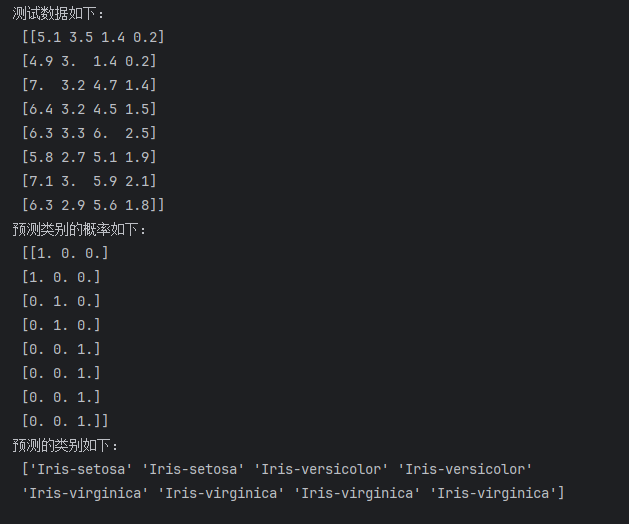
本文主要是介绍ML_3 决策树 Entscheidungsbäume,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这章就屡一下公式以及适用的方法
ID3–非增量过程
entropie 根据标签生成熵
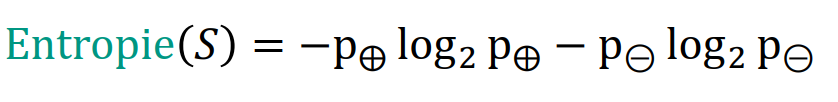
计算每一个属性的熵之和相减
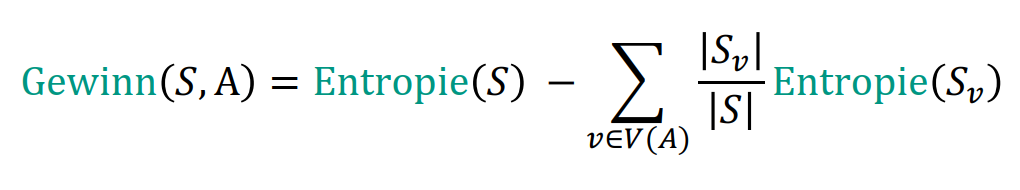
最大的Gewinn对应的属性最优
+Occam’s Razor+尽可能简单的结构,而ID3生成的树很容易很复杂
Overfitting 如果出现噪声,容易Overfitting
C4.5–改变了ID3通过生成的规则(剪枝)
由于Gewinn的方法,使得最优的属性更偏向于数据较少的一项
解决办法就是乘法属性采用比例的方式,通过判断GewinnAnteil在剪枝前后的变化来判断要不要剪枝,如果剪枝后GewinnAnteil增加就剪枝
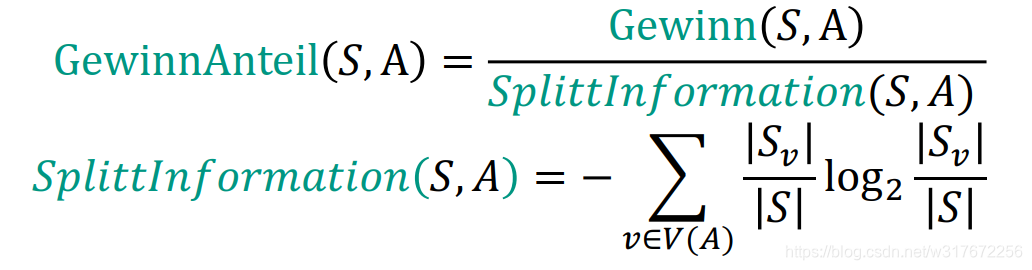
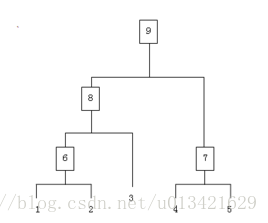
ID5R–增量过程
跟ID3得到的结果其实是一样的,但是区别就是例子不断地在增加所以称之为增量过程
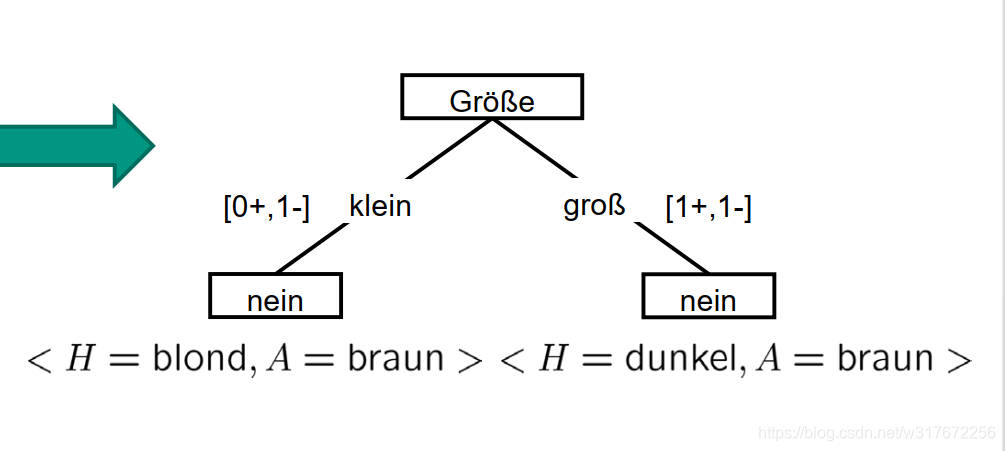
上图是两个例子得到的图,跟ID3的算法一样也是用Entropie判断的
但是再增加离子的时候,发现了不同的最优的属性来分类,所以变化了
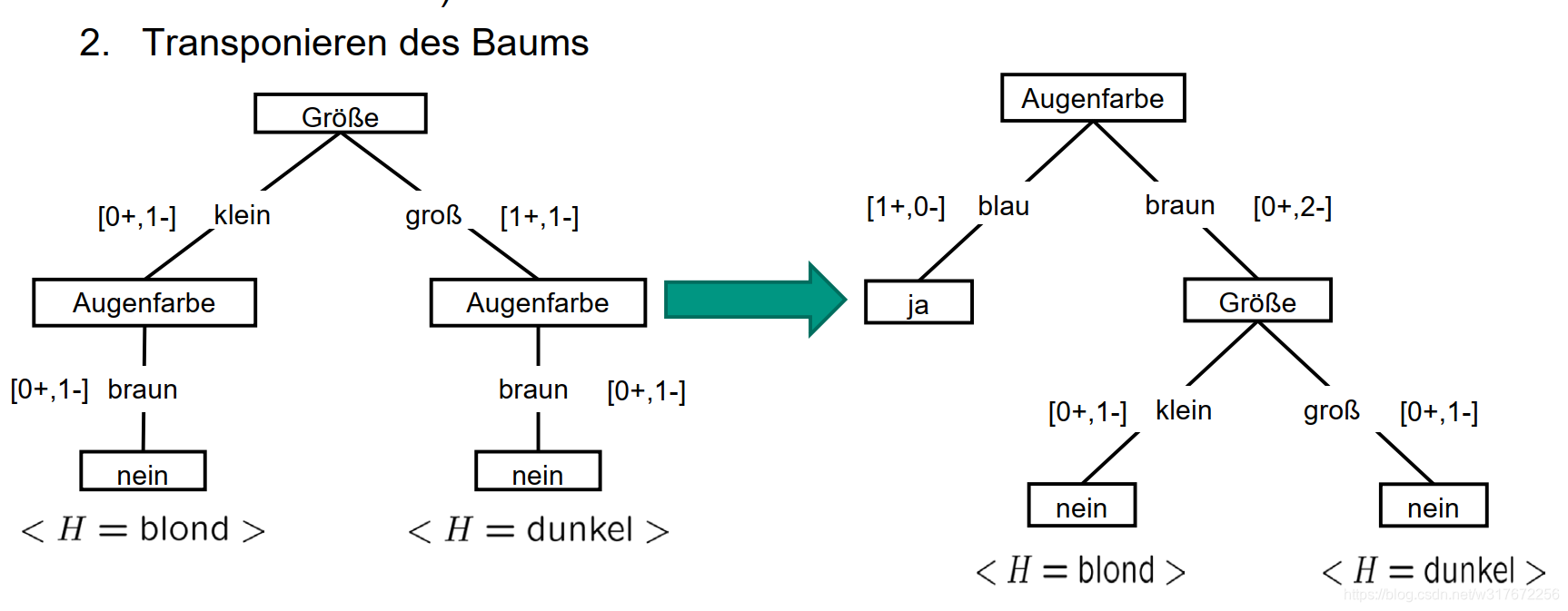
想起了 周志华 机器学习里的决策树后面的小趣事,这个ID5R虽然从名字上看比较像是ID3的改进,但是不是ID3的本人,他的最终版是C4.5就是商业化的最终版,因为他想叫类似ID4,ID5这样的名字的时候被人抢了先机。
random forest
随机选属性组成很多的树,不剪枝
类似于adaboost,但是用的是boosting的方法,随机抽取例子,用树来判断,给树打分,然后就会得到一个有权重的大树。
对于大量数据很有效
这篇关于ML_3 决策树 Entscheidungsbäume的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!