本文主要是介绍中科院提出:视觉-语言预训练(VLP)综述,了解多模态最新进展!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:Feilong Chen等
转载自:机器之心 | 编辑:陈萍
一文了解视觉 - 语言预训练最新进展和新领域。
让机器做出与人类相似的反应一直是 AI 研究不懈追求的目标。为了让机器具有感知和思考的能力,研究人员进行了一系列相关研究,如人脸识别、阅读理解和人机对话,通过这些任务训练和评估机器在特定方面的智能。一般来讲,领域专家通过手工构建标准数据集,然后在这些数据集上训练和评估相关模型。然而,由于相关技术的限制,训练模型往往需要大量的标注数据,以获得更好、更强大的模型。
基于 Transformer 架构的预训练模型缓解了这个问题。它们首先通过自监督学习进行预训练,从大规模未标记数据中训练模型,从而学习通用表示。它们在下游任务上仅使用少量手动标记的数据进行微调就能取得令人惊讶的效果。自 BERT 被应用于 NLP 任务以来,各种预训练模型在单模态领域快速发展,例如 Vision Transformer (ViT) 和 Wave2Vec。大量工作表明它们有利于下游单模态任务,并避免从头开始训练新模型。
与单模态领域类似,多模态领域也存在高质量标注数据较少的问题。我们不禁会问,上述预训练方法能否应用于多模态任务?研究人员已经对这个问题进行了探索并取得了重大进展。
在本文中,来自中国科学院自动化研究所、中国科学院大学的研究者调查了视觉 - 语言预训练(vision-language pre-training,VLP)最新进展和新领域,包括图像 - 文本预训练和视频 - 文本预训练。VLP 通过对大规模数据的预训练来学习不同模态之间语义对应关系。例如,在图像 - 文本预训练中,研究者期望模型将文本中的狗与图像中的狗外观相关联。在视频 - 文本预训练中,研究者期望模型将文本中的对象 / 动作映射到视频中的对象 / 动作。

论文地址:https://arxiv.org/abs/2202.09061
为了实现这一目标,研究者需要巧妙地设计 VLP 对象和模型架构,以允许模型挖掘不同模态之间的关联。
为了让读者更好地全面掌握 VLP,该研究首先从特征提取、模型架构、预训练目标、预训练数据集和下游任务五个方面回顾其最近进展。然后,文章详细总结了具体的 VLP 模型。最后,文章讨论了 VLP 的新领域。据了解,这是对 VLP 领域的首次调查。研究者希望这项调查能够为 VLP 领域的未来研究提供启示。
VLP 综述
VLP 五个方面回顾及其最近进展
在特征处理方面:论文主要介绍了 VLP 模型如何进行预处理和表示图像、视频和文本以获得对应特征。
为了充分利用单模态预训练模型,VLP 随机初始化标准 transformer 编码器来生成视觉或文本表示。从视觉来讲,VLP 利用预训练视觉 transformer(例如 ViT 和 DeiT)对 ViT-PF 进行编码。从文本来讲,VLP 使用预训练文本 transformer(例如 BERT)对文本特征进行编码。为简单起见,该研究将这些 transformer 命名为 Xformer。
在模型架构方面:论文从两个不同的角度介绍 VLP 模型架构:(1)从多模态融合的角度来观察单流与双流架构(2)从整体架构设计来比较编码器以及编码器 - 解码器对比。
单流架构是指将文本和视觉特征组合在一起,然后馈入单个 transformer 块,如下图 1 (a) 所示。单流架构通过合并注意力来融合多模态输入。单流架构的参数效率更高,因为两种模式都使用相同的参数集。
双流架构是指文本和视觉特征没有组合在一起,而是独立馈入到两个不同的 transformer 块,如图 1 (b) 所示。这两个 transformer 块不共享参数。为了获得更高的性能,交叉注意力(如 图 1 (b) 中的虚线所示)用于实现跨模态交互。为了实现更高的效率,视觉 transformer 块和文本 transformer 块之间也可以不采用交叉注意力。
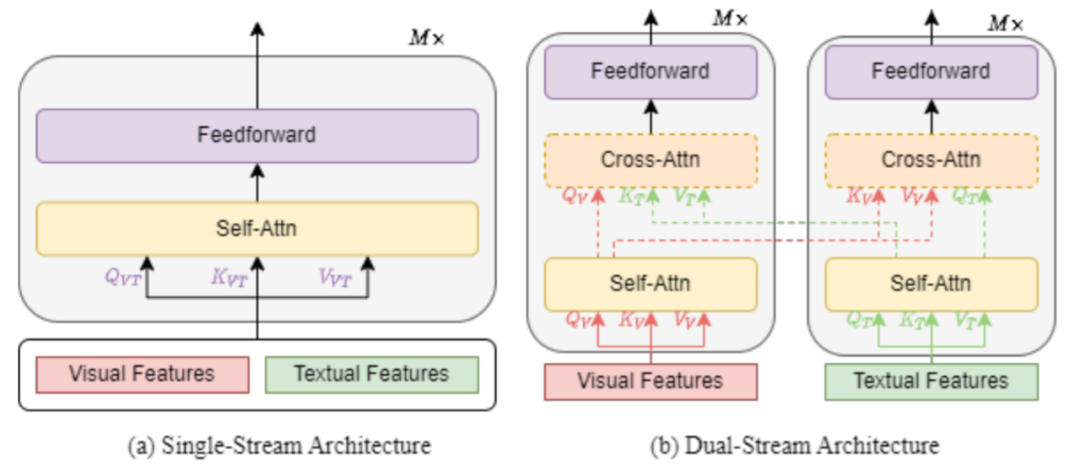
许多 VLP 模型只采用编码器架构,不同模态表示直接馈入输出层。相比之下,其他 VLP 模型提倡使用 transformer 编码器 - 解码器架构,不同模态表示首先馈入解码器,然后馈入输出层。
在预训练目标方面:论文通过使用不同的预训练目标来预训练 VLP 模型,并将预训练目标总结为四类:完成、匹配、时间和特定类型。
完成(completion)指的是利用未掩码部分来重建掩码元素。以掩码语言建模 (MLM) 为例,其最早由 taylor 提出,由于 BERT 将其作为预训练任务而广为人知。VLP 模型中的 MLM 类似于预训练语言模型 (PLM) 中的 MLM,它不仅可以通过其余文本 token 来预测掩码文本 token,还可以通过视觉 token 来预测掩码文本 token。根据经验,遵循 BERT 的 VLP 模型以 15% 的掩码率随机掩码每个文本输入 token,并在 80% 的时间使用特殊 token [MASK]、10% 的时间使用随机文本 token,剩余 10% 的时间使用原始 token 来替换被掩码掉的文本。不过在普林斯顿大学陈丹琦等人的论文《Should You Mask 15% in Masked Language Modeling?》中,作者发现:在有效的预训练方案下,他们可以掩蔽 40-50% 的输入文本,并获得比默认的 15% 更好的下游性能。
在掩码视觉建模 (MVM) 中,与 MLM 一样,MVM 对视觉(图像或视频)区域或 patch 进行采样,并且通常以 15% 的概率掩码其视觉特征。VLP 模型需要在给定剩余的视觉特征和所有文本特征的情况下重建掩码的视觉特征。
视觉 - 语言匹配 (VLM) 是最常用的预训练目标,用于对齐视觉和语言。在单流 VLP 模型中,研究者使用特殊 token [CLS] 表示作为两种模态的融合表示。在双流 VLP 模型中,研究者将特殊视觉 token [CLSV] 视觉表示和特殊文本 token [CLST] 文本表示连接起来,作为两种模态的融合表示。VLP 模型将两种模态的融合表示提供给 FC 层和 sigmoid 函数以预测 0 到 1 之间的分数,其中 0 表示视觉和语言不匹配,1 表示视觉和语言匹配。在训练期间,VLP 模型在每一步从数据集中采样正对或负对。
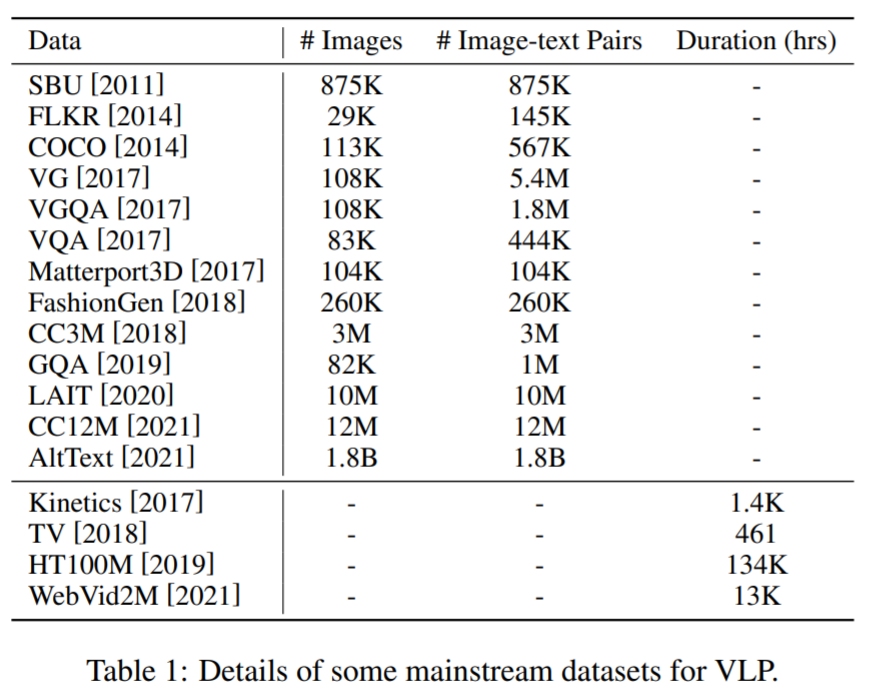
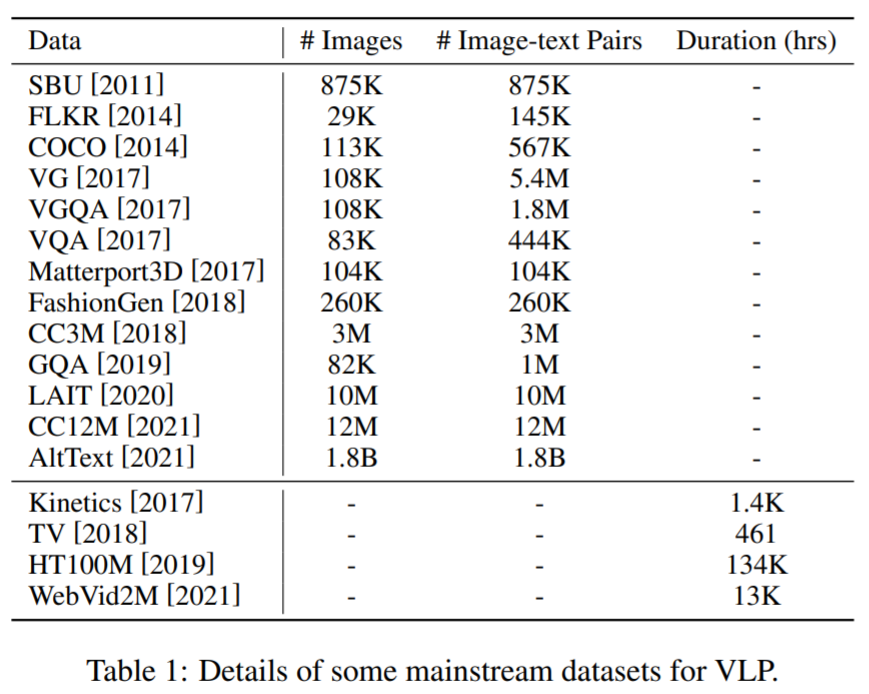
在预训练数据集方面:大多数用于 VLP 的数据集是通过组合跨多模态任务的公共数据集构建而成。这里,一些主流语料库及其详细信息如下表 1 所示。
在下游任务方面:各种各样的任务需要视觉和语言知识融合。本小节论文介绍了此类任务的基本细节和目标,并将其分为五类:分类、回归、检索、生成和其他任务,其中分类、回归和检索任务也称为理解任务。
在分类任务中,其包括视觉问答 (VQA)、视觉推理和合成问答 (GQA)、视觉 - 语言推理 (VLI)、自然语言视觉推理 (NLVR)、视觉常识推理 (VCR) 等。在 VQA 中,提供图像或视频视觉输入,它通常被认为是一个分类任务,模型从一个选择池中预测出最合适的答案;在 GQA 中,我们可以将 GQA 视为 VQA 的升级版,旨在推进自然场景视觉推理的研究;在 VLI 中,给定具有对齐字幕的视频剪辑作为前提,并与基于视频内容的自然语言假设配对,模型需要推断该假设是否与给定视频剪辑相矛盾。
在回归任务中,多模态情感分析 (MSA) 旨在利用多模态信号(如视觉、语言等)检测视频中的情绪。它是作为一个连续的强度变量来预测话语的情感走向。
在检索任务中,视觉 - 语言检索 (VLR) 通过适当的匹配策略来理解视觉(图像或视频)和语言,其包括两个子任务,视觉到文本检索和文本到视觉检索,其中视觉到文本检索是根据视觉从更大的描述池中获取最相关的文本描述,反之亦然。
在生成任务中,视觉字幕 (VC) 旨在为给定的视觉(图像或视频)输入生成语义和语法上合适的文本描述。此外,论文还介绍了其他下游任务,例如多模态机器翻译 (MMT)、视觉语言导航 (VLN) 和光学字符识别 (OCR) 等。
SOTA VLP 模型
图像 - 文本 VLP 模型。VisualBERT 被称为第一个图像 - 文本预训练模型,使用 Faster R-CNN 提取视觉特征,并将视觉特征和文本嵌入连接起来,然后将连接后的特征馈送到单个由 BERT 初始化的 transformer 中。许多 VLP 模型在调整预训练目标和预训练数据集时遵循与 VisualBERT 相似的特征提取和架构。最近,VLMO 利用图像 patch 嵌入和文本词嵌入,将组合嵌入与模态专家一起输入到单个 transformer 中,并取得了令人印象深刻的性能。METER 探索了如何使用单模态预训练模型,并提出一种双流架构模型来处理多模态融合,从而在许多下游任务上实现了 SOTA 性能。
视频 - 文本 VLP 模型。VideoBERT 被称为第一个视频 - 文本预训练模型,其扩展 BERT 模型以同时处理视频和文本。VideoBERT 使用预训练的 ConvNet 和 S3D 来提取视频特征并将它们与文本词嵌入连接起来,并馈送到以 BERT 进行初始化的 transformer。在训练 VideoBERT 时,ConvNet 和 S3D 被冻结,这表明该方法不是端到端的。最近,受 ViT 的启发,Frozen 和 Region-Learner 首先将视频剪辑处理成帧,并根据 ViT 处理每一帧图像的方法获得 patch 嵌入。Frozen 和 Region-Learner 以端到端的方式优化自身并实现 SOTA 性能。
下表 2 总结了更多现有的主流 VLP 模型:
未来,在现有工作的基础上,研究者希望 VLP 可以从以下几个方面进一步发展:
结合声学信息,以往的多模态预训练研究大多强调语言和视觉的联合建模,而忽略了隐藏在音频中的信息;
知识学习和认知,尽管现有的 VLP 模型已经取得了显着的性能,但它们本质上是拟合大规模多模态数据集,让 VLP 模型更有知识对于未来的 VLP 很重要;
提示优化,通过设计离散或连续提示并将 MLM 用于特定的下游任务,这些模型可以减少微调大量参数的计算成本,弥合预训练和微调之间的差距。
上面综述PDF下载后台回复:VLP综述,即可下载上面论文ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!

▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看![]()
这篇关于中科院提出:视觉-语言预训练(VLP)综述,了解多模态最新进展!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







