本文主要是介绍CMU和ETH联合研发了一个名为 「敏捷但安全」的新框架,为四足机器人在复杂环境中实现高速运动提供了解决方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在高速机器人运动领域,实现同时兼顾速度和安全一直是一大挑战。但现在,卡内基梅隆大学(CMU)和苏黎世联邦理工学院(ETH)的研究团队带来了突破性进展。他们开发的新型四足机器人算法,不仅能在复杂环境中高速行进,还能巧妙避开障碍,真正做到了「敏捷而安全」。

论文地址: https://arxiv.org/pdf/2401.17583.pdf
在 ABS 的加持下,机器狗在各种场景下都展现出了惊艳的高速避障能力:
障碍重重的狭窄走廊:

凌乱的室内场景:

无论是草地还是户外,静态或动态障碍,机器狗都从容应对:

遇见婴儿车,机器狗灵巧躲闪开:

警告牌、箱子、椅子也都不在话下:

对于突然出现的垫子和人脚,也能轻松绕过:

机器狗甚至还可以玩老鹰捉小鸡:

ABS 突破性技术:
RL+ Learning model-free Reach-Avoid value
ABS 采用了一种双策略(Dual Policy)设置,包括一个「敏捷策略」(Agile Policy)和一个「恢复策略」(Recovery Policy)。敏捷策略让机器人在障碍环境中快速移动,而一旦 Reach-Avoid Value Estimation 检测到潜在危险(比如突然出现的婴儿车),恢复策略就会介入,确保机器人安全。
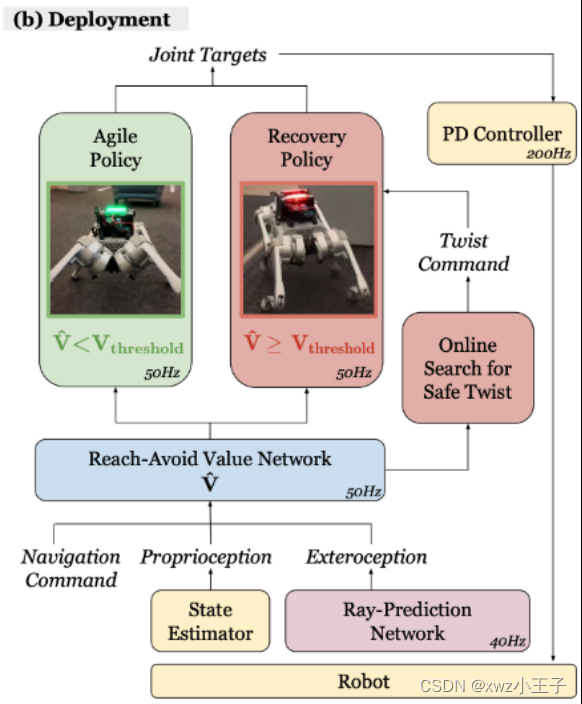
创新点 1:怎么训练一个敏捷策略 Agile Policy?
敏捷策略的创新之处在于,与以往简单地追踪速度指令不同,它采用目标达成(position trakcing)的形式来最大化机器人的敏捷性。这一策略训练机器人发展出感知运动技能,以在没有碰撞的情况下达到指定目标。通过追求基座高速度的奖励条件,机器人自然学会在避免碰撞的同时实现最大敏捷性。这种方法克服了传统速度追踪(velocity tracking)策略在复杂环境中可能的保守限制,有效提高了机器人在障碍环境中的速度和安全性。Agile Policy 在实机测试中极速达到了 3.1m/s

创新点 2:学习 Policy-conditioned reach-avoid value
「达防」(Reach-Avoid, RA)值学习的创新之处在于,它采用了无模型的方式学习,与传统的基于模型的可达性分析方法不同,更适合无模型的强化学习策略。此方法不是学习全局 RA 值,而是使其依赖于特定策略,这样可以更好地预测敏捷策略的失败。通过简化的观测集,RA 值网络可以有效地概括并预测安全风险。RA 值被用于指导恢复策略,帮助机器人优化运动以避免碰撞,从而实现在保证安全的同时提高敏捷性的目标。
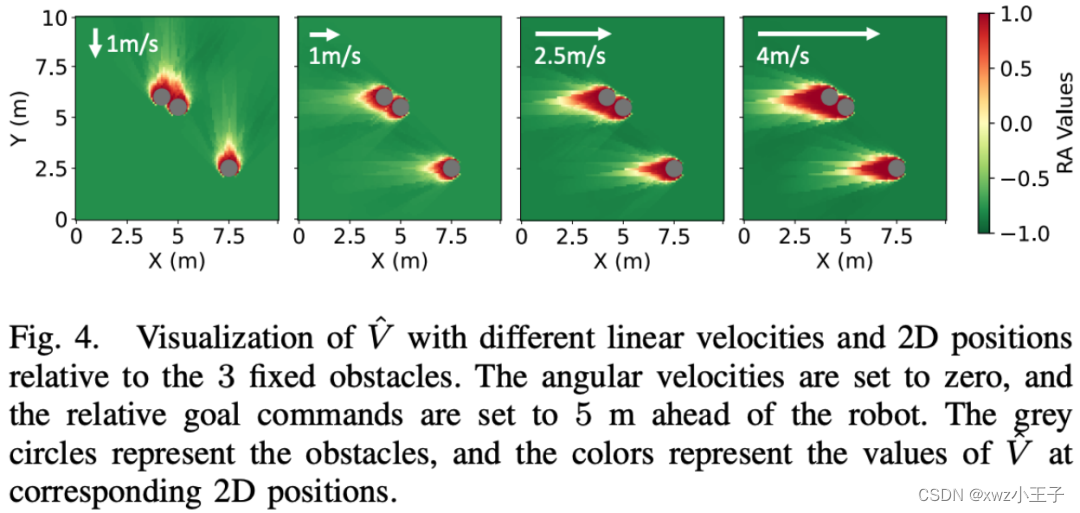
下图展示了针对特定障碍物集合学习到的 RA(达防)值。随着机器人速度的变化,RA 值的分布景观也相应变化。RA 值的符号合理地指示了敏捷策略的安全性。换句话说,这张图通过不同的 RA 值展示了机器人在不同速度下,面对特定障碍物时的安全风险程度。RA 值的高低变化反映了机器人在不同状态下执行敏捷策略时可能遇到的安全风险。
创新点 3:用 Reach-Avoid Value 和恢复策略来拯救机器人
恢复策略的创新之处在于,它能使四足机器人快速追踪线速度和角速度指令,作为一种备用保护策略。与敏捷策略不同,恢复策略的观测空间专注于追踪线速度和角速度命令,不需要外部感知信息。恢复策略的任务奖励专注于线性速度追踪、角速度追踪、保持存活和保持姿势,以便平滑切换回敏捷策略。这种策略的训练同样在仿真环境中进行,但有特定的域随机化和课程设置,以更好地适应可能触发恢复策略的状态。这种方法为四足机器人提供了在高速运动中快速应对潜在失败的能力。
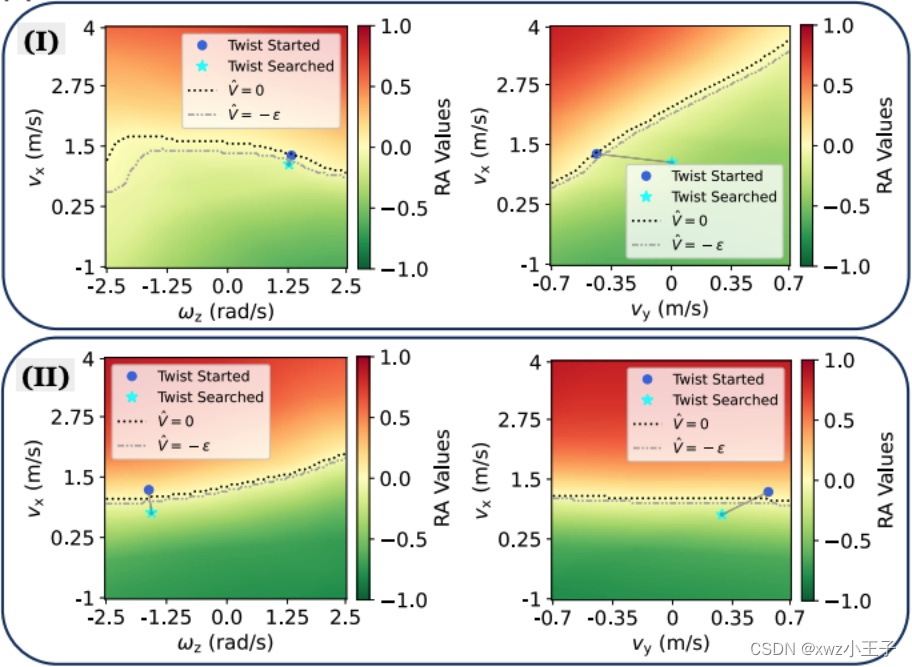
下图展示了当恢复策略在两个特定情况(I 和 II)下被触发时,RA(达防)值景观的可视化展示。这些可视化展示是在 vx(沿 x 轴的速度)与 ωz(绕 z 轴的角速度)平面以及 vx 与 vy(沿 y 轴的速度)平面上进行的。图中显示了搜索前的初始旋转状态(即机器人基座当前的旋转状态)和通过搜索得到的命令。简单来说,这些图表展示了在特定条件下,通过恢复策略搜索得到的最佳运动指令,以及这些指令如何影响 RA 值,从而反映机器人在不同运动状态下的安全性。
鲁棒性测试
作者在「12kg 负载 / 篮球撞击 / 脚踢 / 雪地」的四个场景下测试了 ABS 框架的鲁棒性,机器狗都从容应对:

这篇关于CMU和ETH联合研发了一个名为 「敏捷但安全」的新框架,为四足机器人在复杂环境中实现高速运动提供了解决方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





