本文主要是介绍ACM MM 2023| CLE Diffusion:可控光照增强扩散模型(low light image enhancement),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文介绍了由北交大、UT Austin、A*Star团队提出的基于扩散模型的可控低光增强方法,论文被ACM MM 2023收录。

Paper Name:CLE Diffusion: Controllable Light Enhancement Diffusion Model
Keywords:Low light image enhancement, diffusion model, image processing
Paper Link:https://arxiv.org/abs/2308.06725
Code Link:https://github.com/YuyangYin/CLEDiffusion
Web Link:https://yuyangyin.github.io/CLEDiffusion/
Introduction
低光图像增强技术近年来受到了广泛的关注,目前的方法通常假设一个理想的增亮程度,对图像整体进行均匀的增强,同时也限制了用户的可控性。为了解决这个问题,本文提出了可控光照增强扩散模型(Controllable Light Enhancement Diffusion Model),可以让用户输入所需的增亮级别,并利用SAM模型,来实现交互友好的区域可控增亮。
如图演示效果,用户可以通过简单的点击来指定增亮的区域。
Method
本文提出了新型的可控光照增强框架,主要采用了条件扩散模型来控制任意区域的任意亮度增强。通过亮度控制模块(Brightness Control Module)将亮度信息信息融入Diffusion网络中,并且设计了和任务适配的条件控制信息和损失函数来增强模型的能力。同时本文使用了Mask输入和SAM模型(Segment-Anything Model)来进一步增强可控性,使得用户可以通过简单的点击形式实现任意区域的增亮。整体的框架如下图所示:
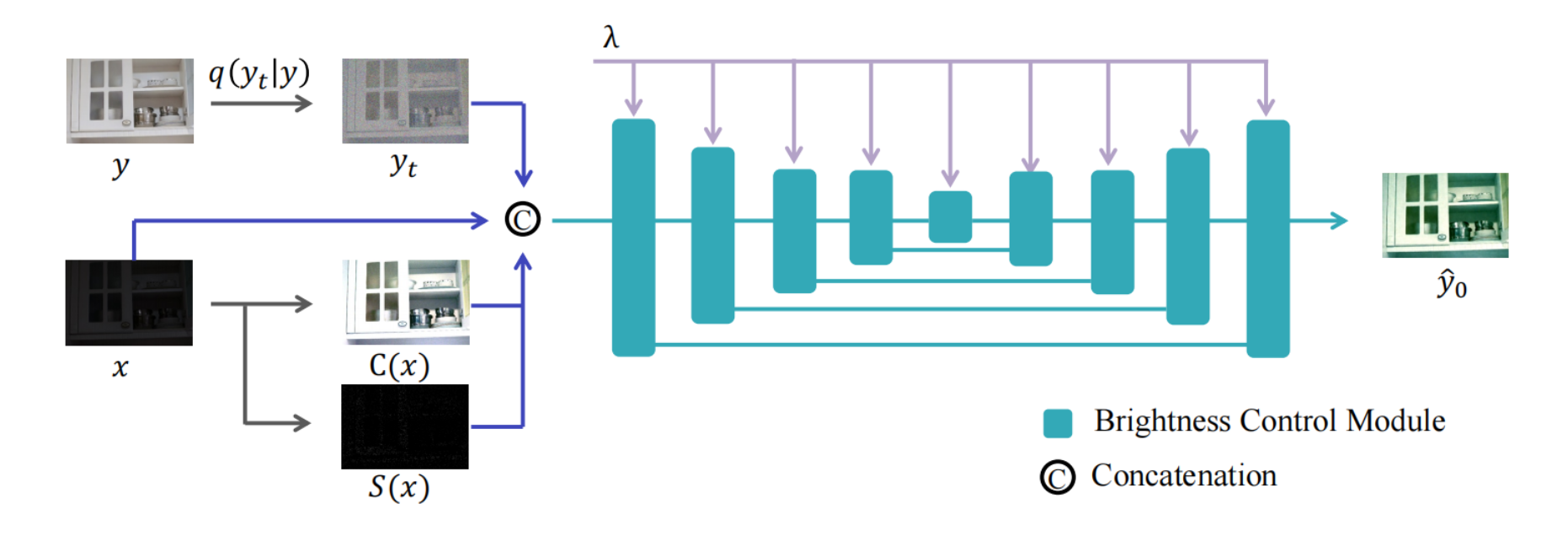
条件控制扩散模型
给定低光图像(low-light images) x x x和正常光照图像(normal-light images) y y y,相较于学习两个域的one-to-one mapping,本文更倾向于优化条件分布 p ( y ∣ x ) p(y|x) p(y∣x)。采用了DDPM来进行条件生成,实验发现简单地将low light image x x x和混合噪声的normal-light image y t y_t yt效果比较差。因此本文采用了两个额外的输入信息,来减少色彩扭曲、棋盘状噪声的问题。
Color map:
C ( x ) = x x m a x = [ x r x r , m a x , x g x g , m a x , x b x b , m a x ] C(x)=\frac{x}{x_{max}}=[\frac{x_r}{x_{r, max}},\frac{x_g}{x_{g,max}},\frac{x_b}{x_{b,max}}] C(x)=xmaxx=[xr,maxxr,xg,maxxg,xb,maxxb]
其中 x r x_r xr代表图像的红色通道, x r , m a x x_{r,max} xr,max代表图像的红色通道像素的最大值。
Snr map:
S ( x ) = F ( x ) ∣ x − F ( x ) + ϵ ∣ S(x)=\frac{F(x)}{\vert x - F(x) + \epsilon \vert} S(x)=∣x−F(x)+ϵ∣F(x)
其中 F F F代表低通滤波器(low-pass filter)来进行高斯噪声的加噪, ϵ \epsilon ϵ表示极小量。
因此整体的DDPM训练步骤可以表示为:
L simple = E y , t , ϵ [ ∥ ϵ − ϵ θ ( a ˉ t y + 1 − a ˉ t ϵ , x , C ( x ) , S ( x ) , t ) ∥ 2 ] \mathcal{L}_\text{simple}=\mathbb{E}_{{y}, t, \epsilon}\left[\left\|\epsilon- \epsilon_{\theta}\left(\sqrt{\bar{a}_{t}} {y}+\sqrt{1-\bar{a}_{t}} \epsilon, x,C(x),S(x),t\right)\right\|^{2}\right] Lsimple=Ey,t,ϵ[ ϵ−ϵθ(aˉty+1−aˉtϵ,x,C(x),S(x),t) 2]
亮度控制板块
为了高效的控制亮度信息,本文采用了classifier-free guidance(CFG)方法。CFG采用同时训练条件扩散模型(conditional diffusion model)和无条件扩散模型(unconditional diffusion model)的方式来实现。
在本任务中,将亮度值(brightness level)视作class label,由于亮度具有连续性,我们的class label也是连续的,可以实现更精细的亮度调节。
对于条件扩散模型,本文通过计算normal-light image的平均亮度 λ \lambda λ,然后通过orthogonal matrix将其在编码成illumintion embedding。然后通过FiLM layer将其注入到UNet的feature map中。
对于无条件扩散模型,本文将illumintion embedding的值设置为0。
实验中为了提升采样速度,采用DDIM采样的办法,因此总体的算法流程可以总结为:

区域控制增亮
在实际增亮过程中,用户相比于全局增亮图片其实更加关注区域的亮度控制,本文采用了Mask-CLE Diffusion来解决这个问题。
首先采样了一批羽化边缘的随机mask,通过将normal-light image和mask混合得到了一个新的合成数据集。然后将mask信息拼接到扩散模型的输入中,训练得到新的增亮模型。
SAM(Segment-Anything Model)可以实现任意图片的分割。在SAM的帮助下,Mask-CLE Diffusion提供了更好的用户交互体验,可以让用户通过点击的形式获得指定区域的mask并进行增亮。
辅助损失函数
在实验过程中,仅优化 L simple \mathcal{L}_\text{simple} Lsimple 并不能实现较好的效果,因此本文增加了四个辅助损失函数。
Brightness Loss:
L br = ∣ G ( y 0 ^ ) − G ( y ) ∣ 1 \mathcal{L}_\text{br}=|{G}(\hat{y_0})-{G}(y)|_1 Lbr=∣G(y0^)−G(y)∣1
Angular Color Loss:
L col = ∑ i ∠ ( y 0 ^ i , y i ) \mathcal{L}_\text{col}=\sum_{i}{\angle\left(\hat{y_0}_i,y_i\right)} Lcol=i∑∠(y0^i,yi)
SSIM Loss:
L ssim = ( 2 μ y μ y 0 ^ + c 1 ) ( 2 σ y y 0 ^ + c 2 ) ( μ y 2 + μ y 0 ^ 2 + c 1 ) ( σ y 2 + σ y 0 ^ 2 + c 2 ) \mathcal{L}_\text{ssim} = \frac{(2\mu_{y}\mu_{\hat{y_0}} + c_1)(2\sigma_{y\hat{y_0}} + c_2)}{(\mu_{y^2} + \mu_{\hat{y_0}}^2 + c_1)(\sigma_{y^2} + \sigma_{\hat{y_0}}^2 + c_2)} Lssim=(μy2+μy0^2+c1)(σy2+σy0^2+c2)(2μyμy0^+c1)(2σyy0^+c2)
Perceptual Loss:
L lpips = ∑ l 1 H l W l ∣ ϕ V G G l ( y 0 ^ ) − ϕ V G G l ( y ) ∣ 2 \mathcal{L}_\text{lpips}=\sum_l \frac{1}{H_lW_l}\vert \phi^l_{VGG}(\hat{y_0})-\phi^l_{VGG}(y)\vert_2 Llpips=l∑HlWl1∣ϕVGGl(y0^)−ϕVGGl(y)∣2
Expriment
New Metric
目前的大部分指标通常假设理想的亮度值,但对于不同亮度的图片质量比较困难。如下图所示,PSNR和SSIM通常随着亮度变化呈现V字形的变换,而LPIPS会呈现倒V型。因此本文希望提出一个新的指标,可以衡量不同亮度下的图片质量。
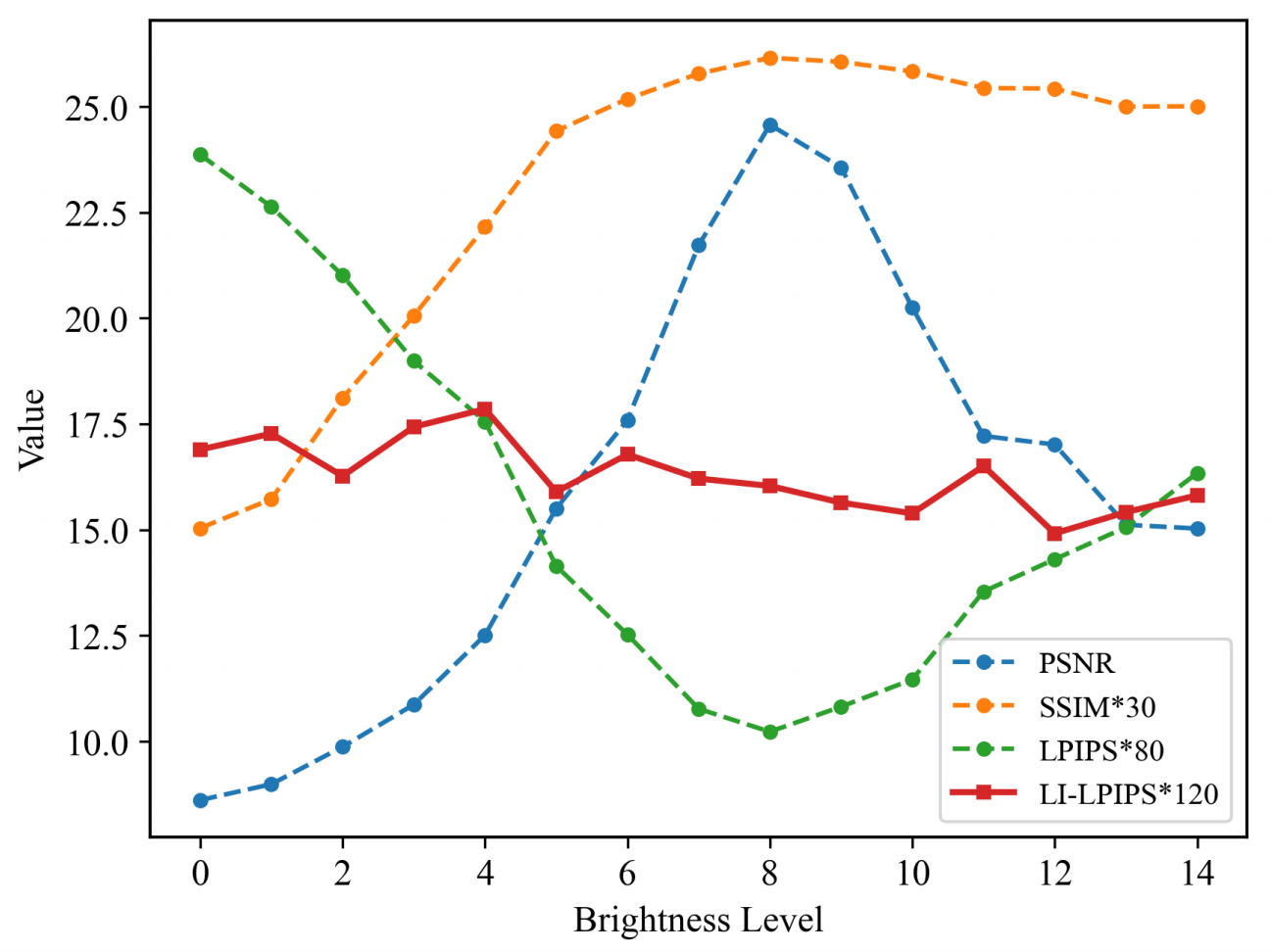
本文发现可以用color map来对亮度进行归一化,之后通过Canny边缘提取算子来衡量细节信息,最后采用LPIPS函数来衡量高频质量。
新的指标可以命名为Light-IndependentLPIPS,表示为:
L LI-LPIPS ( a , b ) = ∑ l 1 H l W l ∣ ϕ l ( Canny ( C ( a ) ) − ϕ l ( Canny ( C ( b ) ) ∣ 2 , \mathcal{L}_\text{LI\text{-}LPIPS}(a, b)=\sum_l \frac{1}{H_lW_l}\vert \phi^l(\text{Canny}(C(a))-\phi^l(\text{Canny}(C(b))\vert_2, LLI-LPIPS(a,b)=l∑HlWl1∣ϕl(Canny(C(a))−ϕl(Canny(C(b))∣2,
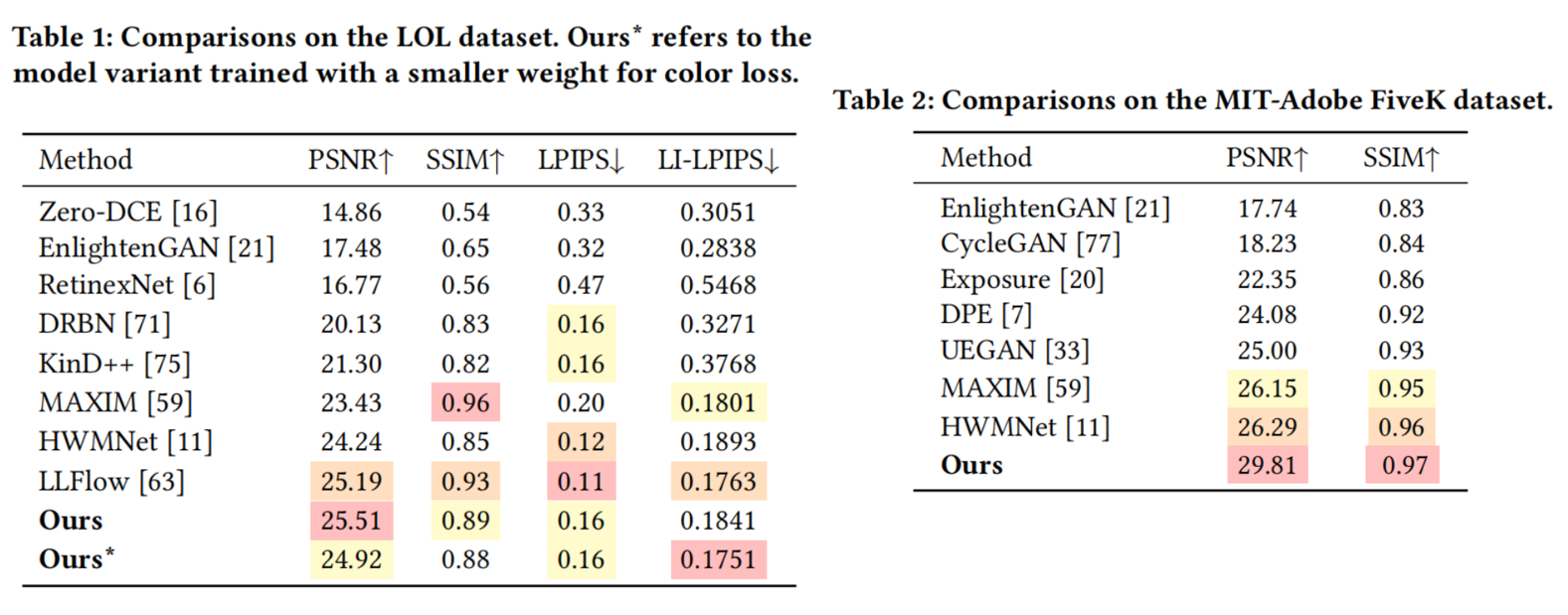
LOL和Mit-Adobe FiveK数据集上的表现
评测指标的比较:
LOL数据集上的可视化比较:

Mit-Adobe FiveK数据集上的可视化比较:

区域亮度增强
给定用户感兴趣的区域,可以实现任意亮度的增强。对比于过往低光增强方法MAXIM(CVPR 2022 Oral),具有更强的可控性和增亮效果。


全局亮度增强


和其他亮度可控方法的比较
ReCoRo只能实现在low-light到well-light之间的亮度增强,而CLE Diffusion有更广的编辑空间。

在VE-LOL数据集上的比较

在正常光照数据集上的比较

在分割模型上的表现

总结
CLE Diffusion提出了一种新型的扩散模型框架来实现可的光照增强。方法主要将亮度信息编码,利用条件扩散模型来实现可控的亮度增强。并且借助SAM模型,让用户可以选择感兴趣的区域进行增亮。大量的实验表明,方法在定量和定性上都有优异的表现。
这篇关于ACM MM 2023| CLE Diffusion:可控光照增强扩散模型(low light image enhancement)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









