本文主要是介绍unity+webgl+websocket实时口型+二次元语音老婆,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章开始首先感谢 B站UP: 阴沉的怪咖 提供的最初资源包
一 项目实现

2.gif
体验地址
- 体验地址 www.aixmao.com
- 不能放视频,看效果去B站链接:B站链接_bilibili
UP主提供初始代码地址:
Github地址:https://github.com/zhangliwei7758/unity-AI-Chat-Toolkit
Gitee地址:https://gitee.com/DammonSpace/unity-ai-chat-toolkit
2、LipSync插件地址:
https://developer.oculus.com/downloads/package/oculus-lipsync-unity/
1.web端实时语音识别,无需调用任何api与接口
2.web端j基于视素的实时口型
3.二次元语音模型
4.虚拟角色模拟 (基于chatGLM3)
5.web端输入文字实现交互对话(chatGLM3,porobot)
6.web端后台文字驱动模型实时讲话,控制好友模型讲话等
7.定时任务驱动模型
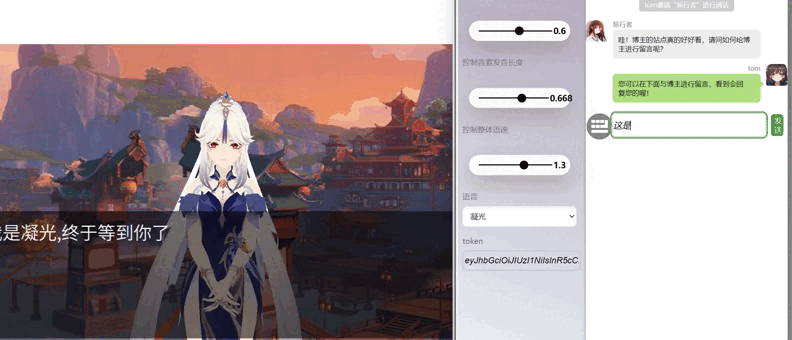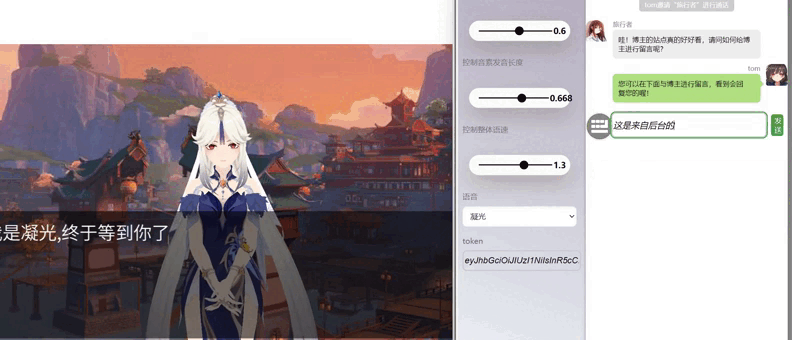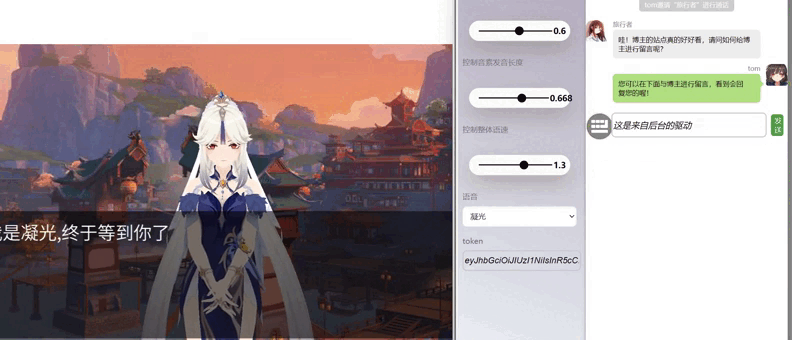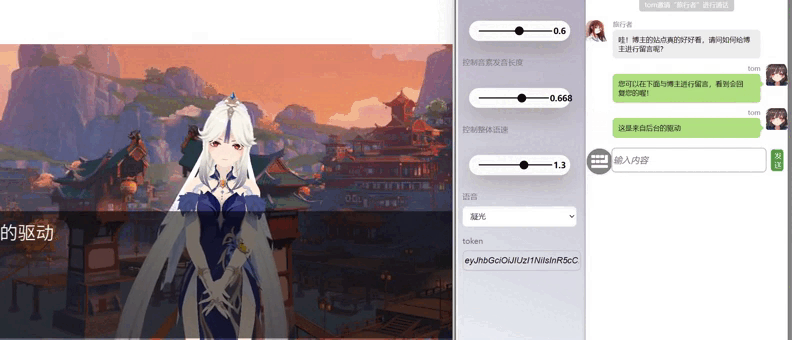
js1.gif
二 项目预览
1.不同之处
1. 基于api请求,整体下来响应速度略慢,影响体验
比如一次请求:
- 1.用户输入语音提问,点击提交 (请求一次后台)
- 2.后台拿到文字 http/https调用STT语音识别平台 (请求一次STT平台)
- 3.平台返回文字结果,后台拿到生成的用户提问文字
- 4.用户文字再去请求大语言模型(GLM,LLM,chatgpt等),等待大语言模型返回结果 (请求一次大语言模型平台)
- 5.后台拿到返回结果,再次调用TTS平台语音合成的api,生成语音 (请求一次TTS平台)
- 6.拿到语音结果,通过模型播放
2. 本项目websockt+本地化部署实现
- 1.用户与后台建立websocket实时长连接 (请求一次)
- 2.用户语音浏览器实时识别,直接转为文字,通过ws直接交给后台
- 3.后台拿到用户文字提问,调用本地chatGLM3生成回答内容
- 4.生成的回答内容,通过本地语音模型,生成二次元语音,再次通过ws直接返回给前台
2.优点
1.主打一个实时,快 (江南有名沉的快...) 整个流程或许只需要一次请求
2.本地二次元语音库
3.基于浏览器语音识别
(本来打算上传3断语音demo的,不是会员无法上传....)
- 我是凝光,今天有点想你哦
- 我是钟离,今天我有点想凝光
- 我是胡桃,今天我有点想博主
3.缺点
1.由于白天需要上班,下班需要带娃,晚上只有23点-02点有空梳理项目,导致整个项目耦合太过严重(unity+python后台+语音合成+chatGLM3)等没有好好梳理
2.实际部署服务器后,由于囊肿羞涩,实在整不起GPU服务器,顾将chatGLM3换成了porobot 一个暂时测试方案
3.unity打包webgl后包体稍大,导致第一次加载体验页面较慢(有时间优化webgl打包问题)
4.亮点
1.整个项目不需要调用外部任何接口,可以本地化部署
2.web基于视素的实时口型,类似虚拟数字人(比驱动图片口型强太多了)
5.后期规划
1.基于开源项目搭建 虚拟角色定制系统
2.根据用户设立角色背景创建符合背景的角色信息
3.开放大世界RPG类场景,多人AI对话
4.等哥们有钱了,给大家上GPU服务器体验
6.体验说明
1.由于服务器性能限制(很基本的服务器),会导致部分体验问题
2.基于服务器性能,注册用户是验证码稍微看不清....(过滤一波没耐心的,后续也会打开验证码大小写)
3.登录临时写,有问题评论区留言
三 遇到的问题
太NNNNNM多了.................................................
这里吐槽下某SBDN,CTM的,什么玩意垃圾文档,就敢让订阅,关注才可见,一个狗P东西都挂积分下载,都TM穷疯啦,想找个资料可太JJJJB难了,要么老旧不对版本,要么废话连篇讲不到点
- ......
四 项目介绍
1.关于版本
- unity 2022.3.13
- python 3.10.x
wc 要带娃了,后面抽空更新,着急的可以先去B站看看简介,另外其他UP也有很多类似的项目值得学习
这篇关于unity+webgl+websocket实时口型+二次元语音老婆的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





![C#实战|大乐透选号器[6]:实现实时显示已选择的红蓝球数量](https://i-blog.csdnimg.cn/direct/cda2638386c64e8d80479ab11fcb14a9.png)
