本文主要是介绍VGG: Very deep convolutional networks for large-scale image recognition,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 前言
经过前面两篇文章的介绍,我们已经了解了LeNet5和AlexNet网络模型。但是总体上来说两者的网络结构几乎并没有太大的差别,仅仅,同时网络的深度以及参数的规模也没有太大的变化。在接下来的这篇文章中,我们将会看到卷积网络中的第三个经典模型VGG。在这篇文章中,作者对卷积网络卷积深度的设计进行了一个探索,并且通过尝试逐步加深网络的深度来提高模型的整体性能。这使得VGG在当年的ILSVRC任务中取得了TOP1的成绩。
2 VGG网络
VGG网络产生于2014年的Visual Geometry Group 实验室,而这三个单词的首字母也代表了VGG的含义。VGG网络总体上一共有五种网络架构,但是从本质上来说这五种网络架构都是一样的,仅仅只是在卷积的深度上有所差别。下面,就让我们一步步的来探索VGG的网络结构。公众号后台回复“论文”即可获取论文下载链接!
2.1 网络结构
如图1所示,一共有六列,其中第二列是在第一例的基础上加入了LRN标准化操作[2]。同时,需要注意的是,例如图中A结构列出的"11 weight layers"的含义是其包含有11个参数层,即8个卷积层和3个全连接层,而没有包含池化层和非线性变换层。通常,这也是一种默认的叫法,说网络有多少层的时候只计算有多少层含有可训练的参数。
在整个网络的训练过中,VGG固定输入网络图片的大小为 224 × 224 224\times224 224×224的RGB图像,并且在输入网络之前仅仅只是做了去均值化的处理,即在训练集中每个像素值都会减去整体像素的一个平均值。接着,预处理完成的图片将会被喂入到一些列仅仅只由窗口大小为 3 × 3 3\times3 3×3的卷积核堆叠而成的卷积网络中。但是从图1中的模型C可以看出,其还使用了窗口大小为 1 1 1的卷积。这是因为作者认为, 1 × 1 1\times1 1×1的卷积既可以增加模型的非线性拟合能力,同时还不会改变卷积层的可视野。

在五种网络架构中,所有卷积时的步长都被设置成了固定的 1 1 1;并且为了使得卷积后特征图的大小同输入时保持一直,网络在每次卷积之前均做了对应的填充处理。在池化方面,五种网络模型均使用了五次最大池化操作,其窗口大小均为 2 × 2 2\times2 2×2,移动步长均为 2 2 2。
在完成一系列的卷积处理后,VGG会将卷积得到的特征图再喂入到全连接网络中:其中前两个全连接层均包含有 4096 4096 4096个神经元;而最后一个全连接层神经元的个数则是对应的分类数 1000 1000 1000,紧接着再是一个Softmax的分类层。对于所有的五种网络结构来说,这部分都采用了相同的配置。最后,在VGG中,所有的隐藏层(所有卷积层和前两个全连接层)都进行了ReLU非线性变换。
从图1所示的网络结构可以看出,在整个过程中作者都仅仅只使用了 3 × 3 3\times3 3×3大小的卷积核,而摒弃了诸如 5 × 5 5\times5 5×5或者是 7 × 7 7\times7 7×7这类更大卷积核。因为作者研究发现,连续两次(中间没有pooling)使用窗口为 3 3 3的卷积核卷积后的可视野(receptive field)等同于一次窗口大小为 5 5 5的卷积过程;而连续三次(中间没有pooling)使用 3 × 3 3\times3 3×3卷积,其效果等价于一次窗口大小为 7 7 7的卷积过程。尽管两种方式都能获得同样的可视野,但作者依旧采用了前者。
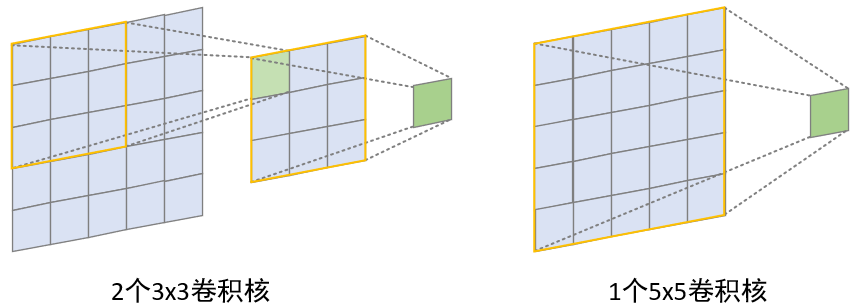
如图2所示,左右两边均是大小为 5 × 5 5\times5 5×5的输入,左边通过连续两次 3 × 3 3\times3 3×3大小的卷积核进行卷积后能够实现 5 × 5 5\times5 5×5的可视野;而右边仅用一次 5 × 5 5\times5 5×5大小的卷积核进行卷积后同样也能够实现 5 × 5 5\times5 5×5的可视野。那这样做的好处是什么呢?以窗口大小为 7 7 7和连续三个窗口大小为
这篇关于VGG: Very deep convolutional networks for large-scale image recognition的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)


![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)
![Android AnimationDrawable资源 set[translate,alpha,scale,rotate]](https://img-blog.csdn.net/20170610181346934?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvc29uZ3l1bG9uZzg4ODg=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center)