本文主要是介绍采用至强® + OpenVINO加速 助力改进肺癌检测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
“经证实,Predible Health 的深度学习解决方案可有效提升放射科医生诊断精度和效率,在癌症筛查方面尤为突出。通过与英特尔合作,我们能够在医院部署解决方案,确保了工作流程的无缝融合,以及研究中的实时推理。”
——Suthirth Vaidya, Predible Health 首席执行官
肺癌是一种致命癌症,年发病量达 334 万例。据估计,每年全球因肺癌死亡的人数多达
188 万1。早期检测是长期存活的关键:四期肺癌的 5 年存活率仅为 5%。但如果在一期时就能发现,患者的 5 年存活率可达到 56%。
这正是技术的用武之地。美国国家肺癌筛查试验 (National Lung Screening Trial, NLST) 显示,接受低剂量螺旋计算机断层扫描 (Computed Tomography, CT) 的受试者死于肺癌的风险比接受标准胸部 X 光的受试者低 20%。
能够改善患者治疗效果的技术
得益于多检测器 CT 扫描技术的发展,单次屏气高分辨率容积成像能够在可接受的辐射照射水平下实现。多项观察性研究表明,对肺部进行低剂量螺旋 CT 扫描能够检测到更多结节和肺癌,包括早期癌症。潜在恶性肺结节可通过胸部 CT 扫描识别,及早干预能够提高长期存活的几率。
解决检测挑战
一次典型的胸部 CT 扫描包含 300-500 个切片,而放射科医生必须通过逐个检查切片来检测肺结节。肺结节是肺部的微小组织块,在 CT 扫描中显示为圆形、白色阴影; 大多数肺结节是良性的,它们通常难以检测和记录。肺结节的检测需要特殊的专业知识。随着肺癌筛查计划的广泛实施,放射科医生的负担正迅速加重。计算机辅助检测(Computer-aided-detection, CAD) 在帮助放射科医生解读 CT 和 MRI 扫描等高维成像数据方面所起的作用日益凸显。CAD 算法也成功提高了放射科医生检测肺结节的能力。CAD 算法原来依靠的是需要自定义工程的手动设计特征,随着深度学习和卷积神经网络(Convolutional Neural Networks, CNN) 的出现,现已开始转向通过 CNN 从数据中学习特征。
Predible 与英特尔携手应对肺癌检测的挑战*
Predible Health 和英特尔公司强强联手,共同抗击肺癌。用于在 CT 扫描图中检测肺结节的 Predible Health 深度学习算法已采用英特尔® OpenVINO™ 工具套件分发版在强大的英特尔® 至强® 可扩展处理器上得到了优化。
算法、工作流程、要求
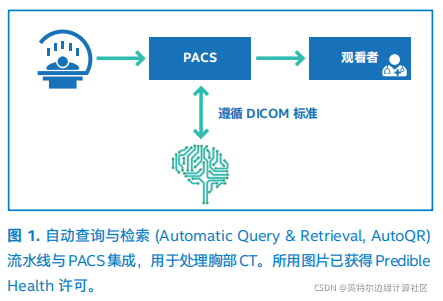
Predible 设计制作了一款软件工具,可从影像归档和通信系统(Picture Archiving and Communication System, PACS) 中自动查询胸部 CT DICOM 图像,对图像进行处理,并使用神经网络来检测肺结节。医学数字成像和通信 (Digital Imaging and Communications in Medicine, DICOM) 是处理、存储、打印和传输医学成像信息的行业标准方法。神经网络对 DICOM 系列进行处理后,结果会发送回 PACS,供放射科医生查看。
深度学习系统经过训练后,能够根据胸部 CT 扫描结果对肺结节进行检测和分割。该系统包含三个阶段,每个阶段都会使用神经网络组合来解决特定子任务。
计算要求
为预估计算要求,英特尔和 Predible Health 的研究人员假设从开始采集图像到放射科医生开始解读图像,中间的操作时间为1 小时。也就是说,深度学习算法有大约 30 分钟的时间来处理胸部 CT 扫描以及将产生的二次采集推送到 PACS,剩下 30 分钟时间进行图像采集。医院可使用专用或共享的计算资产进行基于深度学习的推理。专用计算资产成本较高,可能会限制性能,导致推理时间延长;至于共享计算资产,根据临床工作流程,计算资源共享可能会延长或缩短推理时间。
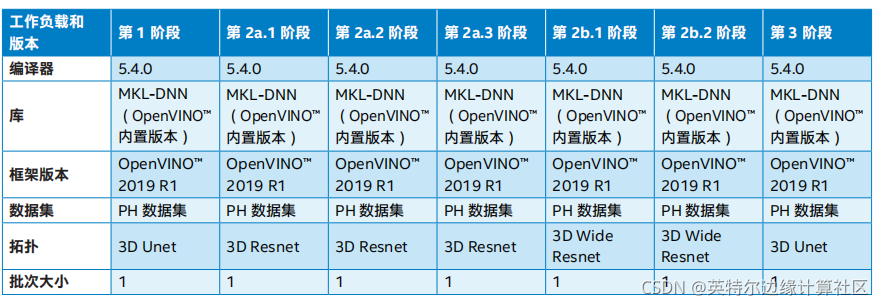
在该研究中,英特尔® OpenVINO™ 工具套件分发版针对工作流程阶段 1-3 中的图像识别优化的补丁在英特尔® 至强® 可扩展处理器上执行,并将性能与相同计算平台上未经优化的 PyTorch* 软件基准进行了比较。
其他预处理和后处理阶段未加入对比,因为这些阶段通常在已部署优化库的基于英特尔® 处理器的系统上执行。预处理和后处理阶段可能需要数分钟时间,这会根据所选的计算资产(专用或共享)而有所不同。这就为各个深度学习阶段争取到了数分钟的处理时间。
英特尔® OpenVINO™ 工具套件分发版实现的优化
在英特尔® OpenVINO™ 工具套件分发版等工具的支持下,英特尔® 至强® 可扩展处理器可为人工智能模型推理提供一个灵活的平台。
该工具套件的离线模型优化器 (Model Optimizer, MO) 可优化图形级的结构,如节点合并、批量归一化消除和常量折叠。输出结果是中间表示 (Intermediate Representation, IR) .xml 文件和包含模型权重的 .bin 文件。对于在线流程,该工具套件的推理引擎可根据目标硬件优化 MO 输出:英特尔® 至强® 处理器、英特尔® 酷睿™ 处理器、英特尔® 图形处理器、英特尔® 现场可编程门阵列 (FPGA) 或英特尔® Movidius™ Myriad™ 视觉处理器(VPU)。面向深度神经网络的英特尔® 数学核心函数库(英特尔® MKL-DNN)是开源性能库,可显著提高英特尔® CPU 上的深度神经网络的性能。
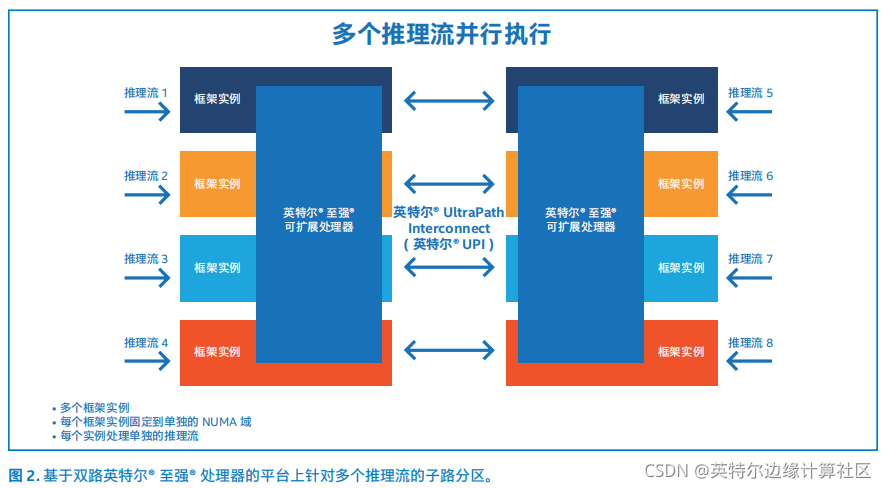
与在双路仅运行工具套件的一个实例相比,通过在 CPU 各路运行工具套件的多个实例,可进一步提高性能(参见图 2)。每个实例与一个或多个内核绑定,从而提升内核利用率。例如,如上所示,双路英特尔® 至强® 可扩展处理器上运行了工具套件的 8 个实例。
引擎可根据目标硬件优化 MO 输出:英特尔® 至强® 处理器、英特尔® 酷睿™ 处理器、英特尔® 图形处理器、英特尔® 现场可编程门阵列 (FPGA) 或英特尔® Movidius™ Myriad™ 视觉处理器(VPU)。面向深度神经网络的英特尔® 数学核心函数库(英特尔® MKL-DNN)是开源性能库,可显著提高英特尔® CPU 上的深度神经网络的性能。
与在双路仅运行工具套件的一个实例相比,通过在 CPU 各路运行工具套件的多个实例,可进一步提高性能(参见图 2)。每个实例与一个或多个内核绑定,从而提升内核利用率。例如,如上所示,双路英特尔® 至强® 可扩展处理器上运行了工具套件的 8 个实例。
性能比较
算法性能:肺叶分割模型显示肺部组织研究联盟 (Lung Tissue Research Consortium, LTRC) 数据集的平均 dice 系数为 0.95。结节检测显示,在 LIDC-IDRI 数据集中,每次 CT 扫描出现一例假阳性的敏感性和特异性比率为 89%。结节分割模型使用来自肺部图像数据库联盟 (Lung Image Database Consortium, LIDC) 和图像数据库资源计划 (Image Database Resource Initiative, IDRI) 的数据集进行了训练和验证。与参加 LIDC-IDRI 研究的放射科医生注释的轮廓交叉区域相比,该模型显示平均 dice 系数为 0.68。
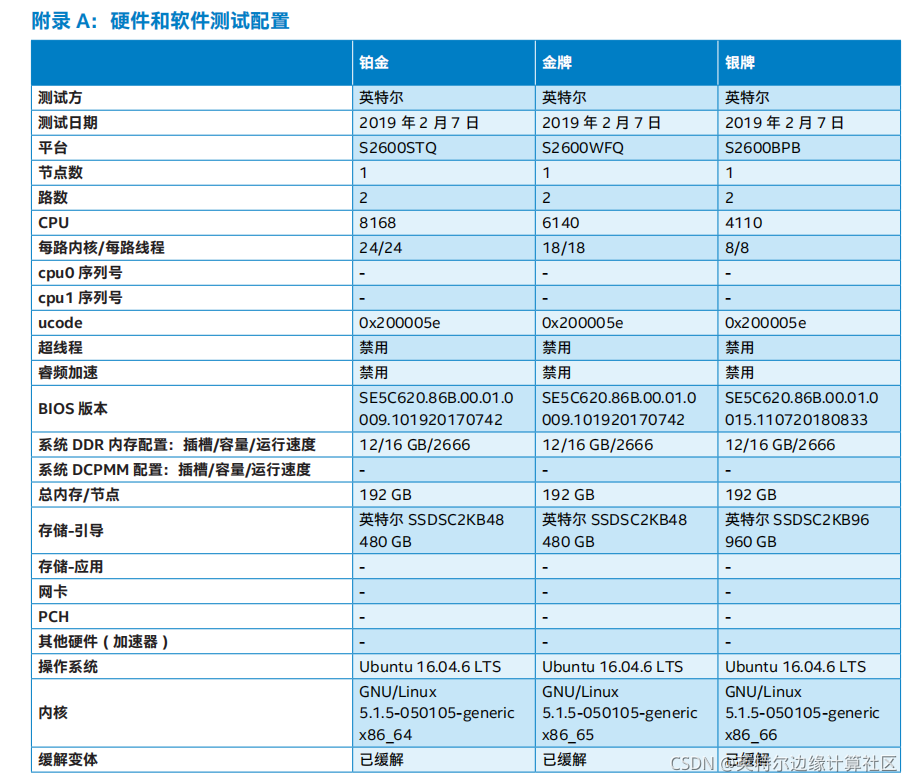
计算性能:英特尔和 Predible Health 团队选择了 3 个不同的英特尔® 至强® 可扩展处理器 SKU 作为目标实施硬件。图 3 列出了每个处理器的峰值 TFLOPS(单精度,FP32)。所有推理模型均使用 FP32 处理。附录中提供了测试所用的软硬件完整配置。
如图 4 所示,在 Predible 肺部 CT 模型的不同阶段,各个模块显示性能大幅提升。图 5 描绘了优化前与优化后 Predible 模型中每个模块的层数, 清晰地展示了该工具套件的强大力量。
有助于改进性能的三个主要优化步骤:
1.基于英特尔® OpenVINO™ 工具套件分发版的推理模型优化
2.在多路 CPU上运行英特尔® OpenVINO™ 工具套件分发版的多个实例
3.定制推理模型优化
通过定制推理模型优化,有机会合并多层或开放更多处理通道, 继而从硬件利用率提升中获益。后续版本将支持这些定制优化, 惠及更广泛的人工智能模型社区。
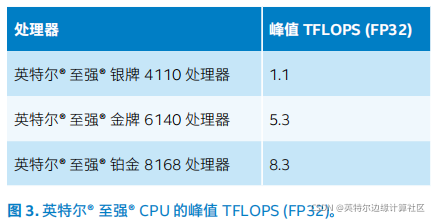

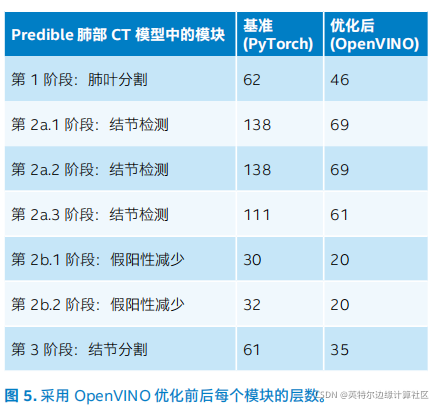
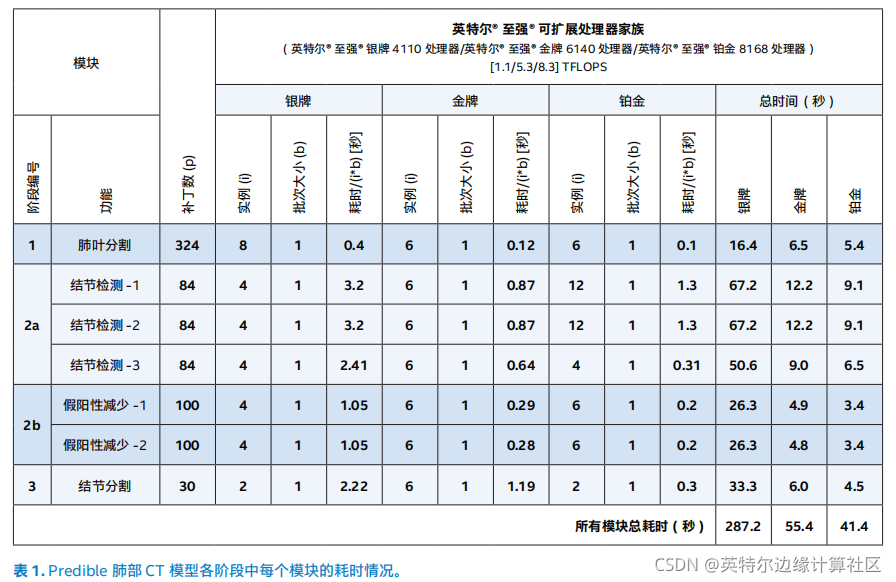
表 1 所示为肺部 CT 模型每个阶段的补丁数以及使用所选英特尔® 至强® 处理器完成每个阶段所花费的总时间。使用英特尔® 至强® 金牌和铂金 CPU 时,所有模块总耗时不到 1 分钟,使用英特尔® 至强® 银牌 CPU 时,总耗时不到 5 分钟,由此可见延迟与成本的权衡取舍。对于只执行一个推理模型的专用计算资产,比较合理的做法是选择一款符合吞吐量需求同时保持较低成本的入门级处理器。对于同时执行多个推理模型且吞吐量和延迟需求可能各有不同的共享计算资产,金牌和铂金处理器可提供所需的计算能力与敏捷性,处理具有不同性能需求的模型的并发调用。此外, 表 1 还说明了 Predible 肺部 CT 模型各阶段中每个模块所选的能在不同 CPU 上获得最佳性能的实例数和批次大小。

关注英特尔边缘计算社区,表示您确认您已年满 18 岁,并同意向英特尔分享个人信息,以便通过电子邮件和电话随时了解最新英特尔技术和行业趋势。您可以随时取消订阅。英特尔网站和通信内容遵守我们的隐私声明和使用条款。
这篇关于采用至强® + OpenVINO加速 助力改进肺癌检测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







