kinetics专题

I3D视频分类论文梗概及代码解读Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
论文https://arxiv.org/pdf/1705.07750.pdf,from DeepMind ,CVPR2017 代码https://github.com/LossNAN/I3D-Tensorflow 2017年视频分类最好的网络,同时提供了VGG的预训练模型,网络端到端,简单易懂,便于部署及工程化。只是跑一下基本有个Tensorflow,单显卡就能训练和测试,效果还好,一绝。本文
论文阅读【Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset】
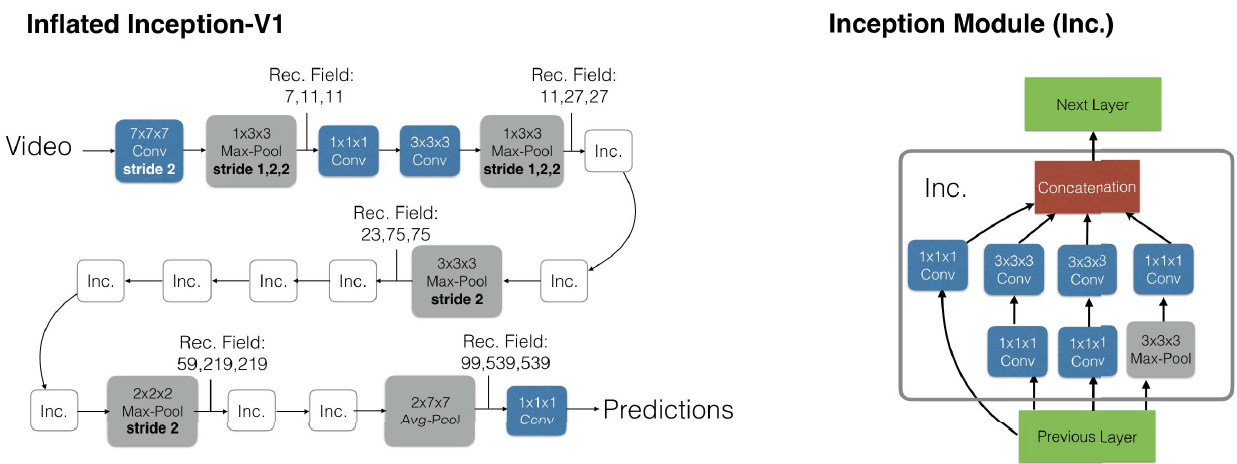
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset 发表:2017 CVPR主要贡献:(1)公开了一个大型的视频数据集,可以用于迁移学习和网络训练。(2)提出了一个新的视频动作分类模型I3D。 之前的模型 a. ConvNet+LSTM 先用CNN提取图像的空间特征,然后顺序输入LSTM中提取时序特征,最后
《Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset》概述
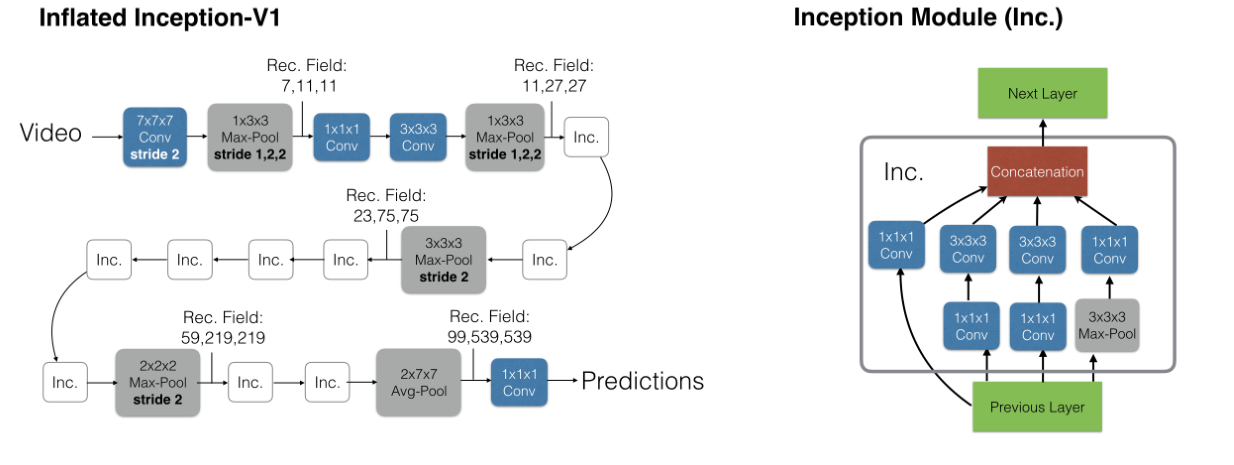
《Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset》概述 引言: 最近阅读了本篇论文,这是一篇发表在CVPR’17年的文章,总体上的贡献在于发布了一个新的数据集以及对3D卷积+Two-Stream方法的结合形成一个新的网络架构(I3D),以下是对本篇论文的概述,如有错误,欢迎留言指正。 一、主要贡献

【论文阅读】Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
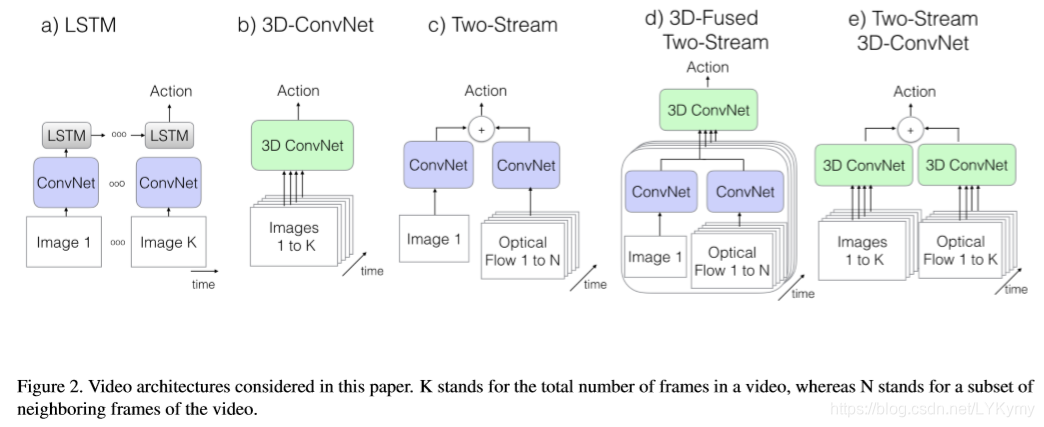
【论文阅读】Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset 这是一篇2017CVPR的论文,我感觉这篇论文最大的贡献就是提出了kinetics数据集,这个数据集与之前的行为识别数据集相比有质的飞跃。同时文章也提出一种将2D卷积网络扩张成3D卷积网络的思想,使3D卷积网络可以收益于2D卷积网络的发展。感觉以后行
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
Abstract 当前动作分类数据集(UCF-101和HMDB-51)中视频的匮乏,使得很难确定好的视频架构,因为大多数方法在现有的小规模基准测试中都获得了类似的性能。本文根据新的Kinetics Human Action Video数据集重新评估了最先进的体系结构。Kinetics的数据量增加了两个数量级,其中包括400个人类动作课程,每个课程超过400个剪辑,它们是从逼真的,具有挑战性的Yo

动作识别阅读笔记(四)《Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset》
论文链接:https://arxiv.org/abs/1705.07750v1 项目代码:https://github.com/deepmind/kinetics-i3d 本想写点记录一下,但这篇博客https://blog.csdn.net/Gavinmiaoc/article/details/81208997 写得非常好,再写也是多余,直接参考便是,一定要看代码,代码才是最精彩的讲解。