,欢迎关注~ https://arxiv.org/abs/2402.19387 https://github.com/lbc12345/SeD 本文概述 生成对抗网络(GAN)已被广泛用于恢复图像超分辨率(SR)任务中的生动纹理。判别器使 SR 网络能够以对抗性训练的方式学习现实世界高质量图像的分布。然而,这种分布学习过于粗粒度,容易受到虚拟纹理的
CVPR2024|AIGC(图像生成,视频生成等)相关论文汇总(附论文链接/开源代码/解析)【持续更新】
CVPR2024|AIGC相关论文汇总(如果觉得有帮助,欢迎点赞和收藏) Awesome-CVPR2024-AIGC1.图像生成(Image Generation/Image Synthesis)ECLIPSE: A Resource-Efficient Text-to-Image Prior for Image GenerationsInstanceDiffusion: Instance-
CCF_A 计算机视觉顶会CVPR2024投稿指南以及论文模板
目录 CVPR2024官网: CVPR2024投稿链接: CVPR2024 重要时间节点: CVPR2024投稿模板: WORD: LATEX : CVPR2024_AuthorGuidelines CVPR2024投稿Topics: CVPR2024官网: https://cvpr.thecvf.com/Conferences/2024CVPR - The IEE
CCF_A 计算机视觉顶会CVPR2024投稿指南以及论文模板
目录 CVPR2024官网: CVPR2024投稿链接: CVPR2024 重要时间节点: CVPR2024投稿模板: WORD: LATEX : CVPR2024_AuthorGuidelines CVPR2024投稿Topics: CVPR2024官网: https://cvpr.thecvf.com/Conferences/2024CVPR - The IEE