本文主要是介绍self_drive car_学习笔记--第5课:动态环境感知与3D detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:这节课,主要是介绍激光雷达点云处理算法。处理基本思想就是,将3d点云信息转为2d信息,然后根据上一节课的图片处理算法常规操作即可。是不是挺简单的,哈哈哈。但,比较遗憾,本地环境问题还没有解决,还没有复现。这里记录的是,算法相关的论文以及GitHub开源的项目里面部分代码解析。好了,这一篇也仅供各位参考,欢迎大佬批评指正。
1 雷达激光点云基础及相关知识
1.1 激光雷达点云的认识
1)激光产生的
–机械式lidar:TOF(利用飞行时间计算距离)、N个独立激光单元、旋转产生360度视场
–MEMS式lidar:不旋转(但是内部有个组件在旋转)
2)数据特点:
–简单:x y z i(i表示强度)
–稀疏:7%(相对图片来说)
–无序:N!(角度不同、震动、扫描顺序不同)
–精确:±2cm
3)图像VS点云
–点云:简单精准,适合几何感知
–图像:丰富多变,适合语义感知
1.2常用数据集
1)3D点云数据来源:
–CAD模型:一般分类问题的数据集是CAD
–Lidar传感器
–RGBD相机
2)常用数据集
–Classification(Feature Representation)(分类数据集)
–ModelNet40/10
–ShapeNet Part
–无人驾驶场景数据集(detection检测;segmentation分割;tracking跟踪;….)
–http://www.cvlibs.net/datasets/kitti/【经典无人驾驶学习数据集】
–https://www.cityscapes-dataset.com/
–https://bdd-data.berkeley.edu/
–http://apolloscape.auto/【百度阿波罗项目】

3)无人驾驶入门级数据集:kitti
1.3 点云基础
1)点云处理:
–点云数据集
–相片vs点云坐标系【图1,2中涉及点云坐标系到图片坐标系的转换】
–创建点云鸟瞰图(涉及点云坐标系与图片坐标系的转换)【图1右侧就是鸟瞰图成像】
–创建360度全景视野
–使用Mayavi实现3D可视化交互
–使用Matplotlib实现3D可视化交互


注意,激光点云转换时候,选择鸟瞰图(上)还是前视图(下)或者其他视图,应该根据检测对象来定的,一般情况下,我们选择鸟瞰图;不过,但检测的是人时候,如果选择还是鸟瞰图,人会变成一个点,会导致信息量不足,此时应该选择前视图。
2)参考:
点云俯视图(鸟瞰图)创建参考:
https://blog.csdn.net/weixin_39999955/article/details/83819313
图片中点云:
https://github.com/charlesq34/frustum-pointnets
3)雷达点云转为图片关键点:
把激光雷达点云转换到某个相机的参考坐标系中,才能将激光点云数据转为图片显示
4)3d激光点云(kitti数据集)转换为鸟瞰图项目链接:https://github.com/charlesq34/frustum-pointnets/blob/master/kitti/kitti_util.py

5)源码思想解析:
激光点云数据转为彩色鸟瞰图代码大概解析,结合这个图来说,【坐标系查看上面kitti里面的坐标系定义】从激光点云坐标系变换到0号相机参考坐标系中,接着将0号相机(灰色图)自身坐标系投影到矫正坐标系(与车体一起指向正前方意思)中,接着将矫正坐标系投影到2号相机(彩色图)坐标系中。通过三次投影,才能将激光点云数据投影到彩色图上。

1.4 关于激光点云处理:传统VS深度学习
1)传统:
–基于点云的目标检测:分割地面->点云聚类->特征提取->分类
–地面分割依赖于人为设计的特征和规则,如设计一些阈值、表面法线等,泛化能力差【指机器学习算法对新样本的适应能力】
–多阶段的处理流程意味着可能产生复合型错误—聚类和分类并没有建立在一定的上下文基础上,目标周围的环境信息缺失
–这类方法对于单帧激光雷达扫描的计算时间和精度都是不稳定的,这和自动驾驶场景下的安全性要求(稳定、小方差)相违背
参考资料:
LIDAR-based 3D object perception
https://blog.csdn.net/AdamShan/article/details/83544089
2)深度学习(处理点云特点):End-to-End(端对端)
处理激光点云,面临的挑战:
–无结构化数据,只是一堆XYZI,没有网格这类的组织结构
–无序性:相同的点云可以由多个完全不同的矩阵表示(只是点的摆放顺序不同)
–数量变化大:图像中像素数量是常数,点云的数量可能会有很大(如:不同线的激光雷达)
–表现形式变化大:一辆车向左转,同一辆车向右转,会有不同的点云代表同一辆车
–缺少数据(采集昂贵):没有图片数据多,扫描时通常被遮挡部分数据丢失,数据稀疏
2、基于激光雷达点云的检测算法
简化版理解:将3d点云图三个平面拍个图片,放到神经网络里面,就跟正常的图片深度学习处理流程一样
2.1 Pixel-Based(基于像素)
1)基本思想:
–3d->2d,三维点云在不同角度的相机投影(映射)【不一定需要上一面说的坐标转换,只是单纯投影可以了】
–再借助2d图像处理领域成熟的深度学习框架进行分析
2)典型算法
–MVCNN MV3D AVOD
–Applo2.0 SqueezeSeg
3)MVCNN(分类):
–最早用深度学习来处理点云数据的方法
–实现CAD点云模型的分类:12个角度的图像(http://vis-www.cs.umass.edu/mvcnn/)

4)MV3D
–输入:BV+FV+RGB:并非简单投影(图1左侧列),而是提取高度/密度/强度/距离等特征作为像素值(图2)
–ROI:在BV训练一个3D RPN(图1中),分别向3中视图映射得到3种ROI,并融合
–缺点:该方法在检测诸如行人和骑车人等小物体方面滞后(因为他们在BEV中特征本来就少,又属于多次降采样),并且不能容易地适应具有垂直方向上的多个物体场景(只用了BV)

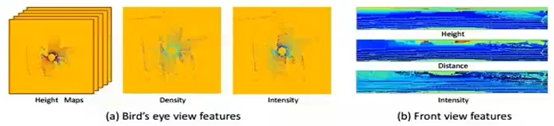

从上到下,依次是图1、图2、图3
5)AVOD
输入:BEV+RGB
–从[-40,40]x[0,70]x[0,2.5]范围内点云数据生成6-channel BEV map,分辨率0.1m,700x800x6【前面的80/0.1=800,前面的70/0.1=700,6表示的是6个通道的信息(指的是投影到鸟瞰图后)】
–Z轴上[0,2.5]平分5段,前五个通道时每个栅格单元的最大高度,第六个通道是每个单元中的米的信息(上面的6通道信息解析)
–点云转BEV实现代码:
–kitti lidar点云生成鸟瞰图BEV :
https://blog.csdn.net/weixin_39999955/article/details/83819313
– 点云处理:http://ronny.rest/tutorials/module/pointclouds_01

上面图中解析:
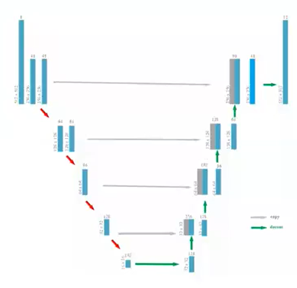
5-1)feature extractor(特征提取器)
–特征提取器由两部分组成:
Encoder(编码器) MXNXD->M/8XN/8XD*
Decoder(解码器)每层的操作包括通过conv-transpose操作上采样,与encoder中对应size的feature map连接,通过3X3的卷积操作融合两种feature maps,最终得到MxNxD特征图
–全分辨率feature map:对小目标友好
–借鉴论文FPN(feature pyramid networks)

5-2)RPN
–将feature extractor得到的feature maps通过1x1卷积操作进行降维处理减少RPN过程中的内存和计算量
–anchor6参数形式,中心点(tx,ty,tz)长宽高(dx,dy,dz),BEV上以0.5米的间距采样(tx,ty)【每0.5米生成一个anchor】,tz由传感器与地面之间的距离等因素决定。Anchors的尺寸每个类不同,从训练样本中获取70x80x0.5/0.5(num_cluster)*2(丰富的anchor对小目标友好)
–通过anchor的映射融合两种特征图:每个3d anchor投影到BEV;以及image获得两个ROI,每个roi进行crop resized to 3x3,然后进行像素级别的特征融合(特征丰富,可适应垂直方向多物体)
–在融合的特征图上训练RPN(MV3D仅在BEV上训练RPN)
–二分类:交叉熵,在BEV上通过判定anchors与ground truth的loU分辨object/background
–回归:smooth L1 loss,(▲tx, ▲ty,▲tz,▲dx,▲dy,▲dz),non-oriented?
–在BEV采用2D NMS【将不必要的框,去掉】将top k proposals送入第二阶段检测网络

5-3)second stage detector network:
–两个特征图的proposals crop resize融合:由于proposal远少于anchor就不再降维了,resize7x7,element-wise mean operation
–融合后的featurn通过三层全连接层得到类别(全分类)、bounding box、方向的输出,得到精准有方向有类别的3D bounding boxes
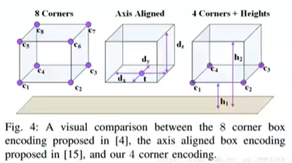
–bbox:
–采用4corner+2 height offset 编码,物体与ground plane的偏移作为gt
–回归形式是(▲x1…▲x4, ▲y1…▲y4, ▲h1, ▲h2)
–方向:
–mv3d采用估计框的长边的方向,但是很多物体不满足长边规则,例如行人
–avod种采用regressed orientation vector(逆方向矢量)以及计算(x(t),y(t))=(cos(t)),sin(t)使得t属于[-Π,Π]可以由BEV平面的惟一的单位向量表示
–每个bounding box有四个可能的朝向,选取离regressed orientation vector最近的朝向
参考:
–https://blog.csdn.net/qq_29981283/article/details/82983840
–https://blog.csdn.net/syyyao/article/details/81365400
–https://github.com/kujason/avod

2.1.1 Apollo2.0
1)Apollo2.0基于激光雷达的感知方案
–俯视图投影到地面网格(2d grid-map)每个网格计算8个统计量(图1上)
–使用UNet做障碍物分割(图3a)
–https://github.com/ApolloAuto/appollo/blob/master/docs/specs/3d_obstacle_perception.md(完整链接不存在)https://github.com/ApolloAuto/apollo(20201201这部分就有)


2.1.2 SqueezeSeg
1)属于分割任务范围,然后是属于球面投影【将激光点进行球面投影】
2)关于球面投影,就看下面几个图片解析吧,因为数学公式实在不好编辑,将就看一下:



3)球面投影个人理解:简单理解,就是获取上面顺数第二个图红色,青色弧线角度,因为R直接根据点云信息可以获取的,接着,空间中任何一个点的坐标都能根据两角和一边R表示出来。
4)点评:
4-1)任何的点云位置信息都可以使用球坐标系里面两角度一轴来描述
4-2)正常情况下,我们只关心两角度,因为这个轴就是雷达反射回来的长度属于已知量
4-3)一般情况下,我们只会取车前方90度范围的激光点云数据使用
4-4)上面的HWC=645125,其中5表示5个通道
2.1.3 CNN网络
–SqueezeNet,参数量极少,但是能够达到AlexNet精度,实时性好
–输入点云预处理后的数据64x512x5,输出同等尺度的label map(单相素分割)
–由于高度64小于其宽度512,网格主要对带宽进行降维(通过Max Pooling)(图2)
–conv14层的输出即对每个点的分类概率映射(分割)
–最后被输入到一个条件随机场中做进一步矫正


从上到下,图1,图2
从上面的图宽度缩小程度,可以知道,对宽度进行了降维。同时,该图的处理过程对应代码https://github.com/andylei77/SqueezeSeg_Ros/blob/master/script/squeezeseg/nets/squeezeSeg.py
2.1.4 CRF(conditional Ranoom Field 条件随机场)
1)单纯的CNN逐像素分类结果会出现边界模糊的问题(下采样丢失细节),为解决该问题,CNN输出的label map被输入到一个CRF(由RNN实现)进一步矫正CNN输出的label map
2)CRF原理:
–将像素分类问题看作为相似像素之间的概率推理问题,两个相近点具有相似的强度值极有可能属于同一个目标
–参考论文《Conditional Random Fields as Recurrent Neural Networks》如何将mean-field CRF inference 作为Recurent eural Network(RNN)的方法,在前向过程中对CNN粗糙的输出精细化,同时在训练时将误差返回给CNN
3)优点:速度快
4)缺点:
–分割的精度仍然偏低
–需要大量的训练集,而语义分割数据集标注困难
–改进版:SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud
5)代码:
–https://github.com/andylei77/SqueezeSeg_Ros(课程展示)
–http://wiki.ros.org/sensor_msgs
6)参考:
– https://blog.csdn.net/AdamShan/article/details/83544089
– https://github.com/AbangLZU/SqueezeSeg_Ros
–https://github.com/BichenWuUCB/SqueezeSeg

2.2 基于激光雷达点云的检测算法_ Voxel-Based(基于体素)
1)基本思想:
–将点云划分为均匀的空间三维体素(体素网格提供了结构,体素数量像图片一样是不变的,解决了顺序问题)
–优点:表达方式规整,可以将卷积池化等神经网络运算迁移到三维
–缺点:体素表达的数据量大(计算量很大,例如256x256x256=16777216),一般会减少分辨率(引入量化误差/局限性 例如64x64x64)
2)典型算法
–VoxNet: A 3D Convolutional Neural Network for Real-Time Object
Recognition
–Volumetric and Multi-View CNNs for Object Classification on 3D Data
–VoxelNet: Voxel-Based + Point-Based(局部+全局)

2.3 基于激光雷达点云的检测算法_ Tree-Based(基于树结构)
1)基本思想:
–使用tree来结构化点云,对稀疏点云进行高效地组织,再套用成熟的神经网络处理
–优点:与体素相比,是更高效的点云结构化方法(该粗就粗,该细的细)
–缺点:仍然需要额外步骤对数据进行处理(类似体素化),所以在端到端处理方面存在劣势
2)典型算法:
2-1)OctNet: Learning Deep 3D Representations at High Resolutions
–八叉树
–这一表示关注于相关稠密区域的内存分配和计算,使得3D卷积网络能够做既深又高分辨率(下图1)
–通过分析一些3d任务上的分表率,来展示octnet的作用,包括3D物体分类,方向估计和点云标注
2-2)O-CNN: Octree-based Convolutional Neural Networks for 3D Shape
Analysis
–八叉树将三维点云划分为若干节点组成的一定顺序结构
2-3)Escape from Cells: Deep Kd-Networks for the Recognition of 3D Point Cloud Models
–kd树

2.3 基于激光雷达点云的检测算法_Point-Based(基于点方式)
上面几种算法,都是需要对点云进行预处理的,这个基于点方式,是直接对点云进行处理的。
1)激光点云特征(处理需要解决的问题):
1-1)无序性
–点云本质上上一堆点(nx3矩阵,其中n是点数),点的顺序不影响其在空间中对整体形状的表示(相同点云可以由两个完全不同的矩阵表示)【图2右】
–希望不同的点云顺序可以得到相同的特征提取结果,可以用对称函数g(例如maxpooling或sumpooling)【图2左】
1-2)旋转/平移性
相同点云在空间中经过一定的刚性变化(旋转或平移)坐标变化
希望不论点云在怎样的坐标系下呈现网络都能正确识别出,可以通过STN(spacial transform network)解决【图1】


从上到下,依次图1,图2
2)基本思想:
–直接对点云进行处理,使用对称函数姐姐点的无序性,使用空间变换解决旋转/平移性
3)代表作品:
–PointNet PointNet++ -> Frustum-PointNet、PointRCNN
–PointCNN
参考:https://blog.csdn.net/qq_15332903/article/details/80224387
2.3.1 PointNet(cvpr2017)
1)核心点:
1-1)maxpooling作为对称函数解决无序性问题:每个点云分别提取特征之后,maxpooling可以对点的整体提取出global feature
1-2)空间变换网络解决旋转问题:三维的STN可以通过点云本身的位姿信息学习(loss调整)到一个最有利于网络进行分类或分割的变换矩阵,将点云变换到合适视角(例如 俯视图看车,正视图看人)
1-2-1)两次STN,第一次input transform可以理解为将原始点云旋转出一个更有利于分类或分割的视角,第二次feature transform是在特征层面对点云进行变换
【上述1-1)、1-2)可以结合图1加深理解】
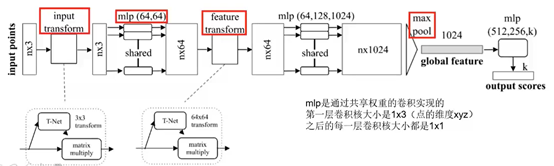
Mlp指的是全连接层
下图代码来源:
https://github.com/charlesq34/pointnet/blob/master/models/pointnet_cls.py

def get_model(point_cloud, is_training, bn_decay=None):""" Classification PointNet, input is BxNx3, output Bx40 """#BxNx3,B表示batch_size,100张点云图;N表示每个点云图有多少个点;3表示xyz坐标batch_size = point_cloud.get_shape()[0].valuenum_point = point_cloud.get_shape()[1].valueend_points = {}with tf.variable_scope('transform_net1') as sc:transform = input_transform_net(point_cloud, is_training, bn_decay, K=3)#input_transform_net,表示变换,将BxNx3*Bx3x3->BxNx3point_cloud_transformed = tf.matmul(point_cloud, transform)input_image = tf.expand_dims(point_cloud_transformed, -1)#这里扩充了维度,BxNx3->BxNx3x1net = tf_util.conv2d(input_image, 64, [1,3],#[1,3],将BxNx3x1->BxNx1x64,通过64个1x3卷积核进行卷积实现全连接层,对每一个点独立抽取特征padding='VALID', stride=[1,1],bn=True, is_training=is_training,scope='conv1', bn_decay=bn_decay)net = tf_util.conv2d(net, 64, [1,1],#BxNx1x64->BxNx1x64,使用64个1x1卷积核padding='VALID', stride=[1,1],bn=True, is_training=is_training,scope='conv2', bn_decay=bn_decay)with tf.variable_scope('transform_net2') as sc:transform = feature_transform_net(net, is_training, bn_decay, K=64)#feature_transform_net,end_points['transform'] = transformnet_transformed = tf.matmul(tf.squeeze(net, axis=[2]), transform)#squeeze函数作用,BxNx1x64->BxNx64,去掉1;然后BxNx64*Bx64x64->BxNx64net_transformed = tf.expand_dims(net_transformed, [2])#expand_dims将维度扩充回来,BxNx64->BxNx1x64#对应流程图,mlp(64,128,1024)net = tf_util.conv2d(net_transformed, 64, [1,1],#通过卷积方式是实现全连接的,使用64个1x1卷积核对BxNx1x64进行卷积,得到BxNx1x64,也就是BxNx1x64->BxNx1x64padding='VALID', stride=[1,1],bn=True, is_training=is_training,scope='conv3', bn_decay=bn_decay)net = tf_util.conv2d(net, 128, [1,1],#基本含义同上64位置解析,BxNx1x64->BxNx1x128padding='VALID', stride=[1,1],bn=True, is_training=is_training,scope='conv4', bn_decay=bn_decay)net = tf_util.conv2d(net, 1024, [1,1],#基本含义同上64位置解析,BxNx1x64->BxNx1x1024padding='VALID', stride=[1,1],bn=True, is_training=is_training,scope='conv5', bn_decay=bn_decay)# Symmetric function: max poolingnet = tf_util.max_pool2d(net, [num_point,1],#max_pool2d表示池化,这句话意思是通过Nx1卷积对BxNx1x1024进行池化,得到Bx1x1x1024,也就是BxNx1x1024->Bx1x1x1024padding='VALID', scope='maxpool')net = tf.reshape(net, [batch_size, -1])#reshape,将Bx1x1x1024->Bx1024net = tf_util.fully_connected(net, 512, bn=True, is_training=is_training,#真正意义的全连接层开始,对比流程图中mlp(512,256,k),由于案例中右40个分类,所以k=40scope='fc1', bn_decay=bn_decay)net = tf_util.dropout(net, keep_prob=0.7, is_training=is_training,#keep_prob表示的是辍学率(keep_prob值是用来控制/调整训练神经网络时使用的辍学率);个人理解为废弃率scope='dp1')net = tf_util.fully_connected(net, 256, bn=True, is_training=is_training,scope='fc2', bn_decay=bn_decay)net = tf_util.dropout(net, keep_prob=0.7, is_training=is_training,scope='dp2')net = tf_util.fully_connected(net, 40, activation_fn=None, scope='fc3')#40return net, end_points
上述代码是解析上面图1的流程图,展示使用PointNet进行分类问题;其中,关键点是,利用卷积独立地对每个点进行抽特征。
下面代码,是对上面调用的转换函数进行说明的:

def input_transform_net(point_cloud, is_training, bn_decay=None, K=3):#输入是BxNx3点云,输出的是Bx3x3变换矩阵""" Input (XYZ) Transform Net, input is BxNx3 gray imageReturn:Transformation matrix of size 3xK """#BxNx3batch_size = point_cloud.get_shape()[0].value#表示Bnum_point = point_cloud.get_shape()[1].value#BxNx3->BxNx3x1input_image = tf.expand_dims(point_cloud, -1)net = tf_util.conv2d(input_image, 64, [1,3],#conv2d,使用卷积方法(卷积核是1x3,个数64)对每个独立点云抽特征,BxNx3x1->BxNx1x64padding='VALID', stride=[1,1],bn=True, is_training=is_training,scope='tconv1', bn_decay=bn_decay)net = tf_util.conv2d(net, 128, [1,1],#BxNx1x64->BxNx1x128padding='VALID', stride=[1,1],bn=True, is_training=is_training,scope='tconv2', bn_decay=bn_decay)net = tf_util.conv2d(net, 1024, [1,1],#BxNx1x128->BxNx1x1024padding='VALID', stride=[1,1],bn=True, is_training=is_training,scope='tconv3', bn_decay=bn_decay)net = tf_util.max_pool2d(net, [num_point,1],#max_pool2d,BxNx1x1024->Bx1x1x1024padding='VALID', scope='tmaxpool')net = tf.reshape(net, [batch_size, -1])#Bx1x1x1024->Bx1024net = tf_util.fully_connected(net, 512, bn=True, is_training=is_training,#fully_connectedscope='tfc1', bn_decay=bn_decay)#Bx1024->Bx512net = tf_util.fully_connected(net, 256, bn=True, is_training=is_training,scope='tfc2', bn_decay=bn_decay)#Bx512->Bx256with tf.variable_scope('transform_XYZ') as sc:assert(K==3)weights = tf.get_variable('weights', [256, 3*K],initializer=tf.constant_initializer(0.0),dtype=tf.float32)biases = tf.get_variable('biases', [3*K],initializer=tf.constant_initializer(0.0),dtype=tf.float32)biases += tf.constant([1,0,0,0,1,0,0,0,1], dtype=tf.float32)transform = tf.matmul(net, weights)#Bx256->Bx3Ktransform = tf.nn.bias_add(transform, biases)transform = tf.reshape(transform, [batch_size, 3, K])#Bx3K->Bx3xKreturn transform#最后返回的是Bx3x3
代码源自:https://github.com/charlesq34/pointnet/blob/master/models/transform_nets.py#L6
2.3.2 PointNet++(NIP2017)
1)PointNet:单个点云特征->全局特征【这种一步登天做法是很有问题的】,中间缺少局部信息(相当于用了很大的卷积核/pooling只做了一层卷积/pooling感受野一下就变最大)单个PointNet操作可以看作一种特殊的卷积操作(单像素抽取特征+global max pooling 或许应该放弃对单像素抽特征,没有利用领域信息,根本没有意义。除非放个像素包含了各个领域信息,例如减去中心点,直接卷积【需要卷积具有对称性:例如,卷积核内的所有权值相等?】)
2)PintNet++:单个点云特征->局部点云特征->更大局部点云特征->…->全局信息 (相当于多次卷积,感受野逐渐变大)【升级版本是解决上面一步登天问题】

3)ModeINet40上的准确率达到了由89.2%(PointNet)提高到90.7%(PointNet++)【下图对应的是升级版的操作流程】
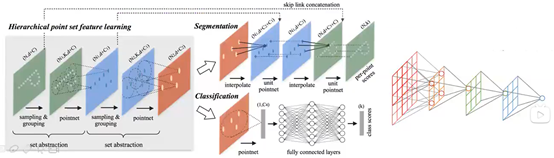
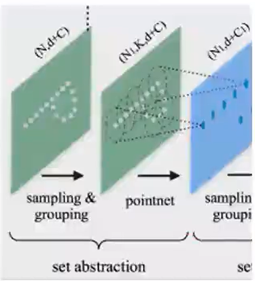
4)核心点set abstraction(PointNet/++)
–采样:选取一些比较重要的点作为每一个局部区域的中心点
–分组:在这些中心点的周围选取k个近邻点(欧式距离给定半径内)
–PointNet:使用PointNet提取局部特征(一次PointNet相当于做一次卷积,故而称作PointNet卷积),点云子集的特征
–结果输出到下一个set abstraction重复这个过程
5)解决点云密度不均匀问题:激光扫描时会出现采样密度不均的问题,所以通过固定范围选取的固定个数的近邻点是不合适的,PointNet++提出了两个解决方案:
–多尺度分组【如图a,多个圈圈选取】:在每一个分组层,都通过多个尺度来确定每一个中心点的领域范围,并经过PointNet提取特征后将多个特征拼接起来,得到一个多尺度融合的新特征
–多分辨率分组【如图b,分2级到contact,一级到contact】:多尺度融合的做法,对于每一个中心点都需要多个patch的选区域提取特征,计算开销很大,多分辨率分组法是考虑多种分辨率的融合。左边特征向量【图b,contact横线的左侧点】是通过一个set abstraction
得到的(多次PointNet卷积),右边特征向量【图b,contact横线的右侧点】是直接对当前patch中所有点进行Pointnet卷积得到。并且当点云密度不均时,可以通过判断当前patch的密度对左右两个特征向量给予不同权重。例如,当patch中的密度很小,左边向量得到的
信息就没有对所有patch中心提取的特征的可行度更高,于是将右特征向量的权重提高,以此,达到减少计算量的同时解决密度问题。

Code:https://github.com/charlesq34/pointnet2
2.3.3 PointCNN
–PointNet:点云分别提取特征(顺序无关)->对称函数解决顺序问题(maxpooling)。”处处小心顺序问题”
–PointCNN:点云领域提取特征(顺序相关)->用X变换解决顺序问题。“前期大胆做/后期统一变”【匹对下图】

2.3.4 Frustum-Pointnet
–提取视锥体:RGB提取2D box(ROI) ,2D box -> 3D 视锥体(使用相机投影矩阵)
–分割视锥体内点云,分割得到物体实例,分割(3d mash 类似Mash-RCN在ROI内做二分类)
–3D box
Code: https://github.com/charlesq34/frustum-pointnets

2.3.5 PointRCNN
–3D RRN from raw point(使用PointNet++提取特征)
–Refining 3D proposals
–论文:https://arxiv.org/pdf/1812.04244.pdf


2.4 小结(综合上述几种算法)
解决顺序问题(结构问题)
–Pixel-Based:2D-grid【基于像素,将激光点云投影到2d网格】
–Voxel-Based:3D-grid【基于体素,将激光点云划分为3d网格】
–Tree-Based:Tree struct【基于树,利用树结构划分点云】
–Point-Based:对称函数/X变换【基于点,解决激光点云顺序问题】
3 基于激光雷达点云的检测算法_实战基于点云的目标检测
Voxel net
3.1基本介绍
1)基本思想:在3D网格单元上使用Pointnet学习的特征,而不使用手工制作的网格特征(例如h_max等)
2)整体框架:
–输入:仅使用激光雷达数据
–特征学习网络
–卷积中间层网络
–区域提取网络(RPN)
3)优缺点:
–准确度很高
–但在TitanX GPU上只有4fps的低速度
4)参考:
https://blog.csdn.net/AdamShan/article/details/84837211
https://github.com/qianguih/voxelnet
https://github.com/AbangLZU/VoxelNetRos【实战代码的原始作者版本】

3.2 代码原理分析
1)特征学习网络
–体素分块(Voxel Partition)输入点云(D,H,W)体素的深高宽为(vD,vH,vW),经过处理得到网格大小,voxel grid(D/(vD), H/(vH), W/(vW))
–点云分组(Grouping)将点云按照上一步分出来的体素格进行分组
–随机采样(Random Sampling)每一个体素随机采样固定数目的点T。因为 :
–a)网格单元内点云数量不均匀
–b)且64线一次扫描点云的数量巨大(10w),全部处理需要消耗很多CPU和内存
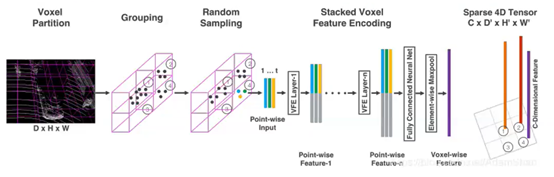
2)
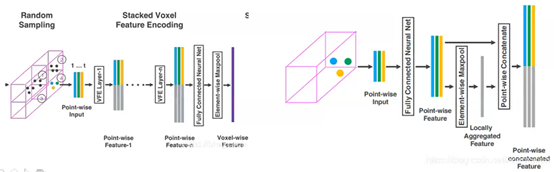
3)稀疏张量表示(Sparse Tensor Representation):
–一系列的体素特征可以使用一个4维的稀疏张量来表示,C x D’ x H’ x W’
–一次lidar扫描包含接近10万格点,但是超过90%的体素格是空的,使用稀疏张量来描述非空体素格,能够减低反向传播时的内存和计算消耗
4)代码中(针对KITTI car)
–沿着lidar坐标系(z,y,x)方向分别对应取[-3,1]x[-40,40]x[0,70.4]立方体(米)作为输入点云
–体素大小
–体素网格大小
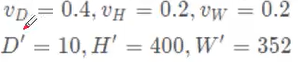
图中,vd,vh,vw分别对应的是 ZYX
–每个体素网格内随机采样T=35个点云
–两个VFE层VFE-1(7,32)和VFE-2(32,128)输出128维的Voxel-wise特征
–特征学习网络的输出,即为一个稀疏张量[batchsize,10,400/200,352/240,128]【10就是Z轴对应的4/0.4;400就是80/0.2;325就是70.4/0.2;里面的200,240属于对人情况的,因为分辨率(如前面的0.4,0.2)改变,得到结果不一样的;128就是维度】
代码:https://github.com/qianguih/voxelnet/blob/master/model/group_pointcloud.py
5)卷积中间层网络:
–类似PointNet中的:分层多次卷积->小邻域变大邻域
–每个卷积中间层ConvMD:3维卷积+BN层+非线性层(ReLU) 参数:3:3d c_in c_out:输入输出通道 k:卷积核(k,k,k) s:stride p:padding
–[batchsize,10,400/200,352/240,128]-> [batchsize, 400/200,352/240,128]【中间层会多卷一下】
–https://github.com/qianguih/voxelnet/blob/master/model/rpn.py
# convolutinal middle layerstemp_conv = ConvMD(3, 128, 64, 3, (2, 1, 1),(1, 1, 1), self.input, name='conv1')temp_conv = ConvMD(3, 64, 64, 3, (1, 1, 1),(0, 1, 1), temp_conv, name='conv2')temp_conv = ConvMD(3, 64, 64, 3, (2, 1, 1),(1, 1, 1), temp_conv, name='conv3')temp_conv = tf.transpose(temp_conv, perm=[0, 2, 3, 4, 1])temp_conv = tf.reshape(temp_conv, [-1, cfg.INPUT_HEIGHT, cfg.INPUT_WIDTH, 128])
这一小节代码,就是解析卷积中间层网络的【个人还是没有理解背后的具体含义20201214】
6)区域提取网络(RPN)
–三个全卷积层块(Block),每次尺度减半
–每一个快的输出都是采样到相同尺寸进行串联得到高分辨率特征图
–输出:
–Probability Score Map(二分类 例如是否为车) [None,200/100,176/120,2]
–Regression Map(位置修正) [None,200/100,176/120,14] 【14,因为一个特征点映射回原图的话,对应两个box,每个box有7个值(3个中心点+3个宽高+旋转1个偏差)】
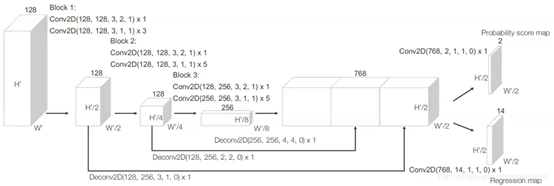
代码来自:https://github.com/qianguih/voxelnet/blob/master/model/rpn.py
代码中这些block都是上面流程图中的实现
# block1:temp_conv = ConvMD(2, 128, 128, 3, (2, 2), (1, 1),temp_conv, training=self.training, name='conv4')temp_conv = ConvMD(2, 128, 128, 3, (1, 1), (1, 1),temp_conv, training=self.training, name='conv5')temp_conv = ConvMD(2, 128, 128, 3, (1, 1), (1, 1),temp_conv, training=self.training, name='conv6')temp_conv = ConvMD(2, 128, 128, 3, (1, 1), (1, 1),temp_conv, training=self.training, name='conv7')deconv1 = Deconv2D(128, 256, 3, (1, 1), (0, 0),temp_conv, training=self.training, name='deconv1')
4.其他
答疑:
1)激光雷达扫描,只是获取两个角度和R值,而我们所看见的xyz值,是前面获取后,转换得到的
2)ROS,属于一种通信框架,目前适用于科研这类,实际使用的话,还是不能够满足车规级需要的
3)阿波罗2.0时候,采用激光雷达和高精地图作为主,这时候就主要激光点云数据处理;3.0版本时候,选择图像和毫米波雷达为主,这时候,就图像处理为主
4)这节课程中,有实战代码的,是需要重点学习的
个人小结:
这节课,介绍激光雷达点云处理算法。这些算法,基本上是深度学习方面的;也实战了一些基于激光点云处理基于神经网络算法案例。但是,很遗憾,虽然老师讲的很细,也图文并茂,但里面的代码和流程图还是很多地方不懂,主要因为相关知识太缺。
没错,菜是原罪。进步空间巨大。
各位小伙伴,链接里面的参考文献找不到的话,欢迎私聊哈。
#####################
不积硅步,无以至千里
好记性不如烂笔头
图片版权归原作者所有
感恩授课老师的付出
这篇关于self_drive car_学习笔记--第5课:动态环境感知与3D detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









