本文主要是介绍4D毫米波雷达——RADIal数据集、格式、可视化 CVPR2022,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
本文介绍RADIal数据集,来自CVPR2022的。
- 它是一个收集了 2 小时车辆行驶数据的数据集,采集场景包括:城市街道、高速公路和乡村道路。
- 采集设备包括:摄像头、激光雷达和高清雷达等,并且还包括了车辆的 GPS 位置和行驶信息。
- 总共有 91 个视频序列,每个视频时长从 1 分钟到 4 分钟不等,加起来一共是 2 小时。这些视频详细记录了车辆在不同地点和环境下的行驶情况。
- 在大约 25,000 个录制的画面中,有 8,252 个画面被用来标记了 9,550 辆车。
论文地址:【CVPR2022】Raw High-Definition Radar for Multi-Task Learning
如下图所示,展示了相机图像,红色为投影的激光点云,靛蓝色为雷达点云,橙色为车辆标注,绿色为自由行驶空间标注。

如下图所示,展示了雷达功率谱、鸟瞰图、雷达的距离-方位图、GPS 轨迹和里程计轨迹。
- (b) 雷达功率谱,包含边界框注释;
- (c) 鸟瞰视图中的自由行驶空间注释,车辆用橙色边界框标注,雷达点云为靛蓝色,激光点云为红色;
- (d) 笛卡尔坐标系中的距离-方位图(Range-azimuth map),叠加雷达点云和激光点云;
- (e)GPS 轨迹以红色表示,里程计轨迹重建以绿色表示

公开可用的带雷达的驾驶数据集,如下表所示:

数据集规模被定义为“小”是指<15k 帧、“大”是指>130k 帧、“中等”是介于两者之间。
雷达分为低清晰度‘LD’、高清晰度‘HD’或扫描型‘S’,其数据以不同的表示形式发布,涉及不同的信号处理流程:
- 模拟至数字转换器‘ADC’信号
- 距离-方位-多普勒‘RAD’张量
- 距离-方位‘RA’视图
- 距离-多普勒‘RD’视图、点云‘PC’
多普勒信息的存在取决于雷达传感器。其他传感器模态包括相机‘C’、激光雷达‘L’和里程计‘O’。
RADIal 是唯一提供高清雷达的每种表示形式,并结合相机、激光雷达和里程计的数据集,同时在论文中提出检测和自由空间分割任务。
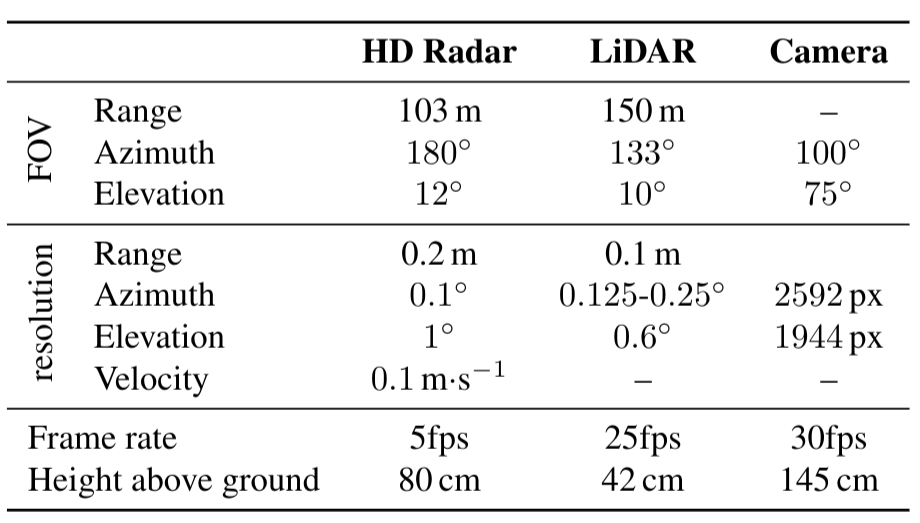
1、传感器规格
这里的高清雷达,全称为High-definition (HD) radar,简称为HD radar。(是4D毫米波雷达的一种)
- HD radar安装在前通风格栅的中间,如下图所示。
- 它是RADIal数据集的核心,由NRx=16个接收天线和NTx=12个发射天线组成,形成NRx·NTx= 192 个虚拟天线。
- 这种虚拟天线阵列能够达到高分辨率的水平方位角,同时估计物体的垂直仰角。

由于雷达信号难以被标注和直观理解,因此还提供了16线激光扫描仪 LiDAR 和 5 Mpix RGB 摄像头。
16线的激光雷达,对应 laser scanner (LiDAR) ,安装在前通风格栅的中间下方。摄像头安装在挡风玻璃后面的内后视镜附近。
三个传感器具有平行的水平视线,指向行驶方向。
RADIal还提供同步GPS和CAN轨迹,可以访问车辆的地理参考位置及其驾驶信息,如速度、方向盘角度和偏航角,传感器的规格如下表所示。
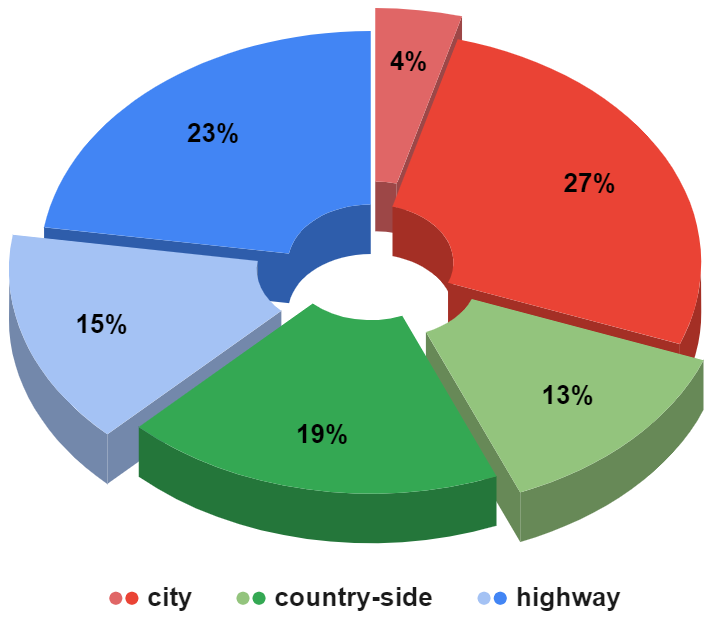
2、采集场景
采集场景主要包括城市街道、高速公路和乡村道路,如下图所示,是各个场景的数据占比。
3、数据集结构
RADIal是一个独立的文件夹,包含所有记录的序列。每个序列都是一个文件夹,其中包含:
- 现场预览视频(低分辨率);
- 相机数据以MJPEG格式压缩;
- 激光扫描仪点云数据保存在二进制文件中;
- 保存在二进制文件中的ADC雷达数据。总共有4个文件,每个雷达芯片一个文件,每个芯片包含4个Rx天线;
- 以 ASCII 格式保存的 GPS 数据
- 以二进制格式保存的车辆的CAN轨迹
- 最后,一个日志文件,提供每个传感器事件的时间戳。
RADIal代码地址:https://github.com/valeoai/RADIal/tree/main
在 Python 库 DBReader 中提供了读取数据。 由于所有雷达数据都以 RAW 格式记录,即模数转换 (ADC) 后的信号,因此也提供了一个优化的 Python 库 SignalProcessing 来处理雷达信号并生率谱、点云或距离-方位角图。
4、下载数据集
RADIal数据集分为“原始数据”和“即用型数据”。
原始数据集下载地址:GoogleDrive,然后需要使用 SignalProcessing 库为每种模态生成数据。原始数据需要申请的。
即用型数据下载地址:https://drive.google.com/drive/folders/1UJAQMr1Hv2KWsqgv_JYGd9TWea2v-Tqb 可以使用 Loader 文件夹中提供的 PyTorch 数据加载器示例进行加载。
推荐使用即用型数据,数据整体比较大

解压后,文件夹目录:

5、标签格式
在 25,000 个同步帧中,有 8,252 个帧被标记。 车辆的标签存储在单独的 csv 文件中。每个标签都包含以下信息:
- numSample:所有传感器之间当前同步样本的数量。这个标签可以投射到每个具有共同dataset_index值的传感器中。
- [x1_pix, y1_pix, x2_pix, y2_pix]:相机坐标中车辆2D框的二维坐标;
- [laser_X_m、laser_Y_m、laser_Z_m]:激光扫描仪坐标系统中车辆的 3D 坐标。其中 3D点是车辆后部或前部可见面的中间;
- [radar_X_m, radar_Y_m, radar_R_m, radar_A_deg, radar_D, radar_P_db]:雷达坐标系中车辆的二维坐标(鸟瞰图),采用笛卡尔坐标 (X,Y) 或极坐标 (R,A) 坐标。radar_D是多普勒值,radar_P_db是反射信号的功率;
- dataset:所属序列名称;
- dataset_index:当前序列中的帧索引;
- 难度:0 或 1
请注意,所有字段中的 -1 表示没有任何标签的帧。Free-driving-space 的标签以保存在 png 文件中的分段掩码形式提供。
看一下示例标签数据:
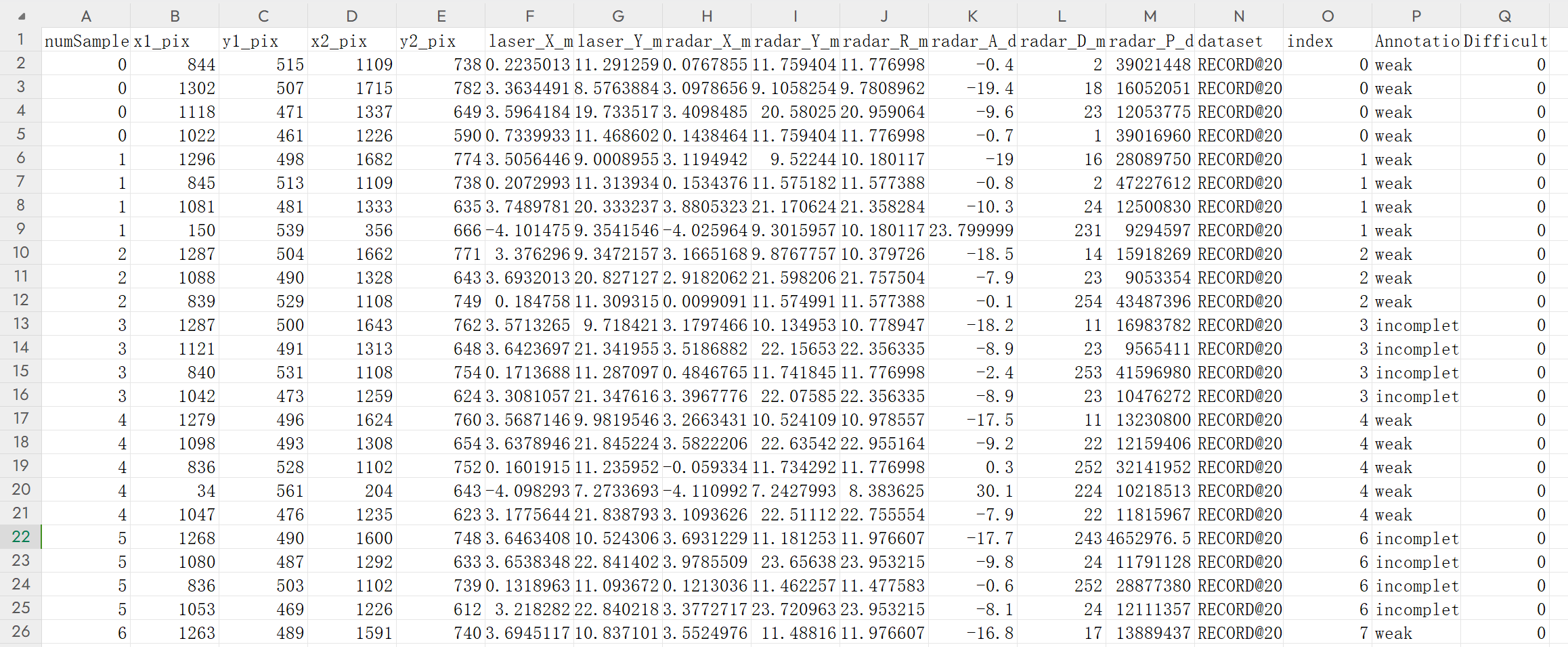
前20行的标签数据:
numSample x1_pix y1_pix x2_pix y2_pix laser_X_m laser_Y_m radar_X_m radar_Y_m radar_R_m radar_A_deg radar_D_mps radar_P_db dataset index Annotation Difficult
0 844 515 1109 738 0.223501295 11.29125881 0.076785527 11.75940418 11.77699757 -0.400000006 2 39021448 RECORD@2020-11-21_13.44.44 0 weak 0
0 1302 507 1715 782 3.363449097 8.576388359 3.097865582 9.105825424 9.780896187 -19.39999962 18 16052051 RECORD@2020-11-21_13.44.44 0 weak 0
0 1118 471 1337 649 3.596418381 19.73351669 3.409848452 20.58024979 20.95906448 -9.600000381 23 12053775 RECORD@2020-11-21_13.44.44 0 weak 0
0 1022 461 1226 590 0.733993292 11.46860218 0.143846378 11.75940418 11.77699757 -0.699999988 1 39016960 RECORD@2020-11-21_13.44.44 0 weak 0
1 1296 498 1682 774 3.50564456 9.0008955 3.1194942 9.522439957 10.18011665 -19 16 28089750 RECORD@2020-11-21_13.44.44 1 weak 0
1 845 513 1109 738 0.207299277 11.31393433 0.153437644 11.57518196 11.57738781 -0.800000012 2 47227612 RECORD@2020-11-21_13.44.44 1 weak 0
1 1081 481 1333 635 3.748978138 20.33323669 3.880532265 21.17062378 21.358284 -10.30000019 24 12500830 RECORD@2020-11-21_13.44.44 1 weak 0
1 150 539 356 666 -4.101474762 9.354154587 -4.025963783 9.301595688 10.18011665 23.79999924 231 9294597 RECORD@2020-11-21_13.44.44 1 weak 0
2 1287 504 1662 771 3.376296043 9.347215652 3.166516781 9.876775742 10.37972641 -18.5 14 15918269 RECORD@2020-11-21_13.44.44 2 weak 0
2 1088 490 1328 643 3.693201303 20.82712746 2.918206215 21.59820557 21.75750351 -7.900000095 23 9053354 RECORD@2020-11-21_13.44.44 2 weak 0
2 839 529 1108 749 0.184757978 11.30931473 0.009909126 11.57499123 11.57738781 -0.100000001 254 43487396 RECORD@2020-11-21_13.44.44 2 weak 0
3 1287 500 1643 762 3.571326494 9.718420982 3.179746628 10.1349535 10.77894688 -18.20000076 11 16983782 RECORD@2020-11-21_13.44.44 3 incomplete 0
3 1121 491 1313 648 3.642369747 21.34195518 3.518688202 22.15653038 22.35633469 -8.899999619 23 9565411 RECORD@2020-11-21_13.44.44 3 incomplete 0
3 840 531 1108 754 0.171368822 11.28709698 0.48467654 11.74184513 11.77699757 -2.400000095 253 41596980 RECORD@2020-11-21_13.44.44 3 incomplete 0
3 1042 473 1259 624 3.308105707 21.3476162 3.39677763 22.07584953 22.35633469 -8.899999619 23 10476272 RECORD@2020-11-21_13.44.44 3 incomplete 0
4 1279 496 1624 760 3.568714619 9.981954575 3.266343117 10.52410889 10.97855663 -17.5 11 13230800 RECORD@2020-11-21_13.44.44 4 weak 0
4 1098 493 1308 654 3.63789463 21.84522438 3.582220554 22.63541985 22.95516396 -9.199999809 22 12159406 RECORD@2020-11-21_13.44.44 4 weak 0
4 836 528 1102 752 0.160191536 11.23595238 -0.05933357 11.73429203 11.77699757 0.300000012 252 32141952 RECORD@2020-11-21_13.44.44 4 weak 0
4 34 561 204 643 -4.098292828 7.273369312 -4.110992432 7.242799282 8.383625031 30.10000038 224 10218513 RECORD@2020-11-21_13.44.44 4 weak 0
6、读取数据和可视化
这里使用官方代码,读取图像数据、激光点云数据、Radar点云数据,然后可视化。
RADIal代码地址:https://github.com/valeoai/RADIal/tree/main
1)图像数据
import numpy as np
from dataset import RADIal
from loader import CreateDataLoaders
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
from torch.utils.data import Dataset, DataLoader, random_split,Subset
dataset = RADIal(root_dir = './RADIal',difficult=True)
# pick-up randomly any sample
data = dataset.__getitem__(np.random.randint(len(dataset)))image = data[0]
boxes = data[5]fig, ax = plt.subplots(figsize=(20,20))
ax.imshow(image)for box in boxes:if(box[0]==-1):break # -1 means no objectrect = Rectangle(box[:2]/2,(box[2]-box[0])/2,(box[3]-box[1])/2,linewidth=3, edgecolor='r', facecolor='none')ax.add_patch(rect)# Note, coordinates are divided by 2 as image were saved in quarter resolution效果如下图所示

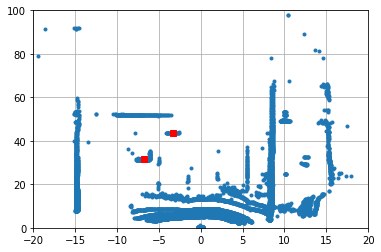
2)激光点云数据
laser_pc = data[3]plt.plot(-laser_pc[:,1],laser_pc[:,0],'.')
for box in boxes:if(box[0]==-1):break # -1 means no objectplt.plot(box[4],box[5],'rs')
plt.xlim(-20,20)
plt.ylim(0,100)
plt.grid()效果如下图所示
3)Radar点云数据
radar_pc = data[2]plt.plot(-radar_pc[:,1],radar_pc[:,0],'.')
for box in boxes:if(box[0]==-1):break # -1 means no objectplt.plot(box[7],box[8],'ro')
plt.xlim(-20,20)
plt.ylim(0,100)
plt.grid()效果如下图所示
本文先介绍到这里,后面会分享4D毫米波雷达的其它数据集、算法、代码、具体应用示例。
对于4D毫米波雷达的原理、对比、优势、行业现状,可以参考我这篇博客。
分享完成,本文只供大家参考与学习,谢谢~
这篇关于4D毫米波雷达——RADIal数据集、格式、可视化 CVPR2022的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








