本文主要是介绍《Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset》概述,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
《Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset》概述
引言:
最近阅读了本篇论文,这是一篇发表在CVPR’17年的文章,总体上的贡献在于发布了一个新的数据集以及对3D卷积+Two-Stream方法的结合形成一个新的网络架构(I3D),以下是对本篇论文的概述,如有错误,欢迎留言指正。
一、主要贡献:
- 公布了新的Human Action Video 数据:Kinetics,它有400个人类动作类以及每个类超过400个片段,收集自现实的、具有挑战性的YouTube视频;
- 作者提供了一项分析,说明当前的体系结构在此数据集的操作分类任务中进展如何,以及在进行Kinetics预训练后,在较小的基准数据集(HMDB-51 and UCF-101)上的性能改进了多少;
- 提出来一个新的模型结构 Two-Stream Inflated 3D ConvNet (I3D) ,就是将标准的Two-Stream中的卷积核变为3D卷积;
作者在文中提到了该领域现存在的一些问题:
- 现有的数据集太小,限制了视频动作识别的发展;
- 对于构建网络架构还不太明确:
- 卷积核是使用2D还是3D的卷积核;
- 网络的输入是原始RGB视频还是包括计算得到的光流信息;
- 在2D ConvNet的情况下,又如何利用LSTM或者时间上的特征融合来做到跨帧传播信息。
二、经典的网络架构:
作者列举了几种比较经典的网络架构,并在新的数据Kinetics上进行预训练观察他们的性能如何,以及和作者提出的I3D架构进行比较,下图为作者提出的网络架构模型:
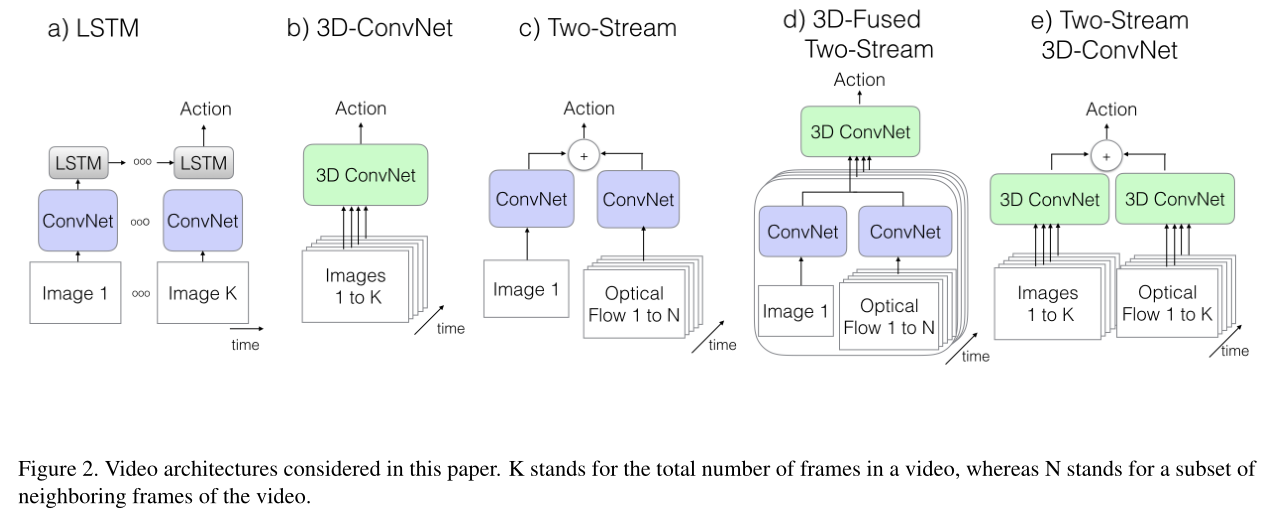
2.1 实验策略:
作者以一个普通的ImageNet预先训练的图像分类体系结构作为骨干(除了C3D),选择了带批归一化的Inception-v1,并以不同的方式对其进行变形。
2.2 模型介绍:
ConvNet+LSTM:
- 由于ConvNet结构在图片分类中表现的效果很好,因此有很多实验将其用在了视频分类中。这种方法能够独立的从每一帧中提取特征,然后综合这些特帧得到一个视频级别的特征描述;
- 虽然这在 实验中使用方便,但却完全忽略了时间结构的问题;
- 因此为了解决这一问题,通常ConvNet中添加LSTM,以此来捕获各帧之间的时间信息;
模型细节:
把一个包含512个隐含节点的LSTM 层以及BN放在Inception v1的最后一个average pooling层后面(即分类器之前),最后跟的是一个用于分类的全连接层;输入帧是在25帧/s的视频流中每5帧取1帧。
3D ConvNets:
- 它们有一个非常重要的特点:直接创建时空数据的层次表示;
- 但是由于额外添加的维度,它们比起2D卷积有更多的参数,这就使得3D卷积很难去训练;
- 由于使用的是三维的卷积核,无法直接用在ImageNet上预训练过的网络。
模型细节:
使用的是C3D模型的一个变种,8层卷积、5层pooling、2层全连接。与C3D的区别在于这里的卷积和全连接层后面加BN;且在第一个pooling层使用stride=2,这样使得batch_size可以更大。输入是16帧,每帧112*112。
Two-Stream Networks:
- LSTMs可以捕获对高层变化,但可能无法捕捉精细的低层运动,这在许多情况下是至关重要的。并且训练代价很大,因为因为它需要通过多个帧展开网络以进行时间反向传播;
- 而Two-stream从不同的角度解决了这个问题:一路是RGB帧作为输入,捕捉空间变化信息,另一路是光学作为输入,捕捉时间变化信息。这样就对时间和空间的信息提取都比较好;
- 图(c): 取一帧图像预测的结果与光学流图像预测的结果取平均;
- 图(d): 是在图(c)基础上的一种扩展,通过一个3D ConvNet对多帧的信息进行融合,取到两个Stream的最后一个average pooling层的输出,作为3D ConvNet部分的输入;
模型细节:
网络的输入是相隔10帧采样的5个连续RGB帧以及相应的光流片段。在Inception-V1最后一个average pooling 之前,使用512个 3x3x3 的卷积核,然后是一个 3x3x3 的max-pooling,最后是一个全连接层;
The New: Two-Stream Inflated 3D ConvNets:
3DConvNet可以直接从RGB流中学习时间模式,但通过包含光流的使用仍然可以极大地提高其性能,因此作者采用了Two-Stream+3D ConvNet的方式
- 把2D模型转化成3D模型结构,即把所有卷积核增加一个维度,拓展为 T T Tx N N Nx N N N;
- Bootstrapping 3D filters from 2D Filters:为了能够使用在ImageNet上预训练的权重值来初始化网络,作者通过一张图片复制 N N N次,这样就形成了一个N帧的视频,然后就可以在使用3D卷积核的网络上预训练了,最后为使得激活函数值和在2D卷积上训练单张图片保持一致,通常要将卷积计算所得的值都除以 N N N,就得到和2D卷积上一样的激活函数值了,下图来源自简书,可以参考下;
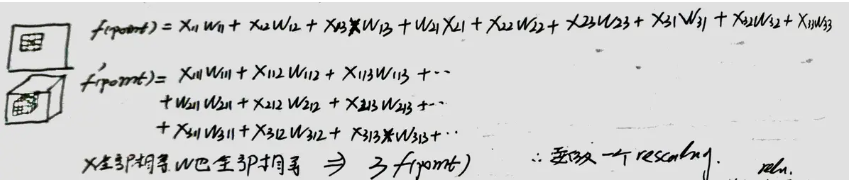
- Pacing receptive field growth in space, time and network depth :在时间维度上的感受野要如何变化,即Conv和Pooling的stride怎么选;这两个都是影响feature receptive field的主要因素
- 在Image模型中,对待水平和垂直两个空间维度往往是一致的,也就是两个维度上pooling核大小以及stride都一样;
- 在时间维度上这样的对称对待未必是最优的(也就是时间维度上的pooling核大小选与空间上的一致是不可取的),因为这取决于帧率和图像大小之间的相对值
- 因此本文在将Inceptin-V1扩充的时候,并不是简单的做对称维度,扩充后的Inception-V1模型结构如下所示:
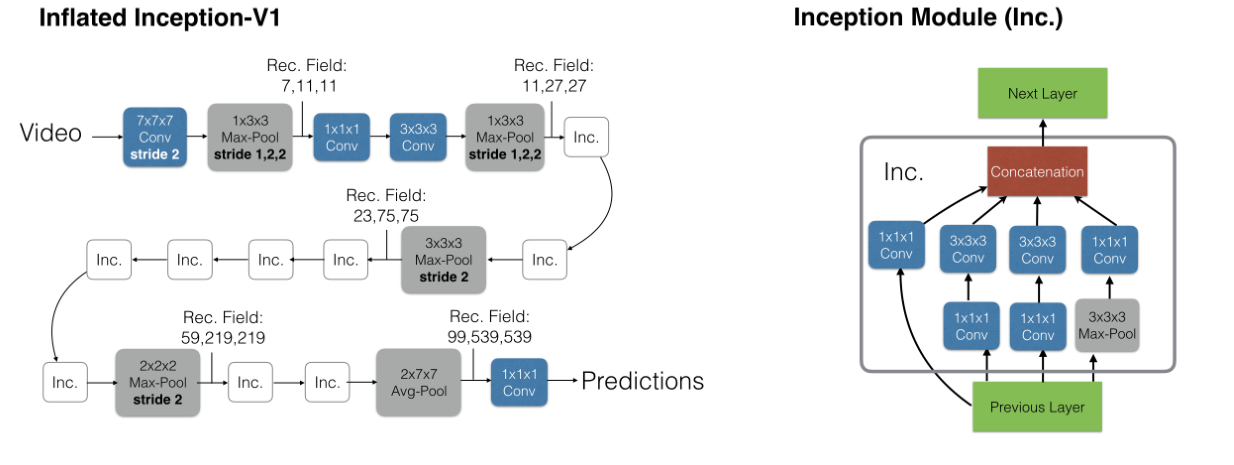
可以看到原来的Inception-v1结构中的convolution以及pool全部都成了3D的;并且结构中大多数kernels和strides保持了对称的特征,例如第一个(7,7)变成(7,7,7),stride也由原来的(2,2)变成了(2,2,2)但是少数做了改变,比如前面的两个max-pool,并不是(2,2,2),而是(1,2,2)这样能够更好的保留时间信息;还有最后的这个avg-pool,并不是(7,7,7)而是(2,7,7)。
最后就是作者给出了一些实验细节,以及实验结果对比,感兴趣的话可以阅读原文。
参考文章:
https://blog.csdn.net/Gavinmiaoc/article/details/81208997
https://www.jianshu.com/p/196ff61d6631
这篇关于《Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset》概述的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





