本文主要是介绍YOLOv8-Seg改进:注意力涨点系列篇 | 多尺度双视觉Dualattention | Dual-ViT,顶刊TPAMI 2023,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
🚀🚀🚀本文改进:多尺度双视觉Dualattention注意yolo,提升小目标检测能力
🚀🚀🚀YOLOv8-seg创新专栏:http://t.csdnimg.cn/KLSdv
学姐带你学习YOLOv8,从入门到创新,轻轻松松搞定科研;
1)手把手教你如何训练YOLOv8-seg;
2)模型创新,提升分割性能;
3)独家自研模块助力分割;
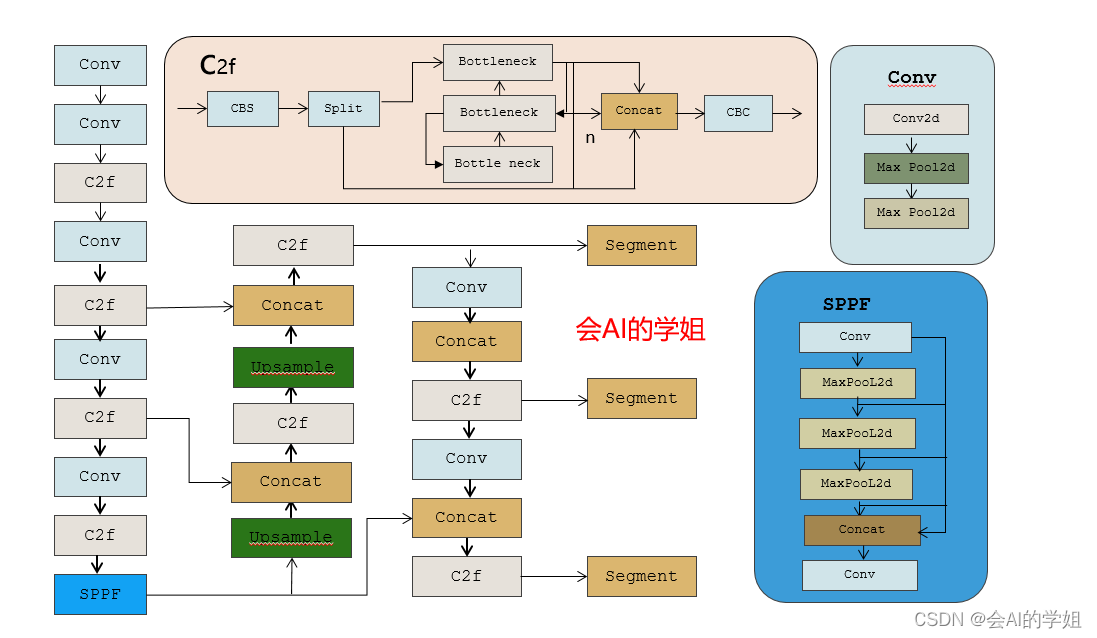
1.原理介绍

论文:Dual Vision Transformer | I
这篇关于YOLOv8-Seg改进:注意力涨点系列篇 | 多尺度双视觉Dualattention | Dual-ViT,顶刊TPAMI 2023的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







