本文主要是介绍论文翻译:OK-Robot: What Really Matters in Integrating Open-Knowledge Models for Robotics,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
OK-Robot: What Really Matters in Integrating Open-Knowledge Models for Robotics
OK-Robot:整合开放知识模型在机器人学中的真正重要性
文章目录
- OK-Robot: What Really Matters in Integrating Open-Knowledge Models for Robotics
- OK-Robot:整合开放知识模型在机器人学中的真正重要性
- I.INTRODUCTION
- I.引言
- II.TECHNICAL COMPONENTS AND METHOD
- II.技术组件和方法
- A.Open-home, open-vocabulary object navigation
- A.开放家庭,开放词汇对象导航
- B.Open-vocabulary grasping in the real world
- B.现实世界中的开放词汇抓取
- C.Dropping heuristic
- C.放置启发式
- D.Deployment in homes
- D.在家中的部署
- III.EXPERIMENTS
- III.实验
- A.List of home experiments
- A.家庭实验列表
- B.Ablations over system components
- B.对系统组件进行消融实验
- C.Impact of clutter, object ambiguity, and affordance
- C.杂乱、对象模糊性和可用性的影响
- D.Understanding the performance of OK-Robot
- D.理解OK-Robot的性能。
- IV.RELATED WORKS
- IV.相关工作
- A.Vision-Language models for robotic navigation
- A.视觉语言模型用于机器人导航
- B.Pretrained robot manipulation models
- B.预训练的机器人操纵模型
- C.Open vocabulary robot systems
- C.开放词汇的机器人系统
- D.LIMITATIONS, OPEN PROBLEMS AND REQUEST FOR RESEARCH
- D.局限性、开放问题和对研究的请求
- A.Live semantic memory and obstacle maps
- A.实时语义记忆和障碍图
- B.Grasp plans instead of proposals
- B.抓取计划而不是建议
- C.改进机器人与用户之间的互动
- C.Improving interactivity between robot and user
- D.Detecting and recovering from failure
- D.检测和从故障中恢复
- E.Robustifying robot hardware
- E.强化机器人硬件
- ACKNOWLEDGMENTS
- 致谢
- APPENDIX A
- 附录 A
- APPENDIX B
- 附录 B
- APPENDIX C
- 附录 C

Fig. 1: OK-Robot is an Open Knowledge robotic system, which integrates a variety of learned models trained on publicly available data, to pick and drop objects in real-world environments. Using Open Knowledge models such as CLIP, Lang-SAM, AnyGrasp, and OWL-ViT, OK-Robot achieves a 58.5% success rate across 10 unseen, cluttered home environments, and 82.4% on cleaner, decluttered environments.
图1:OK-Robot是一种开放知识机器人系统,集成了多种在公开可用数据上训练的学习模型,用于在现实环境中拾取和放置物体。利用诸如CLIP、Lang-SAM、AnyGrasp和OWL-ViT等开放知识模型,OK-Robot在10个未见过的、混乱的家庭环境中实现了58.5%的成功率,在更干净、整理过的环境中达到了82.4%。
Abstract— Remarkable progress has been made in recent years in the fields of vision, language, and robotics. We now have vision models capable of recognizing objects based on language queries, navigation systems that can effectively control mobile systems, and grasping models that can handle a wide range of objects. Despite these advancements, general-purpose applications of robotics still lag behind, even though they rely on these fundamental capabilities of recognition, navigation, and grasping. In this paper, we adopt a systems-first approach to develop a new Open Knowledge-based robotics framework called OK-Robot. By combining Vision-Language Models (VLMs) for object detection, navigation primitives for movement, and grasping primitives for object manipulation, OK-Robot offers a integrated solution for pick-and-drop operations without requiring any training. To evaluate its performance, we run OK-Robot in 10 real-world home environments. The results demonstrate that OK-Robot achieves a 58.5% success rate in open-ended pick-and-drop tasks, representing a new state-of-the-art in Open Vocabulary Mobile Manipulation (OVMM) with nearly 1.8× the performance of prior work. On cleaner, uncluttered environments, OK-Robot’s performance increases to 82%. However, the most important insight gained from OK-Robot is the critical role of nuanced details when combining Open Knowledge systems like VLMs with robotic modules.
摘要—近年来,在视觉、语言和机器人领域取得了显著的进展。我们现在拥有能够根据语言查询识别物体的视觉模型,能够有效控制移动系统的导航系统,以及能够处理各种物体的抓取模型。尽管取得了这些进展,机器人的通用应用仍然滞后,即使它们依赖于识别、导航和抓取等基本能力。在本文中,我们采用了一种以系统为先的方法,开发了一种名为OK-Robot的新型基于开放知识的机器人框架。通过结合用于物体检测的视觉语言模型(VLMs)、用于移动的导航基元以及用于物体操纵的抓取基元,OK-Robot为拾取和放置操作提供了一个集成的解决方案,无需任何训练。为了评估其性能,我们在10个真实的家庭环境中运行了OK-Robot。结果表明,OK-Robot在开放式拾取和放置任务中实现了58.5%的成功率,代表了开放词汇移动操纵(OVMM)的新技术水平,性能几乎是之前工作的1.8倍。在更干净、无杂乱的环境中,OK-Robot的性能提高到82%。然而,从OK-Robot中获得的最重要的见解是,在将VLMs等开放知识系统与机器人模块结合时,具有微妙细节的关键作用。
I.INTRODUCTION
I.引言
Creating a general-purpose robot has been a longstanding dream of the robotics community. With the increase in datadriven approaches and large robot models, impressive progress is being made [1–4]. However, current systems are brittle, closed, and fail when encountering unseen scenarios. Even the largest robotics models can often only be deployed in previously seen environments [5, 6]. The brittleness of these systems is further exacerbated in settings where little robotic data is available, such as in unstructured home environments.
创造一款通用机器人一直是机器人学界的梦想。随着数据驱动方法和大型机器人模型的增加,取得了令人瞩目的进展[1–4]。然而,当前的系统脆弱、封闭,在面对未见过的情景时容易失败。即使是最大的机器人模型,通常也只能在先前见过的环境中部署[5, 6]。这些系统的脆弱性在机器人数据稀缺的环境中进一步恶化,比如在非结构化的家庭环境中。
The poor generalization of robotic systems lies in stark contrast to large vision models [7–10], which show capabilities of semantic understanding [11–13], detection [7, 8], and connecting visual representations to language [9, 10, 14] At the same time, base robotic skills for navigation [15], grasping [16–19], and rearrangement [20, 21] are fairly mature. Hence, it is perplexing that robotic systems that combine modern vision models with robot-specific primitives perform so poorly. To highlight the difficulty of this problem, the recent NeurIPS 2023 challenge for open-vocabulary mobile manipulation (OVMM) [22] registered a success rate of 33% for the winning solution [23].
机器人系统的通用性差异鲜明,与大型视觉模型[7–10]形成对比,后者展示了语义理解[11–13]、检测[7, 8]以及将视觉表征与语言连接的能力[9, 10, 14]。同时,用于导航[15]、抓取[16–19]和重新排列[20, 21]的基本机器人技能相当成熟。因此,令人困惑的是,将现代视觉模型与机器人特定基元相结合的机器人系统表现如此糟糕。为突显这个问题的难度,最近在开放词汇移动操纵(OVMM)方面的NeurIPS 2023挑战[22]中,获胜解决方案的成功率为33% [23]。
So what makes open-vocabulary robotics so hard? Unfortunately, there isn’t a single challenge that makes this problem hard. Instead, inaccuracies in different components compound and together results in overall drop. For example, the quality of open-vocabulary retrievals of objects in homes is dependent on the quality of query strings, navigation targets determined from VLMs may not be reachable to the robot, and the choice of different grasping models may lead to large differences in grasping performance. Hence, making progress on this problem requires a careful and nuanced framework that both integrates VLMs and robotics primitives, while being flexible enough to incorporate newer models as they are developed by the VLM and robotics community.
那么,是什么使得开放词汇机器人学如此困难呢?不幸的是,没有一个单一的挑战使这个问题变得困难。相反,不同组件的不准确性相互叠加,导致整体性能下降。例如,在家庭中检索对象的开放词汇质量取决于查询字符串的质量,从VLMs确定的导航目标可能对机器人不可达,而选择不同的抓取模型可能导致抓取性能的显著差异。因此,在解决这个问题上取得进展需要一个谨慎而微妙的框架,既能整合VLMs和机器人基元,同时又足够灵活,能够纳入VLM和机器人社区开发的新模型。
We present OK-Robot, an Open Knowledge Robot that integrates state-of-the-art VLMs with powerful robotics primitives for navigation and grasping to enable pick-and-drop. Here, Open Knowledge refers to learned models trained on large, publicly available datasets. When placed in a new home environment, OK-Robot is seeded with a scan taken from an iPhone. Given this scan, dense vision-language representations are computed using LangSam [24] and CLIP [9] and stored in a semantic memory. Then, given a language-query for an object that has to be picked, language representations of the query is matched with semantic memory. After this, navigation and picking primitives are applied sequentially to move to the desired object and pick it up. A similar process can be carried out for dropping the object.
我们介绍OK-Robot,一款集成了最先进的VLMs和强大的机器人基元以实现导航和抓取的开放知识机器人。在这里,开放知识指的是在大型公开可用数据集上训练的学习模型。当OK-Robot放置在新的家庭环境中时,它以从iPhone拍摄的扫描作为种子。给定此扫描,使用LangSam [24]和CLIP [9]计算密集的视觉语言表示,并存储在语义内存中。然后,针对需要拾取的对象的语言查询,将查询的语言表示与语义内存匹配。在此之后,导航和拾取基元按顺序应用于移动到所需对象并将其拾取。类似的过程可以用于放置对象。
To study OK-Robot, we tested it in 10 real world home environments. Through our experiments, we found that on a never seen, natural home environment, a zero-shot deployment of our system achieves 58.5% success on average. However, this success rate is largely dependant on the “naturalness” of the environment, as we show that with improving the queries, decluttering the space, and excluding objects that are clearly adversarial (too large, too translucent, too slippery), this success rate reaches about 82.4%. Overall, through our experiments, we make the following observations:
为了研究OK-Robot,我们在10个真实的家庭环境中对其进行了测试。通过我们的实验证明,在一个从未见过的自然家庭环境中,我们系统的零次部署平均成功率为58.5%。然而,这一成功率在很大程度上取决于环境的“自然性”,因为我们发现通过改善查询、清理空间并排除明显对抗性的物体(太大、太透明、太滑)可以将成功率提高到约82.4%。总体而言,通过我们的实验,我们得出以下观察结果:
Pre-trained VLMs are highly effective for openvocabulary navigation: Current open-vocabulary visionlanguage models such as CLIP [9] or OWL-ViT [8] offer strong performance in identifing arbitrary objects in the real world, and enable navigating to them in a zero-shot manner (see Section II-A.)
预训练的VLMs对于开放词汇导航非常有效: 目前的开放词汇视觉语言模型,如CLIP [9]或OWL-ViT [8],在识别现实世界中的任意对象方面表现出色,并能够以零次部署方式导航到它们(见第II-A节)。
• Pre-trained grasping models can be directly applied to mobile manipulation: Similar to VLMs, special purpose robot models pre-trained on large amounts of data can be applied out of the box to approach open-vocabulary grasping in homes. These robot models do not require any additional training or fine-tuning (see Section II-B.)
预训练的抓取模型可以直接应用于移动操纵: 与VLMs类似,预先在大量数据上训练的特定用途的机器人模型可以直接应用于家庭中的开放词汇抓取。这些机器人模型不需要任何额外的训练或微调(见第II-B节)。
• How components are combined is crucial: Given the pretrained models, we find that they can be combined with no training using a simple state-machine model. We also find that using heuristics to counteract the robot’s physical limitations can lead to a better success rate in the real world (see Section II-D.)
如何组合组件至关重要: 在给定预训练模型的情况下,我们发现它们可以使用简单的状态机模型进行无训练组合。我们还发现使用启发式方法来抵消机器人的物理限制可以在现实世界中提高成功率(见第II-D节)。
• Several challenges still remain: While, given the immense challenge of operating zero-shot in arbitrary homes, OK-Robot improves upon prior work, by analyzing the failure modes we find that there are significant improvements that can be made on the VLMs, robot models, and robot morphology, that will directly increase performance of openknowledge manipulation agents (see Section III-D).
仍然存在一些挑战: 尽管考虑到在任意家庭中零次操作的巨大挑战,OK-Robot在改进先前的工作方面取得了进展,通过分析失败模式,我们发现在VLMs、机器人模型和机器人形态学方面仍然存在显著的改进空间,这将直接提高开放知识操纵代理的性能(见第III-D节)。
To encourage and support future work in open-knowledge robotics, we will share the code and modules for OK-Robot, and are committed to supporting reproduction of our results. More information along with robot videos are available on our project website: https://ok-robot.github.io.
为了鼓励和支持未来的开放知识机器人研究,我们将分享OK-Robot的代码和模块,并致力于支持我们结果的复现。有关更多信息以及机器人视频,请访问我们的项目网站:https://ok-robot.github.io。
II.TECHNICAL COMPONENTS AND METHOD
II.技术组件和方法
Our method, on a high level, solves the problem described by the query: “Pick up A (from B) and drop it on/in C”, where A is an object and B and C are places in a real-world environment such as homes. The system we introduce is a combination of three primary subsystems combined on a Hello Robot: Stretch. Namely, these are the open-vocabulary object navigation module, the open-vocabulary RGB-D grasping module, and the dropping heuristic. In this section, we describe each of these components in more details.
在高层次上,我们的方法解决了由查询描述的问题:“拾取A(从B)并将其放在/放入C”,其中A是一个对象,B和C是现实世界环境(如家庭)中的位置。我们介绍的系统是基于Hello Robot: Stretch上的三个主要子系统的组合。具体而言,这些是开放词汇对象导航模块、开放词汇RGB-D抓取模块和放置启发式。在本节中,我们详细描述了每个组件。
A.Open-home, open-vocabulary object navigation
A.开放家庭,开放词汇对象导航
The first component of our method is an open-home, openvocabulary object navigation model that we use to map a home and subsequently navigate to any object of interest designated by a natural language query.
我们方法的第一个组件是一个开放家庭、开放词汇的对象导航模型,我们用它来映射一个家庭,随后可以导航到任何由自然语言查询指定的感兴趣的对象。
Scanning the home: For open vocabulary object navigation, we follow the approach from CLIP-Fields [27] and assume a pre-mapping phase where the home is “scanned” manually using an iPhone. This manual scan simply consists of taking a video of the home using the Record3D app on the iPhone, which results in a sequence of posed RGB-D images.
扫描家庭:对于开放词汇对象导航,我们采用了来自CLIP-Fields [27]的方法,并假定有一个预映射阶段,其中使用iPhone手动“扫描”家庭。这个手动扫描简单地包括使用iPhone上的Record3D应用程序拍摄家庭的视频,这导致一系列带有姿势的RGB-D图像。
Alternatively, this could be done automatically using frontierbased exploration [15, 25, 26], but for speed and simplicity we prefer the manual approach [26, 27]. We take this approach since the frontier-based approaches tend to be slow and cumbering, especially for a novel space, while our “scan” take less than one minute for each room. Once collected, the RGB-D images, along with the camera pose and positions, are exported to our library for map-building.
或者,这可以使用基于前沿的探索 [15, 25, 26]自动完成,但出于速度和简单起见,我们更喜欢手动方法 [26, 27]。我们采取这种方法是因为基于前沿的方法往往很慢且繁琐,特别是对于新颖的空间,而我们的“扫描”对每个房间不到一分钟。一旦收集到RGB-D图像以及相机的姿势和位置,它们将被导出到我们的库进行地图构建。
To ensure our semantic memory contains both the objects of interest as well as the navigable surface and any obstacles, the recording must capture the floor surface alongside the objects and receptacles in the environment.
为了确保我们的语义内存既包含感兴趣的对象,又包含可导航的表面和任何障碍物,录制必须捕捉环境中的地面表面以及对象和容器。
Detecting objects: On each frame of the scan, we run an openvocabulary object detector. Unlike previous works which used Detic [7], we chose OWL-ViT [8] as the object detector since we found it to perform better in preliminary queries. We apply the detector on every frame, and extract each of the object bounding box, CLIP-embedding, detector confidence, and pass them onto the object memory module of our navigation module.
检测对象:在扫描的每一帧上,我们运行一个开放词汇的对象检测器。与以前使用Detic [7]的工作不同,我们选择了OWL-ViT [8]作为对象检测器,因为我们发现它在初步查询中的性能更好。我们在每一帧上应用检测器,并提取每个对象的边界框、CLIP嵌入、检测器置信度,并将它们传递给我们导航模块的对象内存模块。
Building on top of previous work [27], we further refine the bounding boxes into object masks with Segment Anything (SAM) [28]. Note that, in many cases, open-vocabulary object detectors still require a set of natural language object queries that they try to detect. We supply a large set of such object queries, derived from the original Scannet200 labels [29], such that the detector captures most common objects in the scene.
在之前的工作[27]的基础上,我们使用Segment Anything (SAM) [28]将边界框进一步细化为对象掩模。请注意,在许多情况下,开放词汇对象检测器仍然需要一组它们尝试检测的自然语言对象查询。我们提供了一组大量的这样的对象查询,从原始Scannet200标签 [29]派生而来,以便检测器捕捉场景中的大多数常见对象。
Object-centric semantic memory: We use an object-centric memory similar to Clip-Fields [27] and OVMM [25] that we call the VoxelMap. The object masks are back-projected in real-world coordinates using the depth image and the pose collected by the camera, giving us a point cloud where each point has an associated semantic vector coming from CLIP. Then, we voxelize the point cloud to a 5 cm resolution and for each voxel, calculate the detector-confidence weighted average for the CLIP embeddings that belong to that voxel. This voxel map builds the base of our object memory module. Note that the representation created this way remains static after the first scan, and cannot be adapted during the robot’s operation. This inability to dynamically create a map is discussed in our limitations section (Section V).
以对象为中心的语义内存:我们使用一种类似于Clip-Fields [27]和OVMM [25]的以对象为中心的内存,我们称之为VoxelMap。对象掩模在使用由相机收集的深度图像和姿势的真实世界坐标中进行反投影,给我们一个点云,其中每个点都有一个与CLIP相关的语义向量。然后,我们将点云体素化为5厘米分辨率,对于每个体素,计算属于该体素的CLIP嵌入的检测器置信度加权平均值。这个体素图构建了我们的对象内存模块的基础。请注意,以这种方式创建的表示在第一次扫描后保持静态,并且在机器人操作期间无法调整。我们在我们的限制部分(第V节)讨论了动态创建地图的无能力性。
Querying the memory module: Our semantic object memory gives us a static world representation represented as possibly non-empty voxels in the world, and a semantic CLIP vector associated with each voxel. Given a language query, we convert it to a semantic vector using the CLIP language encoder. Then, we find the top voxel where the dot product between the encoded vector and the voxel’s semantic representation is maximized. Since each voxel is associated with a real location in the home, this lets us find the location where a queried object is most likely to be found, similar to Figure 2(a).
查询内存模块:我们的语义对象内存为我们提供了一个表示为可能非空体素的静态世界表示,以及与每个体素相关联的语义CLIP向量。给定一个语言查询,我们使用CLIP语言编码器将其转换为语义向量。然后,我们找到点积在编码向量和体素的语义表示之间取得最大值的顶部体素。由于每个体素都与家庭中的一个实际位置相关联,这使我们能够找到查询对象最有可能被发现的位置,类似于图2(a)。
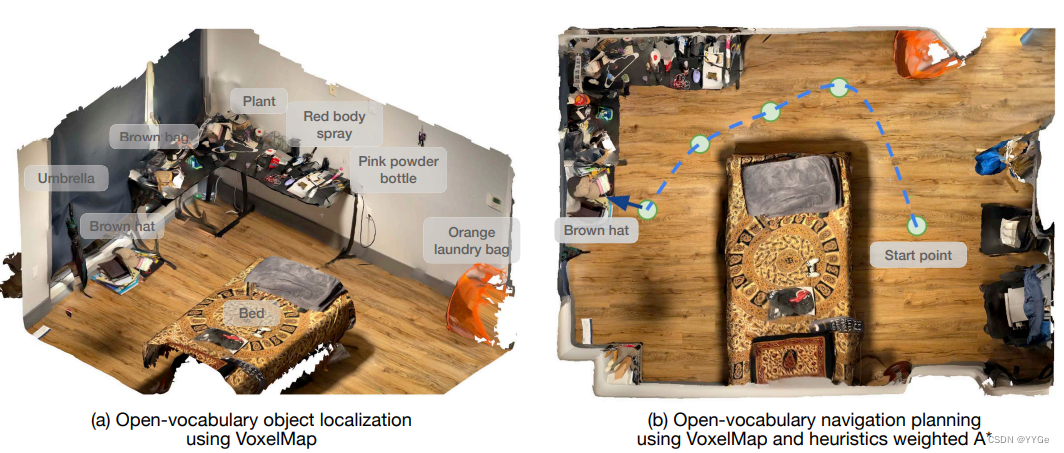
Fig. 2: Open-vocabulary, open knowledge object localization and navigation in the real-world. We use the VoxelMap [25] for localizing objects with natural language queries, and use an A* algorithm similar to USANet [26] for path planning.
图2:在现实世界中进行开放词汇、开放知识对象定位和导航。我们使用VoxelMap [25]通过自然语言查询定位对象,并使用类似于USANet [26]的A*算法进行路径规划。
When necessary, we implement “A on B” as “A near B”. We do so by selecting top-10 points for query A and top-50 points for query B. Then, we calculate the 10×50 pairwise euclidean distances and pick the A-point associated with the shortest (A, B) distance. Note that, during the object navigation phase, we use this query only to navigate to the object approximately, and not for manipulation.
在必要时,我们将“A on B”实现为“A near B”。我们通过为查询A选择前10个点和查询B选择前50个点来实现这一点。然后,我们计算10×50的配对欧几里得距离,并选择与最短(A,B)距离相关联的A点。请注意,在对象导航阶段,我们仅使用此查询大致导航到对象,并不用于操作。
This approach gives us two advantages: our map can be as lower resolution than those in prior work [26, 27, 30], and we can deal with small movements in object’s location after building the map.
这种方法给我们带来了两个优势:我们的地图可以比以前的工作[26, 27, 30]中的地图分辨率更低,而且我们可以处理构建地图后对象位置的小幅移动。
Navigating to objects in the real world: Once our navigation model gives us a 3D location coordinate in the real world, we use that as a navigation target for our robot to initialize our manipulation phase. In previous works [15, 27, 31], the navigation objective was to go and look at an object, which can be done while staying at a safe distance from the object itself. In contrast, our navigation module must place the robot at an arms length so that the robot can manipulate the target object afterwards. Thus, our navigation method has to balance the following objectives:
在现实世界中导航到对象:一旦我们的导航模型为我们提供了现实世界中的3D位置坐标,我们将其用作我们机器人初始化操作阶段的导航目标。在先前的工作中[15, 27, 31],导航的目标是去看一个对象,这可以在与对象本身保持安全距离的同时完成。相反,我们的导航模块必须将机器人放置在臂长之处,以便机器人随后可以操作目标对象。因此,我们的导航方法必须平衡以下目标:
1)the robot needs to be close enough to the object to manipulate it,
2)the robot needs some space to move its gripper, so there needs to be a small but non-negligible space between the robot and the objectm and
3) the robot needs to avoid collision during manipulation, and thus needs to keep its distance from all obstacles.
机器人需要足够接近对象以进行操作,
机器人需要一些空间来移动其夹爪,因此机器人和对象之间需要有一些小但非可忽略的空间,
机器人在操作过程中需要避免碰撞,因此需要与所有障碍物保持距离。
We use three different navigation score functions, each associated with one of our previous concerns, and evaluate them on each point of the space to find the best position to place the robot.
我们使用三个不同的导航评分函数,每个与我们先前关注的一个问题相关联,并在空间的每一点上评估它们以找到放置机器人的最佳位置。
Let a random point be ⃗x, the closest obstacle point as ⃗xobs, and the target object as ⃗xo. Then, we can define the following three functions s1, s2, s3 to capture our three criterion. Then,their weighted sum s to find the ideal navigation point x⃗∗ in our space that minimizes s(⃗x), and the direction is towards the vector from x⃗∗ to ⃗xo.
假设一个随机点-x,最近的障碍点-xobs,目标对象-xo。然后,我们可以定义以下三个函数s1,s2,s3来捕捉我们的三个标准。然后,它们的加权和s用于在我们的空间中找到最小化s(-x)的理想导航点x-,并且方向指向从x-xo的向量。
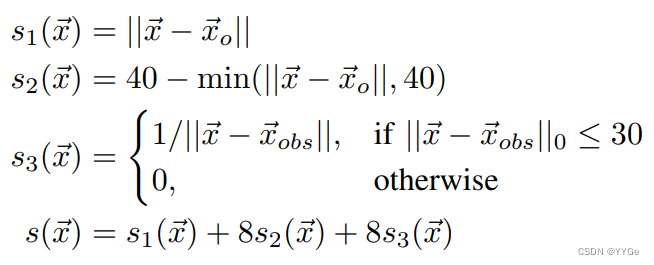
To navigate to this target point safely from any other point in space, we follow a similar approach to [26, 32] by building an obstacle map from our previously captured posed RGB-D images. We build a 2D, 10cm×10cm grid of obstacles over which we navigate using the A* algorithm. To convert our voxel map to an obstacle map, we first set a floor and ceiling height. Presence of occupied voxels in between them implies the grid cell is occupied, while presence of neither ceiling nor floor voxels mean that the grid cell is unexplored. We mark both occupied or unexplored cells as not navigable. Around each occupied point, we mark any point within a 20 cm radius as also non-navigable to account for the robot’s radius and a turn radius. In our A* algorithm, we use the s3 function as a heuristic on the node costs to navigate further away from any obstacles, which makes our generated paths similar to ideal Voronoi paths [33] in our experiments.
为了从空间中的任何其他点安全导航到此目标点,我们采用与[26, 32]类似的方法,通过使用先前捕获的带姿势的RGB-D图像构建障碍图。我们建立一个2D的、10厘米×10厘米的障碍网格,我们使用A算法在其上导航。为了将我们的体素地图转换为障碍地图,我们首先设置了地板和天花板的高度。它们之间的占用体素的存在意味着该网格单元被占用,而天花板和地板体素的不存在意味着该网格单元未被探索。我们标记占用或未探索的单元都为不可导航。在每个占用点周围,我们标记在20厘米半径内的任何点也为不可导航,以考虑机器人的半径和转弯半径。在我们的A算法中,我们使用s3函数作为启发式,将其用于节点成本,以使其远离任何障碍物,这使得我们生成的路径在我们的实验中类似于理想的Voronoi路径 [33]。
B.Open-vocabulary grasping in the real world
B.现实世界中的开放词汇抓取
Unlike open-vocabulary navigation, for grasping, our method needs to physically interact with arbitrary objects in the real world, which makes this part significantly more difficult. As a result, we opt for using a pre-trained grasping model to generate grasp poses in the real world, and filter that with language-conditioning using a modern VLM.
与开放词汇导航不同,对于抓取,我们的方法需要在现实世界中与任意对象进行物理交互,这使得这一部分显着更加困难。因此,我们选择使用一个预先训练的抓取模型,在现实世界中生成抓取姿势,并使用现代VLM进行语言条件过滤。
Grasp perception: Once the robot reaches the object using the navigation method outlined in Section II-A, we use a pre-trained grasping model or heuristic to generate a grasp for the robot. We point the robot’s RGB-D head camera towards the object’s location in space, as given to us by our semantic memory module, and capture an RGB-D image from it (Figure 3, column 1). We backproject and convert the depth image to a pointcloud as necessary. Then, we pass this information to our grasp generation module. The grasp generation module that we use in our work is AnyGrasp [19], which generates collision free grasps with a parallel jaw gripper in a scene given a single RGB image and a pointcloud.
抓取感知:一旦机器人使用第II-A节中概述的导航方法到达对象,我们使用预训练的抓取模型或启发式来为机器人生成抓取。我们将机器人的RGB-D头部相机对准空间中的对象位置,由我们的语义内存模块给出,并从中捕获一个RGB-D图像(图3,列1)。我们按需反投影并将深度图像转换为点云。然后,我们将这些信息传递给我们的抓取生成模块。我们在工作中使用的抓取生成模块是AnyGrasp [19],它在给定单个RGB图像和点云的情况下生成具有平行夹爪的场景中的无碰撞抓取。
AnyGrasp provides us with possible grasps in the scene (Figure 3 column 2) with grasp point, width, height, depth, and a “graspness score”, which indicates uncalibrated model confidence in each grasp. However, such modules generally generate all possible grasps in a scene, which we need to filter using the language query.
AnyGrasp为我们提供了场景中可能的抓取(图3列2),包括抓取点、宽度、高度、深度和“抓取得分”,该得分表示每个抓取中未校准模型的置信度。然而,这样的模块通常会生成场景中的所有可能抓取,我们需要使用语言查询进行过滤。
Filtering grasps using language queries: Once we get all proposed grasps from AnyGrasp, we filter the grasps using LangSam [24]. We use LangSam [24] to segment the captured image and get the desired object’s mask with the language query (Figure 3 column 3). Then, we project all the proposed grasp points onto the image and find the grasps that fall into the object mask (Figure 3 column 4).
使用语言查询过滤抓取:一旦我们从AnyGrasp获取所有建议的抓取,我们使用LangSam [24]过滤抓取。我们使用LangSam [24]对捕获的图像进行分割,并使用语言查询获取所需对象的掩模(图3列3)。然后,我们将所有建议的抓取点投影到图像上,并找到落入对象掩模的抓取(图3列4)。
We pick the best grasp using a heuristic, where if the grasp score is S and the angle between the grasp normal and floor normal is θ, then the new heuristic score is S − ( θ 4 /10). This heuristic prioritizes grasps with the highest graspness score but also a horizontally flat proposed grasp. We prefer horizontal grasps because they are robust to small calibration errors on the robot, while vertical grasps need to be quite point-accurate to be successful. Being robust to hand-eye calibration errors is a desired property as we transport the robot to different homes over the course of our experiments.
我们使用启发式选择最佳抓取,其中如果抓取得分为S,抓取法线与地板法线之间的角度为θ,则新的启发式得分为S − ( θ 4 /10)。此启发式优先考虑具有最高抓取得分的抓取,但也具有水平平坦提议抓取。我们更喜欢水平抓取,因为它们对机器人上的小校准错误具有鲁棒性,而垂直抓取需要相当点精确才能成功。在实验过程中,由于我们将机器人运送到不同的家庭,对手眼校准错误具有鲁棒性是一种理想的特性。

Fig. 3: Open-vocabulary grasping in the real world. From left to right, we show the (a) robot POV image, (b) all suggested grasps from AnyGrasp [19], © object mask given label from LangSam [24], (d) grasp points filtered by the mask, and (e) grasp chosen for execution.
图3:现实世界中的开放词汇抓取。从左到右,我们展示了(a)机器人的POV图像,(b)AnyGrasp [19]提出的所有建议抓取,(c)由LangSam [24]标签给出的对象掩模,(d)通过掩模过滤的抓取点,以及(e)用于执行的抓取。
Grasp execution: Once we identify the best grasp (Figure 3 column 5), we use a simple pre-grasp approach [34] to grasp our intended object. Let’s assume that −→p is the grasp point and −→a is the approach vector given by our grasping model. Then, our robot gripper follows the following trajectory:
抓取执行:一旦我们确定了最佳抓取(图3列5),我们使用简单的预抓取方法[34]来抓取我们预定的对象。假设−→p是抓取点,−→a是由我们的抓取模型给出的进近向量。然后,我们的机器人夹爪遵循以下轨迹:
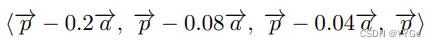
Put simply, our method approaches the object from a pre-grasp position in a line with progressively smaller motions. Moving slower as we approach the object is important since the robot can knock over light objects otherwise. Once we reach the predicted grasp point, we close the gripper in a close loop fashion to make sure we can get a solid grip on the object without crushing it. Finally, after grasping the object, we lift up the robot arm, retract it fully, and rotate the wrist to have the object tucked over the body. This behavior maintains the robot footprint while ensuring the object is held securely by the robot and doesn’t fall while navigating to the drop location.
简而言之,我们的方法从预抓取位置以逐渐减小的运动直线接近对象。在接近对象时减缓移动是重要的,因为否则机器人可能会打翻轻物体。一旦到达预测的抓取点,我们以闭环方式关闭夹爪,以确保我们可以牢固地抓住对象而不会压碎它。最后,在抓取对象后,我们抬起机器人手臂,将其完全缩回,并旋转手腕,使对象收紧在身体上。这种行为保持了机器人的足迹,同时确保对象在导航到放置位置时被机器人牢固地握住,不会掉落。
C.Dropping heuristic
C.放置启发式
After picking up an object, we find and navigatte to the location to drop it using the same methods as described in Section II-A. Unlike in HomeRobot’s baseline implementation [25], which assumes that the drop-off location is a flat surface, we extend our heuristic to also cover concave objects such as sink, bins, boxes, and bags. First, we segment the point cloud P captured by the robot’s head camera using LangSam [24] similar to Section II-B using the drop language query. Then, we align that segmented point cloud such that X-axis is aligned with the way the robot is facing, Y-axis is to its left and right, and the Z-axis of the point cloud is aligned with the floor normal. We call this aligned pointcloud Pa. Finally, we normalize the point cloud so that the robot’s Xand Y- coordinate is (0, 0), and the floor plane is at z = 0. On the aligned, segmented point cloud, we consider the X- and Y-coordinates for each point, and find the respective medians on each axis that we call xm and ym. Finally, we find a drop height using zmax = 0.2 + max{z | (x, y, z) ∈ Pa; 0 ≤ x ≤ xm; |y − ym| < 0.1} on the segmented, aligned pointcloud. We add a small buffer of 0.2 to the height to avoid collisions between the robot and the drop location. Finally, we move the robot gripper above the drop point, and open the gripper to drop the object. While this heuristic sometimes fails to place an object on a cluttered surface, in our experiments it performs well on average.
在拾取对象后,我们使用与第II-A节中描述的相同方法找到并导航到放置对象的位置。与HomeRobot的基准实现[25]不同,该实现假设卸货位置是一个平坦的表面,我们将我们的启发式扩展到还包括凹陷对象,如水槽、垃圾桶、箱子和袋子。首先,我们使用LangSam [24]通过使用放置语言查询对机器人头部相机捕获的点云P进行分割,类似于第II-B节。然后,我们对齐分割后的点云,使得X轴与机器人的朝向对齐,Y轴在其左右,点云的Z轴与地板法线对齐。我们将这个对齐的点云称为Pa。最后,我们规范化点云,使得机器人的X和Y坐标为(0, 0),地板平面在z = 0。在对齐的分割点云上,我们考虑每个点的X和Y坐标,并找到在每个轴上的相应中值,我们称为xm和ym。最后,我们使用zmax = 0.2 + max{z | (x, y, z) ∈ Pa; 0 ≤ x ≤ xm; |y − ym| < 0.1}在分割的对齐点云上找到一个放置高度。我们在高度上添加一个小缓冲区0.2,以避免机器人和放置位置之间的碰撞。最后,我们将机器人的夹爪移动到放置点上方,并打开夹爪以放置物体。虽然这个启发式有时在将物体放置在杂乱的表面上失败,但在我们的实验中,它的平均表现不错。
D.Deployment in homes
D.在家中的部署
Once we have our navigation, pick, and drop primitive in place, we combine them directly to create our robot method that can be applied in any novel home directly. For a new home environment, we can “scan” the room in under a minute. Then, it takes less than five minutes to process that into our VoxelMap. For our ablations, it takes about 50 minutes to train the necessary implicit semantic fields/SDF models such as CLIP-Fields or USA-Net if we are using them. Once that is done, the robot can be immediately placed at the base and start operating. From arriving into a completely novel environment to start operating autonomously in it, our system takes under 10 minutes on average to complete the first pick-and-drop task
一旦我们有了导航、拾取和放置的基本操作,我们直接将它们组合起来,创建我们的机器人方法,可以直接应用于任何新颖的家庭。对于新的家庭环境,我们可以在不到一分钟的时间内对房间进行“扫描”。然后,将其处理为我们的VoxelMap只需要不到五分钟的时间。对于我们的消融实验,如果我们使用了CLIP-Fields或USA-Net等必要的隐式语义场/SDF模型,训练需要大约50分钟。完成这些步骤后,机器人可以立即放置在基座上并开始运行。从进入一个全新的环境到开始在其中自主运行,我们的系统平均只需要不到10分钟就能完成第一次拾取和放置任务。
State machine model: The transition between different modules happens automatically, in a predefined fashion, once a user specifies the object to pick and where to drop it. Since we do not implement error detection or correction, our state machine model is a simple linear chain of steps leading from navigating to object, to grasping, to navigating to goal, and to dropping the object at the goal to finish the task.
状态机模型:不同模块之间的转换自动发生,按照预定的方式进行,一旦用户指定要拾取的对象和放置的位置。由于我们没有实现错误检测或校正,我们的状态机模型是一个简单的线性步骤链,从导航到对象,到抓取,到导航到目标,最终到将对象放置在目标处完成任务。
Protocol for home experiments: To run our experiment in a novel home, we first move the robot to a previously unobserved room. There, we record the scene and create our VoxelMap. Concurrently, we arbitrarily pick between 10-20 objects in each scene that can fit in the robot gripper. These are objects “found” in the scene, and are not ones selected beforehand. We come up with a language query for each chosen object using GPT-4V [35] to keep the queries consistent and free of experimenter bias. The effect of different queries for the same object on OK-Robot is discussed in Section III-D. Then, we query our navigation module to filter out all the navigation failures; i.e. objects whose location could not be found by our semantic memory module. Then, we execute pick-and-drop on remaining objects sequentially, without resets between trials.
家庭实验的协议:为了在新颖的家中运行我们的实验,我们首先将机器人移动到以前未观察到的房间。在那里,我们记录场景并创建我们的VoxelMap。与此同时,我们在每个场景中任意选择10-20个可以适应机器人夹爪的对象。这些对象是在场景中“发现”的,而不是事先选择的。我们使用GPT-4V [35]为每个选择的对象提出语言查询,以保持查询的一致性并摆脱实验者的偏见。我们然后查询我们的导航模块,以过滤掉所有导航失败的对象,即我们的语义内存模块无法找到其位置的对象。然后,我们按顺序对剩余对象执行拾取和放置,试验之间不进行重置。
III.EXPERIMENTS
III.实验
We evaluate our method in two set of experiments. On the first set of experiments, we evaluate between multiple alternatives for each of our navigation and manipulation modules. These experiments give us insights about which modules to use and evaluate in a home environment as a part of our method. On the next set of experiments, we took our robots to 10 homes and ran 171 pick-and-drop experiments to empirically evaluate how our method performs in completely novel homes, and to understand the failure modes of our system.
我们在两组实验中评估了我们的方法。在第一组实验中,我们在每个导航和操作模块中评估了多个替代方案。这些实验为我们提供了关于作为我们方法一部分在家庭环境中使用哪些模块以及如何评估它们的见解。在下一组实验中,我们将我们的机器人带到了10个家庭,并进行了171次拾取和放置实验,以经验性地评估我们的方法在完全新颖的家庭中的性能,并了解我们系统的失败模式。
Through these experiments, we look to answer a series of questions regarding the capabilities and limits of current Open Knowledge robotic systems, as embodied by OK-Robot. Namely, we ask the following:
通过这些实验,我们试图回答关于当前开放知识机器人系统(由OK-Robot体现)的能力和限制的一系列问题。具体来说,我们提出以下问题:
1)How well can such a system tackle the challenge of pick and drop in arbitrary homes?
2) How well do alternate primitives for navigation and grasping compare to the recipe presented here for building an Open Knowledge robotic system?
3) How well can our current systems handle unique challenges that make homes particularly difficult, such as clutter, ambiguity, and affordance challenges?
4)What are the failure modes of such a system and its individual components in real home environments?
1)这样的系统在处理任意家庭中的拾取和放置挑战时表现如何?
2)与构建开放知识机器人系统的此处介绍的方法相比,用于导航和抓取的替代基元表现如何?
3)我们当前的系统在处理使家庭特别困难的独特挑战方面,如杂乱、歧义和可供性挑战方面,表现如何?
4)在真实家庭环境中,这样的系统及其各个组件的故障模式是什么?
A.List of home experiments
A.家庭实验列表
Over the 10 home environment, OK-Robot achieved a 58.5% success rates in completing full pick-and-drops. Notably, this is a zero-shot algorithm, and the success rate is over novel objects sourced from each home. As a result, each of the success and the failure of the robot tells us something interesting about applying open-knowledge models in robotics, which is what we analyze over the next sections.
在10个家庭环境中,OK-Robot在完成完整的拾取和放置任务中取得了58.5%的成功率。值得注意的是,这是一种零迁移算法,成功率是针对每个家庭中的新对象而言的。因此,机器人的每一次成功和失败都告诉我们在机器人技术中应用开放知识模型的一些有趣信息,这是我们在接下来的章节中分析的内容。
In Appendix C, we provide the details of all our home experiments and results from the same, and in Appendix B we show a subset of the objects OK-Robot operated on. Snippets of our experiments are in Figure 1, and full videos can be seen on our project website.
在附录C中,我们提供了所有家庭实验的详细信息和结果,在附录B中,我们展示了OK-Robot操作的一部分对象。实验的片段显示在图1中,完整的视频可以在我们的项目网站上观看。
B.Ablations over system components
B.对系统组件进行消融实验
Apart from the navigation and manipulation strategies that we used in the home experiments, we also evaluated a number of alternative semantic memory module and open vocabulary navigation modules. We compared them by evaluating them in three different environment setups in our lab.
除了我们在家庭实验中使用的导航和操作策略之外,我们还评估了许多替代的语义内存模块和开放词汇导航模块。我们通过在我们的实验室中的三种不同环境设置中评估它们来进行比较。
Alternate semantic navigation strategies: We evaluate the following semantic memory modules:
替代语义导航策略:我们评估了以下语义内存模块:
VoxelMap [25]: VoxelMap converts every detected object to a semantic vector and stores such info into an associated voxel. Occupied voxels serve as an obstacle map.
CLIP-Fields [27]: CLIP-Fields converts a sequence of posed RGB-D images to a semantic vector field by using open-label object detectors and semantic language embedding models. The result associates each point in the space with two semantic vectors, one generated via a VLM [9], and another generated via a language model [36], which is then embedded into a neural field [37].
• USA-Net [26]: USA-Net generates multi-scale CLIP features and embeds them in a neural field that also doubles as a signed distance field. As a result, a single model can support both object retrieval and navigation.
CLIP-Fields [27]:CLIP-Fields通过使用开放标签对象检测器和语义语言嵌入模型,将一系列定位的RGB-D图像转换为语义向量场。结果将空间中的每个点与两个语义向量关联,一个通过VLM [9]生成,另一个通过语言模型 [36]生成,然后嵌入到神经场 [37]中。
VoxelMap [25]:VoxelMap将每个检测到的对象转换为语义向量,并将这些信息存储到关联的体素中。占用的体素用作障碍图。
USA-Net [26]:USA-Net生成多尺度的CLIP特征,并将它们嵌入到神经场中,该神经场还兼作有符号距离场。因此,一个单一模型可以同时支持对象检索和导航。
We compare them in the same three environments with a fixed set of queries, the results of which are shown in Figure 5.
我们在相同的三个环境中使用一组固定的查询进行比较,其结果显示在图5中。
Alternate grasping strategies: Similarly, we compare multiple grasping strategies to find out the best grasping strategy for our method.
替代抓取策略:同样,我们比较了多种抓取策略,以找到我们方法的最佳抓取策略。
• AnyGrasp [19]: AnyGrasp is a single view RGB-D based grasping model. It is trained on the GraspNet dataset which contains 1B grasp labels. •
Open Graspness [19]: Since the AnyGrasp model is free but not open source, we use an open licensed baseline trained on the same dataset. •
Contact-GraspNet [16]: We use Contact-GraspNet as a prior work baseline, which is trained on the Acronym [38] dataset. One limitation of Contact-GraspNet is that it was trained on a fixed camera view for a tabletop setting. As a result, in our application with a moving camera and arbitrary locations, it failed to give us meaningful grasps. •
Top-down grasp [25]: As a heuristic based baseline, we compare with the top-down heuristic grasp provided in the HomeRobot project.
AnyGrasp [19]:AnyGrasp是一种基于单视图RGB-D的抓取模型。它在包含10亿个抓取标签的GraspNet数据集上进行训练。
Open Graspness [19]:由于AnyGrasp模型是免费但不开源的,我们使用在相同数据集上训练的开放授权基线。
Contact-GraspNet [16]:我们使用Contact-GraspNet作为先前工作的基线,该模型在Acronym [38]数据集上进行训练。Contact-GraspNet的一个局限性是它是在桌面设置的固定摄像机视图上进行训练的。因此,在我们的应用中,由于有移动摄像头和任意位置的情况,它未能提供有意义的抓取。
Top-down grasp [25]:作为基于启发式的基线,我们与HomeRobot项目中提供的自顶向下的启发式抓取进行比较。
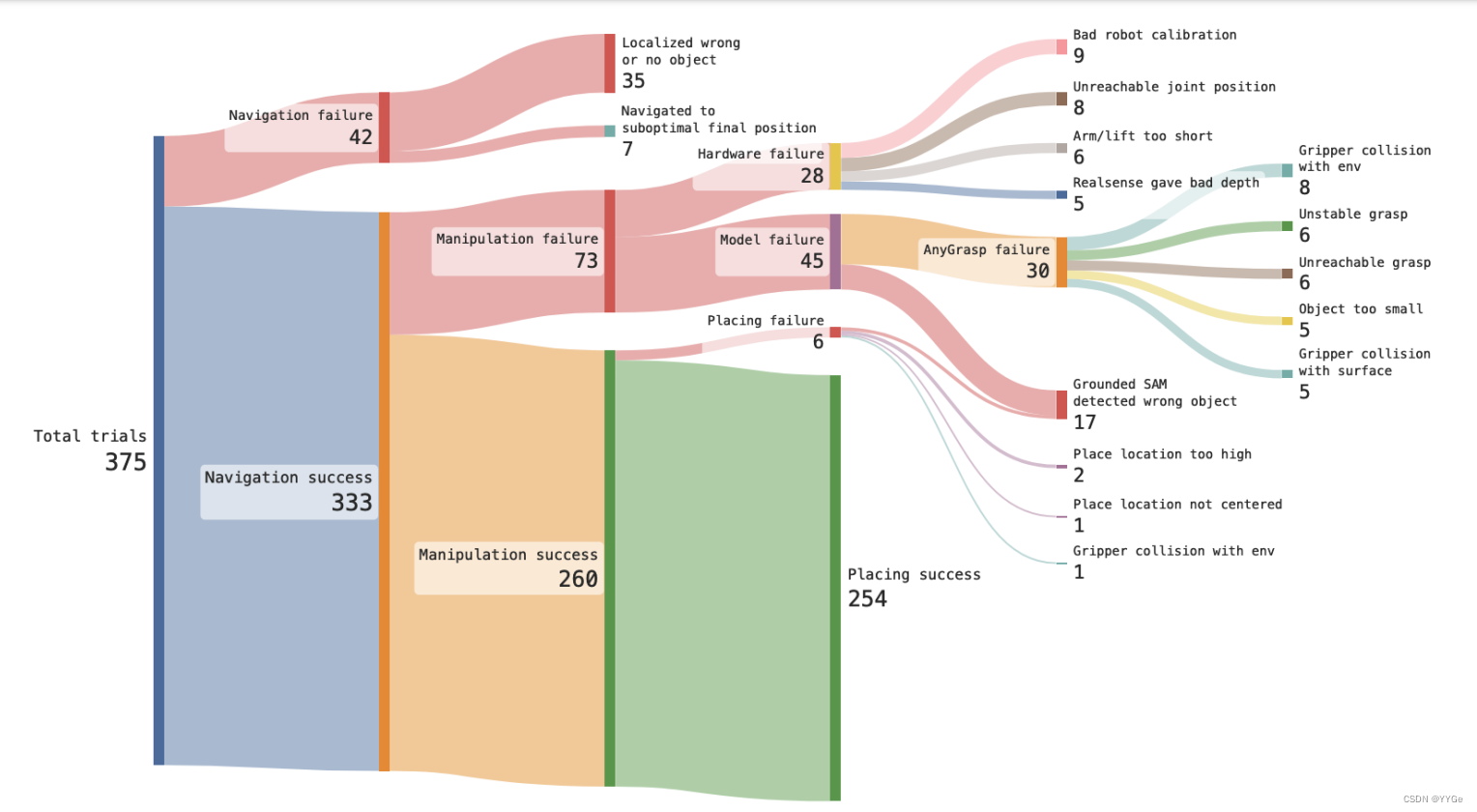
Fig. 4: All the success and failure cases in our home experiments, aggregated over all three cleaning phases, and broken down by mode of failure. From left to right, we show the application of the three components of OK-Robot, and show a breakdown of the long-tail failure modes of each of the components.
图4:在我们的家庭实验中,通过在所有三个清理阶段汇总的所有成功和失败案例,并按失败模式细分,从左到右显示了OK-Robot的三个组件的应用,并展示了每个组件的长尾失败模式的细分。
In Figure 5, we see their comparative performance in three lab environments. For semantic memory modules, we see that VoxelMap, used in OK-Robot and described in Sec. II-A, outperforms other semantic memory modules by a small margin. It also has much lower variance compared to the alternatives, meaning it is more reliable. As for grasping modules, AnyGrasp clearly outperforms other grasping methods, performing almost 50% better in a relative scale over the next best candidate, topdown grasp. However, the fact that a heuristic-based algorithm, top-down grasp from HomeRobot [25] beats the open-source AnyGrasp baseline and Contact-GraspNet shows that building a truly general-purpose grasping model remains difficult.
在图5中,我们看到了它们在三个实验室环境中的比较性能。对于语义内存模块,我们看到在OK-Robot中使用的VoxelMap(如第II-A节所述)在小幅度上表现优于其他语义内存模块。与替代方案相比,它的方差也较低,这意味着它更可靠。至于抓取模块,AnyGrasp明显优于其他抓取方法,在相对比例上比次佳候选项(自上而下的抓取)表现得好近50%。然而,基于启发式算法的事实,即HomeRobot [25]中的自上而下的抓取胜过了开源的AnyGrasp基线和Contact-GraspNet,表明构建一个真正通用的抓取模型仍然很困难。
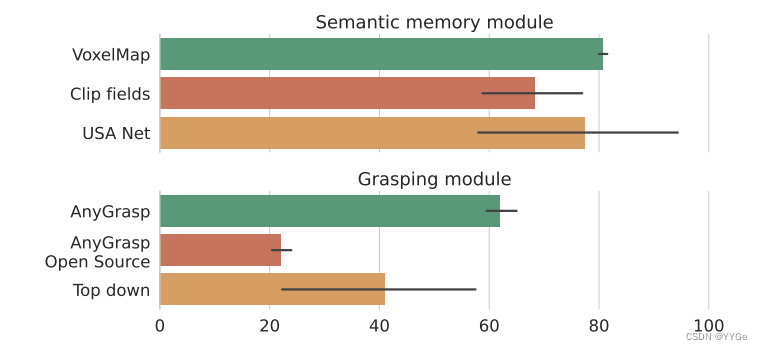
Fig. 5: Ablation experiment using different semantic memory and grasping modules, with the bars showing average performance and the error bars showing standard deviation over the environments.
图5:使用不同的语义内存和抓取模块进行消融实验,柱状图显示了平均性能,误差条显示了在环境中的标准差。
C.Impact of clutter, object ambiguity, and affordance
C.杂乱、对象模糊性和可用性的影响
What makes home environments especially difficult compared to lab experiments is the presence of physical clutter, language-to-object mapping ambiguity, and hard-to-reach positions. To gain a clear understanding of how such factors play into our experiments, we go through two “clean-up” processes in each environment. During the clean-up, we pick a subset of objects that are free from ambiguity from the previous rounds, clean the clutter around objects, and generally relocated them in an accessible locations. We go through two of such clean-up rounds at each environment, which gives us insights about the performance gap caused by the natural difficulties of a home-like environment.
家庭环境相较于实验室实验更具挑战性的原因之一是存在物理杂乱、语言到物体映射的模糊性以及难以触及的位置。为了清晰了解这些因素在我们实验中的影响,我们在每个环境中进行两轮“清理”过程。在清理过程中,我们选择一些在前几轮中没有歧义的对象子集,清理物体周围的混乱,并通常将它们重新放置在易于接触的位置。我们在每个环境中进行了两轮此类清理过程,这使我们能够了解类似家庭环境自然困难所导致的性能差距。
We show a complete analysis of the tasks listed section III-A which failed in various stages in Figure 6. As we can see from this breakdown, as we clean up the environment and remove the ambiguous objects, the navigation accuracy goes up, and the total error rate goes down from 15% to 12% and finally all the way down to 4%. Similarly, as we clean up clutters from the environment, we find that the manipulation accuracy also improves and the error rates decrease from 25% to 16% and finally 13%. Finally, since the drop-module is agnostic of the label ambiguity or manipulation difficulty arising from clutter, the failure rate of the dropping primitive stays roughly constant through the three phases of cleanup.
我们在图6中展示了第III-A节列出的任务的完整分析,这些任务在各个阶段都失败了。正如我们从这一分析中看到的,随着我们清理环境并消除模糊的对象,导航准确性提高,总错误率从15%降至12%,最终降至4%。同样,在清理环境中的混乱物体时,我们发现操作准确性也得到改善,错误率从25%降至16%,最终降至13%。最后,由于丢弃模块不知道标签模糊性或杂乱引起的操作难度,因此丢弃基元的失败率在清理的三个阶段中大致保持不变。
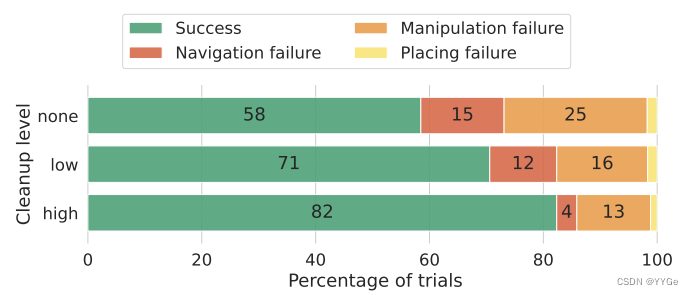
Fig. 6: Failure modes of our method in novel homes, broken down by the failures of the three modules and the cleanup levels.
图6:我们方法在新颖家庭中的失败模式,按照三个模块和清理水平的失败进行了细分。
D.Understanding the performance of OK-Robot
D.理解OK-Robot的性能。
While our method can show zero-shot generalization in completely new environments, we probe OK-Robot to better understand its failure modes. Primarily, we elaborate on how our model performed in novel homes, what were the biggest challenges, and discuss potential solutions to them.
虽然我们的方法可以在全新的环境中展示零-shot泛化,但我们对OK-Robot进行了调查,以更好地了解其失败模式。主要地,我们详细说明了我们的模型在新颖的家庭中的表现,最大的挑战是什么,并讨论了潜在的解决方案。
We first show a coarse-level breakdown of the failures, only considering the three high level modules of our method in Figure 6. We see that generally, the leading cause of failure is our manipulation failure, which intuitively is the most difficult as well. However, at a closer look, we notice a long tail of failure causes, which is presented in figure 4.
我们首先展示了对失败的粗略级别的分解,只考虑我们方法的三个高级模块,如图6所示。我们看到通常,失败的主要原因是我们的操纵失败,直观上这是最困难的。然而,仔细观察时,我们注意到了一长串的失败原因,如图4所示。
We see that the leading three cause of failures are failing to retrieve the right object to navigate to from the semantic memory (9.3%), getting a difficult pose from the manipulation module (8.0%), and hardware difficulties (7.5%). In this section, we go over the analysis of the failure modes presented in Figure 4 and discuss the most frequent cases.
我们看到失败的前三个原因是从语义记忆中检索到正确导航对象失败(9.3%),从操纵模块获得困难姿势(8.0%),以及硬件困难(7.5%)。在本节中,我们将讨论图4中呈现的失败模式的分析,并讨论最常见的情况。
Natural language queries for objects: One of the primary reasons our OK-Robot can fail is when a natural language query given by the user doesn’t retrieve the intended object from the semantic memory. In Figure 7 we show how some queries may fail while semantically very similar but slightly modified wording of the same query might succeed
对象的自然语言查询: 我们的OK-Robot可能失败的一个主要原因是用户提供的自然语言查询未从语义记忆中检索到预期的对象。在图7中,我们展示了一些查询可能失败的情况,而同一查询的语义非常相似但稍作修改的措辞可能成功。

Fig. 7: Samples of failed or ambiguous language queries into our semantic memory module. Since the memory module depends on pretrained large vision language model, its performance shows susceptibility to particular “incantations” similar to current LLMs.
图7:我们的语义记忆模块中失败或模糊语言查询的样本。由于记忆模块依赖于预训练的大型视觉语言模型,其性能对特定的“咒语”敏感,类似于当前的大型语言模型。
Generally, this has been the case for scenes where there are multiple visually or semantically similar objects, as shown in the figure. There are other cases where some queries may pass while other very similar queries may fail. An interactive system that gets confirmation from the user as it retrieves an object from memory would avoid such issues.
通常,这种情况发生在场景中存在多个在视觉上或语义上相似的对象的情况,如图中所示。还有其他情况,其中一些查询可能成功,而其他非常相似的查询可能失败。一个交互式系统,在从记忆中检索对象时从用户那里获得确认,将避免这些问题。
Grasping module limitations: One potential failure mode of our system is that our manipulation is performed by executing the outputs of a pre-trained model-generated grasps that are predicted based on a single RGB-D image, with a model that wasn’t designed for the Hello Robot: Stretch gripper
抓取模块的限制: 我们系统的一个潜在故障模式是,我们的操纵是通过执行基于单个RGB-D图像预测的预训练模型生成的抓取输出来执行的,该模型并非为Hello Robot: Stretch 夹具设计。
As a result, sometimes such grasps are unreliable or unrealistic, as shown in Figure 8. There are cases where the proposed grasp is infeasible given the robot joint limits, or is simply too far from the robot body. Development of better heuristics will let us sample better grasps for a given object. In some other cases, the model generates a good grasp pose, but as the robot is executing the grasping primitive, it collides with some minor environment obstacle. Since we do not plan the grasp trajectory, and instead try to apply the same grasp trajectory in every case, some such failures are inevitable. Better grasping models that generates a grasp trajectory as well as a pose may solve such issues. Finally, our grasping module struggles with flat objects categorically, like chocolate bars and books, since it’s difficult to grasp them off a surface with a two-fingered gripper.
因此,有时这些抓取可能是不可靠或不现实的,如图8所示。在某些情况下,建议的抓取在机器人关节限制下是不可行的,或者离机器人身体太远。开发更好的启发式方法将使我们能够为给定的对象采样更好的抓取。在其他一些情况下,模型生成了一个良好的抓取姿势,但由于机器人执行抓取基元时与一些微小环境障碍物发生碰撞。由于我们不规划抓取轨迹,而是尝试在每种情况下应用相同的抓取轨迹,因此一些这样的失败是不可避免的。生成抓取轨迹和姿势的更好的抓取模型可能会解决这些问题。最后,我们的抓取模块在分类上与平面物体的处理方面存在困难,如巧克力条和书籍,因为用两指夹持器从表面上抓取它们很困难。

图8:我们操纵模块失败的样本。大多数失败是由于仅使用单个RGB-D视图生成抓取以及大型双指并行爪夹的限制形状。
Robot hardware limitations: While our robot of choice, a Hello Robot: Stretch, is able to pick-and-drop a number of objects, there are certain hardware limitations that determines what the robot can and cannot manipulate. For example, the robot has a 1 kg (2 lbs) payload limit when the arm is fully extended, and as such our method is unable to move objects like a full dish soap container. Similarly, objects that are far from navigable floor space, such as in the middle of a bed, or on high places, is difficult for the robot to reach because of the reach limits of the arm. Finally, in some situations, the robot hardware or the RealSense camera can become miscalibrated over time, especially during continuous testing in homes. This miscalibration can lead to error since the manipulation module requires hand-eye coordination in the robot.
机器人硬件限制:虽然我们选择的机器人,Hello Robot: Stretch,能够拾取和放置许多对象,但有一些硬件限制决定了机器人可以操纵什么和不能操纵什么。例如,当手臂完全伸展时,机器人的负载限制为1千克(2磅),因此我们的方法无法移动像完整的洗碗液容器这样的物体。类似地,远离可导航地板空间的对象,例如床中央或高处的物体,由于机械臂的可达限制,机器人很难到达。最后,在某些情况下,机器人硬件或RealSense摄像头可能会随着时间的推移发生误校准,特别是在家庭中的连续测试期间。这种误校准可能导致错误,因为操纵模块需要机器人的手眼协调。
IV.RELATED WORKS
IV.相关工作
A.Vision-Language models for robotic navigation
A.视觉语言模型用于机器人导航
Early applications of pre-trained open-knowledge models has been in open-vocabulary navigation. Navigating to various objects is an important task which has been looked at in a wide range of previous works [25, 31, 39], as well as in the context of longer pick-and-place tasks [40, 41]. However, these methods have generally been applied to relatively small numbers of objects [42]. Recently, Objaverse [43] has shown navigation to thousands of object types, for example, but much of this work has been restricted to simulated or highly controlled environments
早期,预训练的开放知识模型在开放词汇导航中得到了应用。导航到各种物体是一个重要的任务,在许多先前的工作中进行了研究[25, 31, 39],以及在更长的拾取和放置任务的背景下[40, 41]。然而,这些方法通常只应用于相对较小数量的物体[42]。最近,Objaverse [43]展示了对成千上万种对象类型的导航,但其中大部分工作受到了模拟或高度受控制的环境的限制。
The early work addressing this problem builds upon representations derived from pre-trained vision language models, such as SemAbs [44], CLIP-Fields [27], VLMaps [45], NLMapSayCan [46], and later, ConceptFusion [47] and LERF [30]. Most of these models show object localization in pre-mapped scenes, while CLIP-Fields, VLMaps, and NLMap-SayCan show integration with real robots for indoor navigation tasks. USA-Nets [26] extends this task to include an affordance model, navigating with open-vocabulary queries while doing object avoidance. ViNT [48] proposes a foundation model for robotic navigation which can be applied to vision-language navigation problems. More recently, GOAT [31] was proposed as a modular system for “going to anything” and navigating to any object in any environment. ConceptGraphs [49] proposed an open scene representation capable of handling complex queries using LLMs and creating a scene graph.
解决这一问题的早期工作建立在从预训练的视觉语言模型中导出的表示上,例如SemAbs [44]、CLIP-Fields [27]、VLMaps [45]、NLMapSayCan [46],以及后来的ConceptFusion [47]和LERF [30]。这些模型大多展示了在预先映射的场景中的对象定位,而CLIP-Fields、VLMaps和NLMap-SayCan展示了与真实机器人的集成,用于室内导航任务。USA-Nets [26]扩展了这个任务,包括一个适应性模型,使用开放词汇查询进行导航同时避免对象。ViNT [48]提出了一个用于机器人导航的基础模型,可应用于视觉语言导航问题。最近,GOAT [31]被提出作为一个模块化系统,用于“去任何地方”并导航到任何环境中的任何对象。ConceptGraphs [49]提出了一个能够处理使用LLMs进行复杂查询并创建场景图的开放场景表示。
B.Pretrained robot manipulation models
B.预训练的机器人操纵模型
While humans can frequently look at objects and immediately know how to grasp it, such grasping knowledge is not easily accessible to robots. Over the years, there has been many works that has focused on creating such a general robot grasp generation model [1, 50–55] for arbitrary objects and potentially cluttered scenes via learning methods. Our work focuses on more recent iterations of such methods [16, 19] that are trained on large grasping datasets [18, 38]. While these models only perform one task, namely grasping, they predict grasps across a large object surface and thus enable downstream complex, long-horizon manipulation tasks [20, 21, 56].
虽然人类经常可以看着物体并立即知道如何抓取,但这种抓取知识对机器人来说并不容易获得。多年来,许多研究致力于创建这样一种通用的机器人抓取生成模型[1, 50–55],用于任意对象和潜在杂乱场景的学习方法。我们的工作侧重于这类方法的较新版本[16, 19],这些方法是在大型抓取数据集[18, 38]上进行训练的。虽然这些模型只执行一个任务,即抓取,但它们在整个对象表面上预测抓取,从而实现下游复杂、长程的操纵任务[20, 21, 56]。
More recently, there is a set of general-purpose manipulation models moving beyond just grasping [57–61]. Some of these works perform general language-conditioned manipulation tasks, but are largely limited to a small set of scenes and objects. HACMan [62] demonstrates a larger range of object manipulation capabilities, focused on pushing and prodding. In the future, such models could expand the reach of our system.
最近,出现了一组超越仅仅抓取的通用操纵模型[57–61]。其中一些作品执行通用的语言条件操纵任务,但主要限制在一小组场景和对象上。HACMan [62]展示了更大范围的物体操纵能力,侧重于推动和戳击。未来,这些模型可能会拓展我们系统的应用范围。
C.Open vocabulary robot systems
C.开放词汇的机器人系统
Many recent works have worked on language-enabled tasks for complex robot systems. Some examples include language conditioned policy learning [57, 63–65], learning goalconditioned value functions [3, 66], and using large language models to generate code [67–69]. However, a fundamental difference remains between systems which aim to operate on arbitrary objects in an open-vocab manner, and systems where one can specify one among a limited number of goals or options using language. Consequently, Open-Vocabulary Mobile Manipulation has been proposed as a key challenge for robotic manipulation [25]. There has previously been efforts to build such a system [70, 71]. However, unlike such previous work, we try to build everything on an open platform and ensure our method can work without having to re-train anything for a novel home. Recently, UniTeam [23] won the 2023 HomeRobot OVMM Challenge [22] with a modular system doing pickand-place to arbitrary objects, with a zero-shot generalization requirement similar to ours.
许多最近的研究致力于对复杂机器人系统进行语言启用的任务。一些例子包括语言条件的策略学习[57, 63–65],学习目标条件值函数[3, 66],以及使用大型语言模型生成代码[67–69]。然而,在旨在以开放词汇方式处理任意对象的系统与通过语言指定有限目标或选项之间仍存在根本差异。因此,开放词汇的移动操纵被提出为机器人操纵的一个关键挑战[25]。以前曾有过构建这样一个系统的成果[70, 71]。然而,与以前的工作不同,我们尝试在开放平台上构建一切,并确保我们的方法可以在不需要为新家庭重新训练任何内容的情况下工作。最近,UniTeam [23]赢得了2023年HomeRobot OVMM挑战 [22],他们的模块化系统可以对任意对象进行拾取和放置,具有与我们相似的零-shot泛化要求。
In parallel, recently, there have been a number of papers doing open-vocabulary manipulation using GPT or especially GPT4 [35]. GPT4V can be included in robot task planning frameworks and used to execute long-horizon robot tasks, including ones from human demonstrations [72]. ConceptGraphs [49] is a good recent example, showing complex object search, planning, and pick-and-place capabilities to openvocabulary objects. SayPlan [73] also shows how these can use used together with a scene graph to handle very large, complex environments, and multi-step tasks; this work is complementary to ours, as it doesn’t handle how to implement pick and place.
同时,最近有一些论文使用GPT或特别是GPT4 [35]进行开放词汇操纵。GPT4V可以包含在机器人任务规划框架中,并用于执行长程机器人任务,包括从人类演示中学习的任务[72]。ConceptGraphs [49]是一个很好的近期例子,展示了对开放词汇对象进行复杂的对象搜索、规划和拾取的能力。SayPlan [73]还展示了如何与场景图一起处理非常大、复杂的环境和多步任务;这项工作与我们的工作互补,因为它不涉及如何实现拾取和放置。
D.LIMITATIONS, OPEN PROBLEMS AND REQUEST FOR RESEARCH
D.局限性、开放问题和对研究的请求
While our method shows significant success in completely novel home environments, it also shows many places where such methods can improve. In this section, we discuss a few of such potential improvement in the future.
尽管我们的方法在完全新颖的家庭环境中取得了显著的成功,但也展示了这类方法可以改进的许多方面。在本节中,我们讨论了一些未来潜在的改进方向。
A.Live semantic memory and obstacle maps
A.实时语义记忆和障碍图
All the current semantic memory modules and obstacle map builders build a static representation of the world, without a good way of keeping it up-to-date as the world changes. However, homes are dynamic environments, with many small changes over the day every day. Future research that can build a dynamic semantic memory and obstacle map would unlock potential for continuous application of such pick-and-drop methods in a novel home out of the box.
所有当前的语义记忆模块和障碍图构建器都构建了世界的静态表示,没有有效的方法在世界发生变化时及时更新它。然而,家庭是动态环境,每天都会有许多微小的变化。未来的研究可以构建一个动态的语义记忆和障碍图,从而在新颖家庭中实现这种拾取和放置方法的连续应用。
B.Grasp plans instead of proposals
B.抓取计划而不是建议
Currently, the grasping module proposes generic grasps without taking the robot’s body and dynamics into account. Similarly, given a grasp pose, often the open loop grasping trajectory collides with environmental obstacles, which can be easily improved by using a module to generate grasp plans rather than grasp poses only.
目前,抓取模块提出了通用的抓取,没有考虑到机器人的身体和动力学。类似地,给定一个抓取姿势,通常开环抓取轨迹会与环境障碍物发生碰撞,通过使用一个模块生成抓取计划而不仅仅是抓取姿势,可以轻松改进这一点。
C.改进机器人与用户之间的互动
C.Improving interactivity between robot and user
我们方法中失败的主要原因之一是在导航中:语义查询模糊,从语义记忆中未检索到预期的对象。在这种模糊的情况下,与用户的交互将在很大程度上消除歧义,并帮助机器人更经常成功。
One of the major causes of failure in our method is in navigation: where the semantic query is ambiguous and the intended object is not retrieved from the semantic memory. In such ambiguous cases, interaction with the user would go a long way to disambiguate the query and help the robot succeed more often
D.Detecting and recovering from failure
D.检测和从故障中恢复
Currently, we observe a multiplicative error accumulation between our modules: if any of our independent components fail, the entire process fails. As a result, even if our modules each perform independently at or above 80% success rate, our final success rate can still be below 60%. However, with better error detection and retrying algorithms, we can recover from much more single-stage errors, and similarly improve our overall success rate [23].
目前,我们观察到我们的模块之间存在累积错误:如果任何一个独立组件失败,整个过程都会失败。因此,即使我们的模块每个独立地以80%或更高的成功率执行,我们的最终成功率仍可能低于60%。然而,通过更好的错误检测和重试算法,我们可以从更多的单阶段错误中恢复,并类似地提高我们的整体成功率。
E.Robustifying robot hardware
E.强化机器人硬件
While Hello Robot - Stretch [74] is an affordable and portable platform on which we can implement such an openhome system for arbitrary homes, we also acknowledge that with robust hardware such methods may have vastly enhanced capacity. Such robust hardware may enable us to reach high and low places, and pick up heavier objects. Finally, improved robot odometry will enable us to execute much more finer grasps than is possible today.
尽管Hello Robot - Stretch [74]是一个价格适中且便携的平台,我们可以在其上实现针对任意家庭的开放系统,但我们也承认,使用稳健的硬件,这类方法可能具有极大的增强能力。这样的坚固硬件可能使我们能够达到高处和低处,并拾取更重的物体。最后,改进的机器人测距系统将使我们能够执行比今天更精细的抓取。
ACKNOWLEDGMENTS
致谢
NYU authors are supported by grants from Amazon, Honda, and ONR award numbers N00014-21-1-2404 and N00014-21- 1-2758. NMS is supported by the Apple Scholar in AI/ML Fellowship. LP is supported by the Packard Fellowship. Our utmost gratitude goes to our friends and colleagues who helped us by hosting our experiments in their homes. Finally, we thank Jay Vakil, Siddhant Haldar, Paula Pascual and Ulyana Piterbarg for valuable feedback and conversations.
纽约大学的作者得到了亚马逊、本田和ONR奖项编号N00014-21-1-2404和N00014-21-1-2758的资助。NMS得到了苹果人工智能/机器学习奖学金的支持。LP得到了帕卡德奖学金的支持。我们最衷心地感谢帮助我们在他们家中进行实验的朋友和同事。最后,我们感谢Jay Vakil、Siddhant Haldar、Paula Pascual和Ulyana Piterbarg提供的宝贵反馈和交流。
APPENDIX A
附录 A
SCANNET200 TEXT QUERIES
SCANNET200文本查询
To detect objects in a given home environment using OWL-ViT, we use the Scannet200 labels. The full label set is here: [’shower head’, ’spray’, ’inhaler’, ’guitar case’, ’plunger’, ’range hood’, ’toilet paper dispenser’, ’adapter’, ’soy sauce’, ’pipe’, ’bottle’, ’door’, ’scale’, ’paper towel’, ’paper towel roll’, ’stove’, ’mailbox’, ’scissors’, ’tape’, ’bathroom stall’, ’chopsticks’, ’case of water bottles’, ’hand sanitizer’, ’laptop’, ’alcohol disinfection’, ’keyboard’, ’coffee maker’, ’light’, ’toaster’, ’stuffed animal’, ’divider’, ’clothes dryer’, ’toilet seat cover dispenser’, ’file cabinet’, ’curtain’, ’ironing board’, ’fire extinguisher’, ’fruit’, ’object’, ’blinds’, ’container’, ’bag’, ’oven’, ’body wash’, ’bucket’, ’cd case’, ’tv’, ’tray’, ’bowl’, ’cabinet’, ’speaker’, ’crate’, ’projector’, ’book’, ’school bag’, ’laundry detergent’, ’mattress’, ’bathtub’, ’clothes’, ’candle’, ’basket’, ’glass’, ’face wash’, ’notebook’, ’purse’, ’shower’, ’power outlet’, ’trash bin’, ’paper bag’, ’water dispenser’, ’package’, ’bulletin board’, ’printer’, ’windowsill’, ’disinfecting wipes’, ’bookshelf’, ’recycling bin’, ’headphones’, ’dresser’, ’mouse’, ’shower gel’, ’dustpan’, ’cup’, ’storage organizer’, ’vacuum cleaner’, ’fireplace’, ’dish rack’, ’coffee kettle’, ’fire alarm’, ’plants’, ’rag’, ’can’, ’piano’, ’bathroom cabinet’, ’shelf’, ’cushion’, ’monitor’, ’fan’, ’tube’, ’box’, ’blackboard’, ’ball’, ’bicycle’, ’guitar’, ’trash can’, ’hand sanitizers’, ’paper towel dispenser’, ’whiteboard’, ’bin’, ’potted plant’, ’tennis’, ’soap dish’, ’structure’, ’calendar’, ’dumbbell’, ’fish oil’, ’paper cutter’, ’ottoman’, ’stool’, ’hand wash’, ’lamp’, ’toaster oven’, ’music stand’, ’water bottle’, ’clock’, ’charger’, ’picture’, ’bascketball’, ’sink’, ’microwave’, ’screwdriver’, ’kitchen counter’, ’rack’, ’apple’, ’washing machine’, ’suitcase’, ’ladder’, ’ping pong ball’, ’window’, ’dishwasher’, ’storage container’, ’toilet paper holder’, ’coat rack’, ’soap dispenser’, ’refrigerator’, ’banana’, ’counter’, ’toilet paper’, ’mug’, ’marker pen’, ’hat’, ’aerosol’, ’luggage’, ’poster’, ’bed’, ’cart’, ’light switch’, ’backpack’, ’power strip’, ’baseball’, ’mustard’, ’bathroom vanity’, ’water pitcher’, ’closet’, ’couch’, ’beverage’, ’toy’, ’salt’, ’plant’, ’pillow’, ’broom’, ’pepper’, ’muffins’, ’multivitamin’, ’towel’, ’storage bin’, ’nightstand’, ’radiator’, ’telephone’, ’pillar’, ’tissue box’, ’vent’, ’hair dryer’, ’ledge’, ’mirror’, ’sign’, ’plate’, ’tripod’, ’chair’, ’kitchen cabinet’, ’column’, ’water cooler’, ’plastic bag’, ’umbrella’, ’doorframe’, ’paper’, ’laundry hamper’, ’food’, ’jacket’, ’closet door’, ’computer tower’, ’stairs’, ’keyboard piano’, ’person’, ’table’, ’machine’, ’projector screen’, ’shoe’].
为了使用OWL-ViT在给定的家庭环境中检测物体,我们使用Scannet200标签。完整的标签集在这里:[‘淋浴头’,‘喷雾’,‘吸入器’,‘吉他箱’,‘搔子’,‘抽油烟机’,‘卫生纸架’,‘适配器’,‘酱油’,‘管道’,‘瓶子’,‘门’,‘秤’,‘纸巾’,‘纸巾卷’,‘炉灶’,‘邮箱’,‘剪刀’,‘胶带’,‘浴室隔间’,‘筷子’,‘一箱瓶装水’,‘洗手液’,‘笔记本电脑’,‘酒精消毒’,‘键盘’,‘咖啡机’,‘灯’,‘烤面包机’,‘毛绒动物’,‘隔板’,‘衣服烘干机’,‘马桶座套分配器’,‘文件柜’,‘窗帘’,‘熨衣板’,‘灭火器’,‘水果’,‘物体’,‘百叶窗’,‘容器’,‘袋子’,‘烤箱’,‘沐浴露’,‘水桶’,‘CD盒’,‘电视’,‘托盘’,‘碗’,‘橱柜’,‘扬声器’,‘板条箱’,‘投影仪’,‘书’,‘书包’,‘洗衣粉’,‘床垫’,‘浴缸’,‘衣服’,‘蜡烛’,‘篮子’,‘玻璃’,‘洗面奶’,‘笔记本’,‘钱包’,‘淋浴’,‘电源插座’,‘垃圾箱’,‘纸袋’,‘水分配器’,‘包裹’,‘公告板’,‘打印机’,‘窗台’,‘消毒湿巾’,‘书架’,‘回收箱’,‘耳机’,‘梳妆台’,‘鼠标’,‘沐浴露’,‘簸箕’,‘杯子’,‘存储组织器’,‘吸尘器’,‘壁炉’,‘碗架’,‘咖啡壶’,‘火警器’,‘植物’,‘抹布’,‘罐头’,‘钢琴’,‘浴室柜’,‘架子’,‘靠垫’,‘显示器’,‘风扇’,‘管’,‘盒子’,‘黑板’,‘球’,‘自行车’,‘吉他’,‘垃圾桶’,‘洗手液’,‘纸巾架’,‘白板’,‘桶’,‘盆栽’,‘网球’,‘肥皂盒’,‘结构’,‘日历’,‘哑铃’,‘鱼油’,‘切纸机’,‘脚凳’,‘凳子’,‘洗手液’,‘灯’,‘烤箱’,‘音乐架’,‘水瓶’,‘时钟’,‘充电器’,‘图片’,‘篮球’,‘水槽’,‘微波炉’,‘螺丝刀’,‘厨柜’,‘架子’,‘苹果’,‘洗衣机’,‘手提箱’,‘梯子’,‘乒乓球’,‘窗户’,‘洗碗机’,‘储物容器’,‘卫生纸架’,‘衣架’,‘肥皂液器’,‘冰箱’,‘香蕉’,‘柜台’,‘卫生纸’,‘马克杯’,‘记号笔’,‘帽子’,‘气雾剂’,‘行李’,‘海报’,‘床’,‘手推车’,‘开关’,‘背包’,‘插座’,‘棒球’,‘芥末’,‘浴室梳妆台’,‘水罐’,‘壁橱’,‘沙发’,‘饮料’,‘玩具’,‘盐’,‘植物’,‘枕头’,‘扫帚’,‘胡椒’,‘松饼’,‘多种维生素’,‘毛巾’,‘储物箱’,‘床头柜’,‘散热器’,‘电话’,‘柱子’,‘纸巾盒’,‘通风口’,‘吹风机’,‘壁架’,‘镜子’,‘标志’,‘盘子’,‘三脚架’,‘椅子’,‘厨柜’,‘柱子’,‘饮水机’,‘塑料袋’,‘雨伞’,‘门框’,‘纸’,‘洗衣篮’,‘食物’,‘夹克’,‘衣柜门’,‘计算机主机’,‘楼梯’,‘键盘钢琴’,‘人’,‘桌子’,‘机器’,‘投影屏幕’,‘鞋’]。
APPENDIX B
附录 B
SAMPLE OBJECTS FROM OUR TRIALS
我们试验过程中的样本对象
During our experiments, we tried to sample objects that can plausibly be manipulated by the Hello Robot: Stretch gripper from the home environments. As a result, OK-Robot encountered a large variety of objects with different shapes and visual features. A subsample of such objects are presented in the Figures 9, 10.
在我们的实验中,我们试图采样能够被Hello Robot: Stretch夹具合理操纵的对象。因此,OK-Robot遇到了各种形状和视觉特征不同的对象。这些对象的子样本呈现在图9和图10中。

Fig. 9: Sample objects on our home experiments, sampled from each home environment, which OK-Robot was able to pick and drop successfully.
图9:我们家庭实验中的样本对象,从每个家庭环境中采样,OK-Robot成功拾取和放置。

Fig. 10: Sample objects on our home experiments, sampled from each home environment, which OK-Robot failed to pick up successfully.
图10:我们家庭实验中的样本对象,从每个家庭环境中采样,OK-Robot未能成功拾取。
APPENDIX C
附录 C
LIST OF HOME EXPERIMENTS
家庭实验列表
A full list of experiments in homes can be found in Table I.
有关家庭实验的完整列表可在表I中找到。
图略
这篇关于论文翻译:OK-Robot: What Really Matters in Integrating Open-Knowledge Models for Robotics的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
