本文主要是介绍论文阅读【Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
- 发表:2017 CVPR
- 主要贡献:(1)公开了一个大型的视频数据集,可以用于迁移学习和网络训练。(2)提出了一个新的视频动作分类模型I3D。
之前的模型
a. ConvNet+LSTM
先用CNN提取图像的空间特征,然后顺序输入LSTM中提取时序特征,最后的隐层用于动作分类。
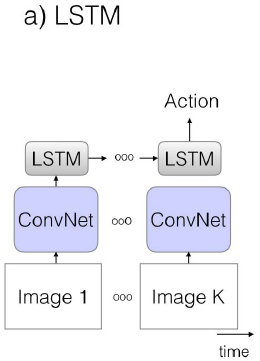
ps:但是效果并不是很好,因此并不普及
b. 3D-ConvNet
将一段视频输入,用3D卷积直接学习视频的的时空特征。将二维的Conv和Pooling都换成3D的
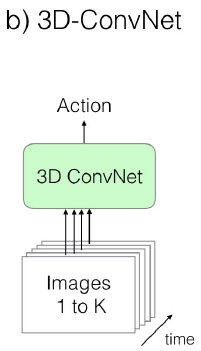
ps:参数量巨大,对于小数据集难以训练,但是效果还行
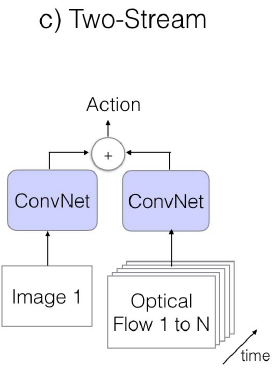
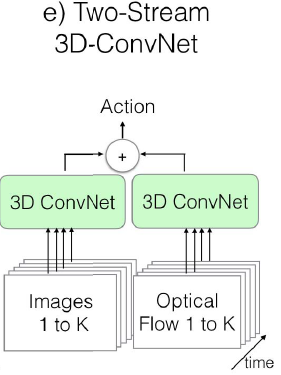
c. Two-Strean
用光流信息(光的流动,即视频中目标的运动轨迹)对时序特征进行建模。左边的卷积网络的输入是一帧或多帧图像,用于学习图像的场景信息;右边的卷积网络输入是视频的光流图,用于学习物体的运动信息
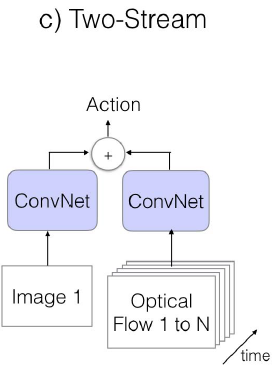
ps:模型较简单,且容易训练,只需要提取视频的光流图然后学习到分类动作的映射即可,使用较为广泛
d. 3D-Fused Two-Stream
b和c的结合版,将c中的加权平均换成了3D ConvNet
总结:在数据充足的条件下,3DConv比2DConv要好很多,但是仍然会有一些东西学习得不好(可能需要额外的信息如光流图进行补充)
模型框架
(1)inflating
将2D的网络“膨胀”成3D,保持架构不变。网络架构统统不变,仅仅是将2D Conv换成3D Conv,2D Pooling换成3D Pooling。这样就可以直接使用之前的2D网络
(2)Bootstrapping
如何将训练好的2D模型的参数对3D模型进行初始化。基本想法是对于同样的输入,两个模型的输出应该是一致的。具体是将一张图像复制n次形成一段视频,2D的参数在时间纬度上复制n次,然后参数除以n(rescaling,用于保证输入和输出一致)
(3)模型细节
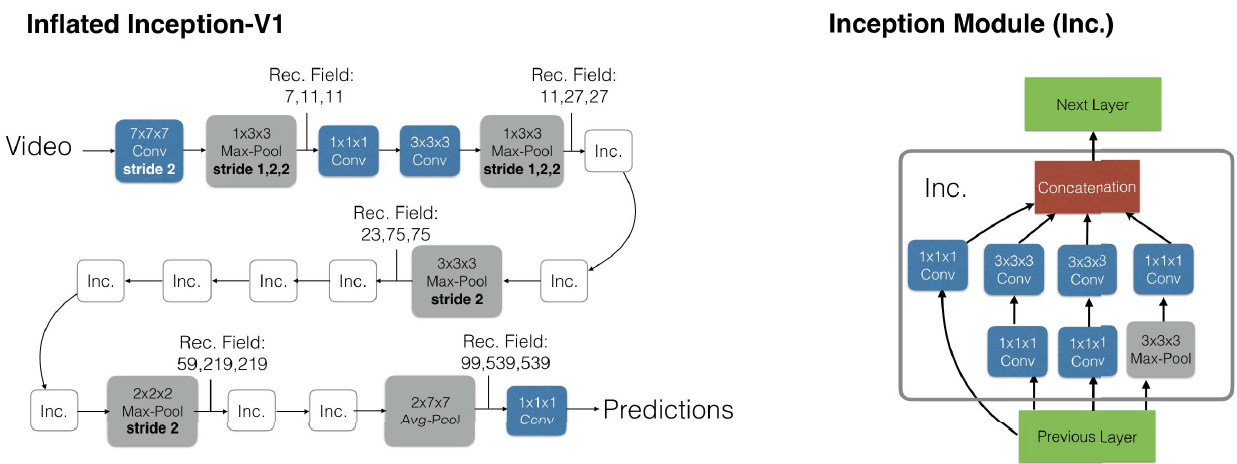
ps:不过现在基本上用的是Resnet
这篇关于论文阅读【Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








