本文主要是介绍今日arXiv最热NLP大模型论文:无需数据集,大模型可通过强化学习与实体环境高效对齐 | ICLR2024,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言:将大型语言模型与环境对齐的挑战
虽然大语言模型(LLMs)在自然语言生成、理解等多项任务中取得了显著成就,但是在面对看起来简单的决策任务时,却常常表现不佳。这个问题的主要原因是大语言模型内嵌的知识与实际环境之间存在不对齐的问题。相比之下,强化学习(RL)能够通过试错的方法从零开始学习策略,从而确保内部嵌入知识与环境的对齐。但是,怎样将先验知识高效地融入这样的学习过程是一大挑战,为了解决这一差距,南洋理工大学在发表在ICLR2024的论文中提出了一个名为TWOSOME(True knoWledge cOmeS frOM practicE)的在线框架。它利用RL将LLMs部署为决策代理,与具体环境进行高效的交互与对齐,无需依赖预先准备的数据集或对环境的先验知识。
TWOSOME的核心思想在于使用LLMs的联合概率形成行为策略,并通过两种归一化技术结合四种提示设计原则来增强策略的稳定性和鲁棒性。此外,研究人员设计了一种创新的参数高效训练架构,使得设定的演员(actor)和评论家(critic)两种角色共享一个冻结的LLM,通过近端策略优化(PPO)更新低秩适配器(LoRA)。论文中展示了研究人员在经典决策环境Overcooked和模拟家庭环境VirtualHome中的广泛实验,对TWOSOME的性能进行了评估。实验结果显示,TWOSOME在样本效率和性能上均显著优于传统的RL方法PPO和提示调整方法SayCan。
论文标题:
True Knowledge Comes From Practice: Aligning Llms With Embodied Environments Via Reinforcement Learning
论文链接:
https://arxiv.org/pdf/2401.14151.pdf
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接。
TWOSOME框架概述:结合强化学习与大型语言模型
1. 大语言模型在决策任务中的局限
大语言模型在作为具象智能体(Embodied AI)进行简单的决策任务时,常因知识与环境不匹配而失败。例如,在制作番茄生菜沙拉的任务中,模型会错误地添加黄瓜和胡椒,即便这些成分并是非必需的。此外,大语言模型在准确把握环境的动态变化方面上存在缺陷,尤其是面对特定约束时。这种估计误差导致大语言模式更倾向于选择符合其学习常识的行动,从而无法有效解决特定领域的任务。

“具身智能体”(Embodied Agent)指的是将智能算法应用于有实体存在的机器人或虚拟角色上,使它们能够在某种物理或虚拟环境中进行感知、决策和行动。具象化的智能体不仅能够处理数据和信息,还能够与周围环境进行交互,这通常包括移动、操纵物体、通过感官收集信息等。
2. 强化学习的作用与优势
与大语言模型的训练原理不同,强化学习(Reinforcement learning,RL)可以通过环境中的试错从零开始学习策略,从而确保与环境的良好对齐。大多数RL方法起初基于随机策略,根据环境的反馈进行调整,此外,通过策略初始化和训练期间融入先验知识可以提升效率。作为大量语料库训练成果的大语言模型,是RL模型理想的先验知识来源。因此,将RL用于将大模型与特定环境对齐,不仅能解决LLMs的知识不匹配问题,也能提高RL的样本效率。
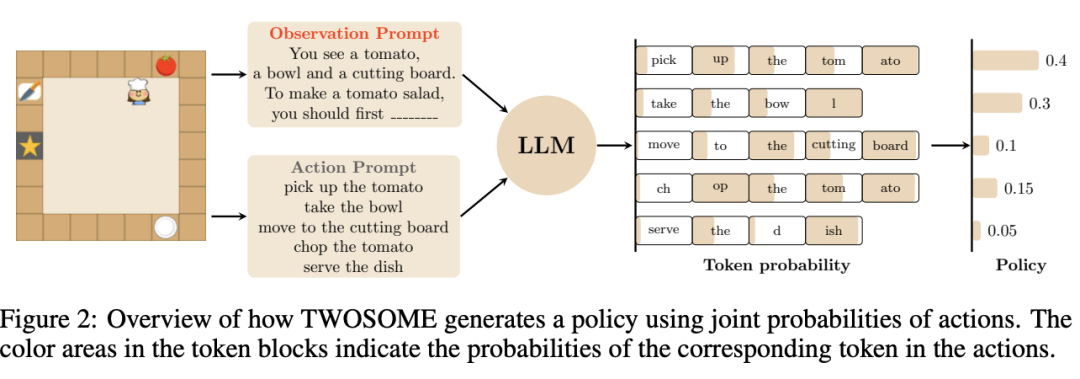
TWOSOME的工作流程:从行为策略到参数高效训练
1. 生成有效的行为策略
TWOSOME通过查询大语言模型提供的所有可能行动的分数来生成行为策略,而非直接由大语言模型决定具体行动。这一过程消除了无效行动带来的不匹配。此外,通过环境奖励优化可以利用近端策略优化(PPO)消除由动态转换引起的不匹配。
2. 动作提示归一化技术
研究人员发现,较长的动作提示由于每个token的概率均小于1,往往具有较低的联合概率,即使这些动作在环境中更合理。为解决此问题,研究人员提出了基于token数量和词数量的token归一化和词归一化两种方法,调整动作提示的不平衡。
3. 参数高效的PPO微调
研究人员采用了一种高效的训练架构,在PPO框架下生成策略。在此架构中,强化学习中的演员(actor)和评论家(critic)共享同一冻结的LLaMA-7B模型,并通过低秩适应(LoRA)等高效的参数微调方法更新。训练期间,只有评论家的MLP和演员的LoRA参数被更新,使得训练过程更加高效。LLaMA-7B模型还可以作为参考模型,规范参数的更新。
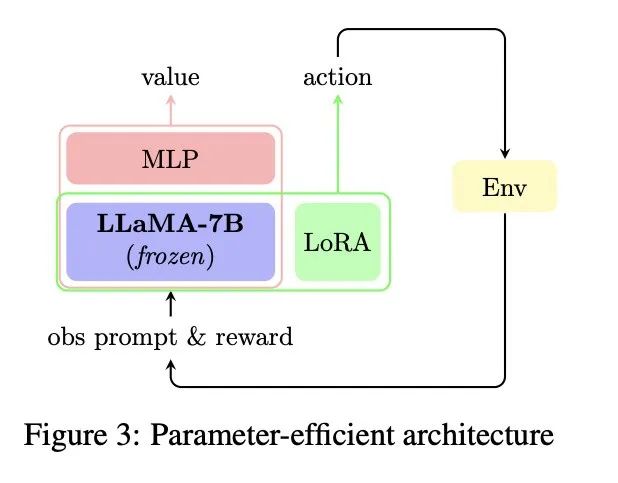
模型在推理阶段只需使用演员,舍弃评论家,大语言模型与具体环境的对齐完全编码在LoRA参数中。这样的做法使得模型的参数比LLMs的原始参数少20倍,可作为LLMs的即插即用模块,适用于不同环境的泛化。
实验设置与环境介绍
1. Overcooked与VirtualHome环境
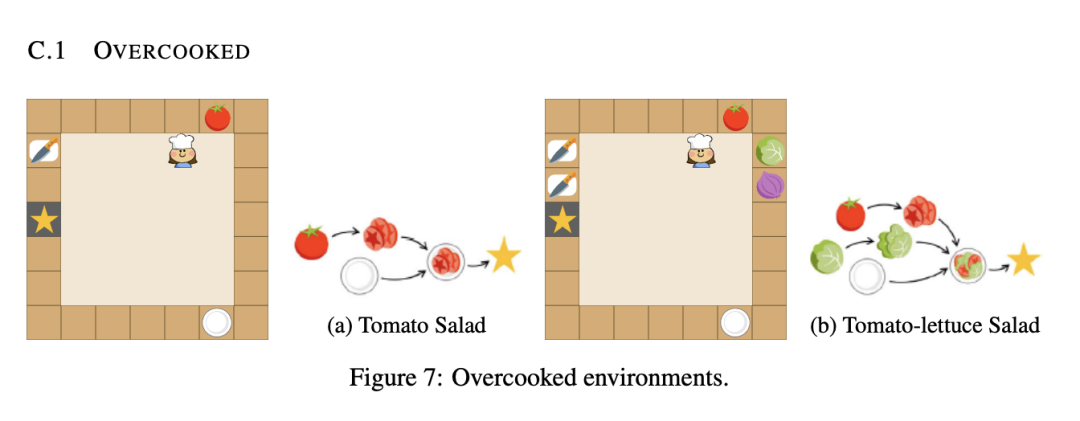
研究人员选用了两种不同的环境来评估TWOSOME框架的性能:Overcooked(图4a,4b)和VirtualHome(图4c,4d)。Overcooked是一个经典的强化学习决策制定环境,代理被置于一个7×7的厨房中,目标是制作并上菜,例如番茄沙拉和番茄生菜沙拉。代理需探索并学习正确的烹饪顺序,使用如Chop、Get-Tomato和Go-Cutting-Board等宏观动作。环境部分可观察,代理只能看到以自身为中心的5×5区域内的对象。
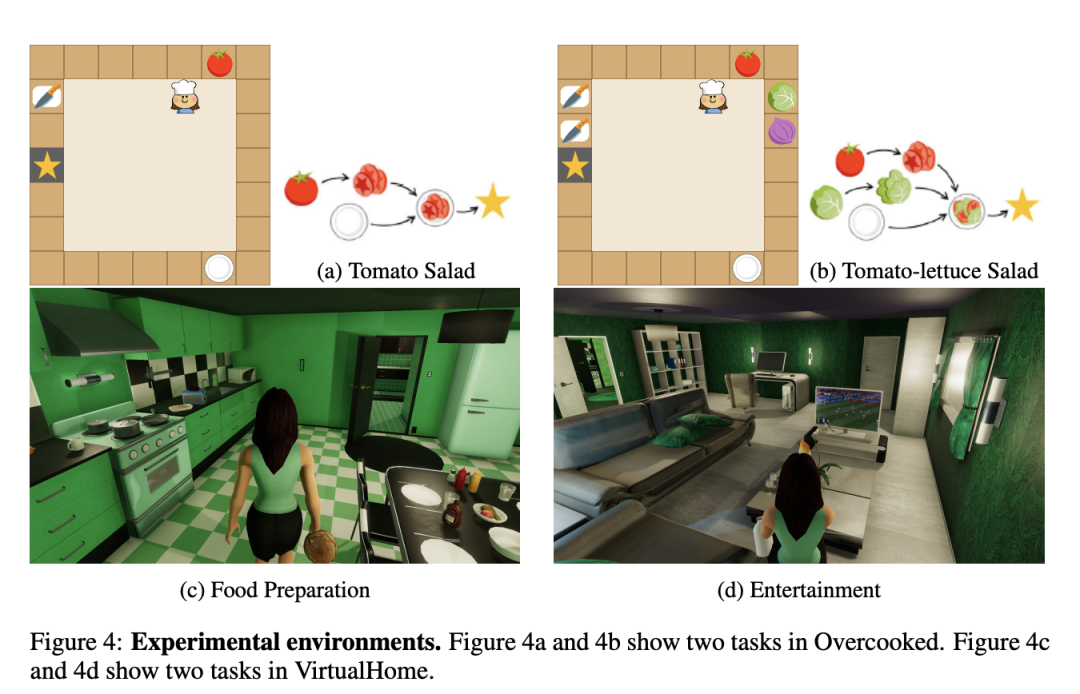
VirtualHome则是一个模拟家庭环境,比Overcooked更复杂,拥有更大、更复杂的动作空间。代理使用宏观动作与环境互动,如走到客厅、打开电视和坐在沙发上。研究人员设计了两个任务:一是需找到桌上的冷煎饼并用微波炉加热;二是计划观看电视的准备工作,需要在厨房拿起薯片和牛奶,带至客厅,打开电视,坐在沙发上享受。这两个任务均采用稀疏奖励设置,只有完成任务时代理才会获得+1奖励。
2. 实验方法对比
研究人员将TWOSOME与传统的强化学习方法PPO及提示调整方法SayCan进行了对比。在Overcooked环境中,TWOSOME展示出显著更优的样本效率和性能。在VirtualHome环境中,由于动作空间较大,传统的PPO方法未能学到有效策略,因此对研究人员对PPO添加了动作掩码。尽管如此,PPO在Entertainment任务中仍未能成功。相比之下,TWOSOME不仅样本效率出色,还所有任务中实现最佳的性能。
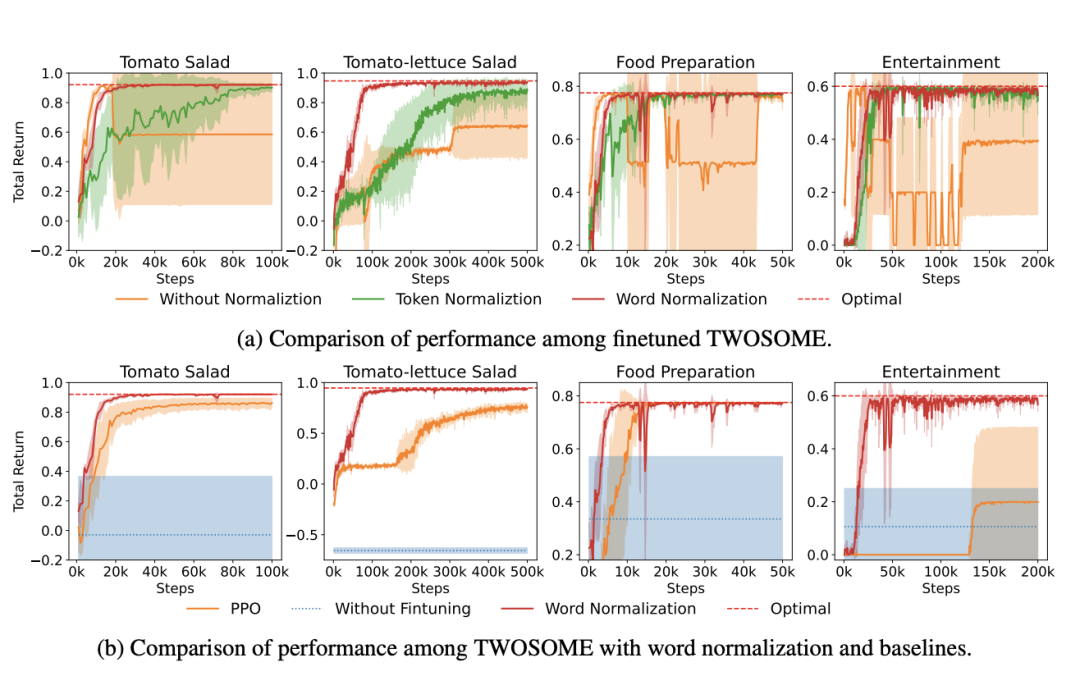
TWOSOME的性能评估
1. 样本效率与性能对比
TWOSOME在样本效率和性能方面均超越了传统的PPO方法和提示调整方法SayCan。在Overcooked环境中,TWOSOME仅需10k和80k样本即可分别学习到两个任务的最优策略,而PPO则会陷入次优策略且未能学习到最优策略。在VirtualHome环境中,TWOSOME可以有效地应对大动作空间的挑战,在Food Preparation任务中学习到了最优策略。
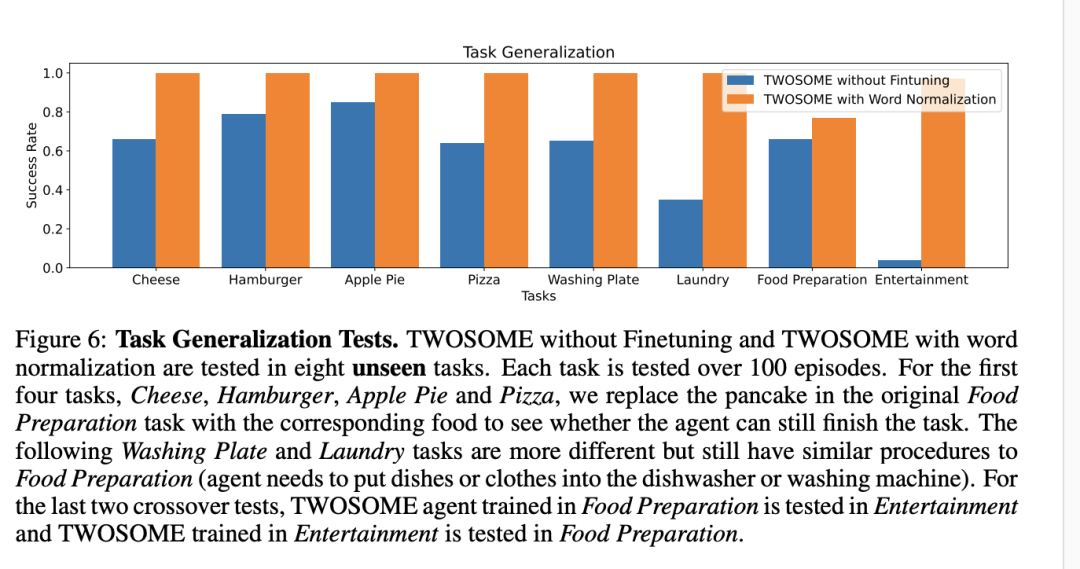
2. 任务泛化能力测试
TWOSOME在八个新的未见任务中也展现出了显著的泛化能力。得益于LLMs的开放词汇特性,TWOSOME能够将学习到的技能迁移到不同任务中,而传统RL代理则无此能力。在四个与原训练任务相似的任务中,即便未经微调的TWOSOME也能完成任务,经微调后则表现出完美性能。对于更不同的任务,如洗盘子(Washing Plate)和洗衣服(Laundry),未经微调的TWOSOME虽然成功率有所下降,但经微调后仍然可以完成任务。
TWOSOME对大型语言模型能力的影响
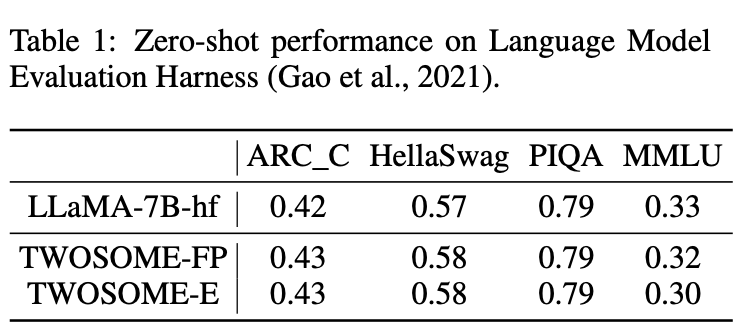
1. 在NLP基准测试中的表现
TWOSOME框架在NLP基准测试中证明了其保持了大语言模型能力上的优势。研究人员在VirtualHome环境中对TWOSOME训练出的模型在多个常见NLP任务上进行了零样本测试,包括常识推理任务、大规模多任务语言理解(MMLU)。测试结果显示,TWOSOME训练后的模型在这些任务上的表现并未显著下降,甚至在部分任务有所提升,这证明了TWOSOME在与环境互动的同时,有效保留了LLMs原有的语言理解和生成能力。
2. 在未见任务中的泛化能力
TWOSOME展现了卓越的泛化能力,训练后的TWOSOME被应用于八个未见任务中进行测试,包括与训练任务相似的食物准备任务(如制作奶酪、汉堡、苹果派和披萨)以及更具挑战性的洗盘子和洗衣服任务。在所有这些任务中,TWOSOME都成功完成,特别是在与训练任务相似的前四个任务中,表现出几乎完美的成功率。这些结果证明了TWOSOME不仅在训练环境中可以学习到有效策略,还能将所学技能、知识迁移到未见过的任务中。
讨论与结论:TWOSOME的贡献与未来展望
TWOSOME通过强化学习将大语言模型与环境对齐,解决了决策任务中的挑战。它不仅提高了样本效率,还保持了大语言模型的原始能力,并展现了在未见任务上的泛化能力。这些特性使TWOSOME在解决具身智能体决策问题方面具有显著优势。然而,TWOSOME亦存在一些局限。例如,从头开始训练PPO代理相较于微调大语言模型来说,似乎更快、更划算。此外,TWOSOME在为每个动作采样时需将所有有效动作提供给大语言模型,导致了更高的计算量和较小的批量大小。尽管存在这些限制,TWOSOME的成功为发展通用自主智能体迈出了重要一步,这些智能体能够通过与世界的互动自我提升,并从实践中获取真知。未来的工作可以专注于探索提高TWOSOME的计算效率,扩展其应用范围至更广泛的环境和任务中。此外,研究人员们还可探讨了如何提升TWOSOME的泛化能力,以更好地应对更复杂和多样的任务。随着大语言模型和RL方法的不断进步,TWOSOME及其未来版本有望在实现更智能、更灵活的具身智能体方面发挥关键作用。
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接。

这篇关于今日arXiv最热NLP大模型论文:无需数据集,大模型可通过强化学习与实体环境高效对齐 | ICLR2024的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






