本文主要是介绍如何探究大模型理论?UCLA最新《深度学习统计理论》综述,详述近似、训练动力学和生成模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

在这篇文章中,我们从三个角度回顾了神经网络的统计理论文献。在第一部分中,我们回顾了非参数框架下关于神经网络的过度风险(excess risks)的研究成果,这些成果适用于回归或分类。这些结果依赖于神经网络的显式构造,采用了近似理论的工具,导致过度风险的收敛速度较快。通过这些构造,可以根据样本大小、数据维度和函数平滑度来表达网络的宽度和深度。然而,它们的底层分析仅适用于深度神经网络高度非凸景观中的全局最小值。这促使我们在第二部分回顾神经网络的训练动力学。具体来说,我们回顾了试图回答“通过基于梯度的方法训练的神经网络如何找到能够在未见数据上泛化良好的解决方案”的论文。特别地,我们回顾了两种众所周知的范式:神经切线核(Neural Tangent Kernel,NTK)范式和平均场(Mean-Field,MF)范式。
在最后一部分中,我们回顾了生成模型的最新理论进展,包括生成对抗网络(Generative Adversarial Networks,GANs)、扩散模型,以及大型语言模型(Large Language Models,LLMs)中的上下文学习(in-context learning,ICL)。前两种模型被认为是现代生成人工智能时代的主要支柱,而ICL是LLMs在上下文中通过少数示例学习的强大能力。最后,我们通过提出几个深度学习理论的有前景的方向来结束这篇文章。
https://www.zhuanzhi.ai/paper/723a8b685e08dae08fe25cd03917454a
1 引言
近年来,作为机器学习的一个子领域,深度学习 [Goodfellow et al., 2016] 领域经历了重大的发展。它的影响已经超越了传统界限,在诸如医疗保健 [Esteva et al., 2019]、金融 [Heaton et al., 2017]、自主系统 [Grigorescu et al., 2020] 和自然语言处理 [Otter et al., 2020] 等行业中取得了显著进展。神经网络,我们大脑的数学抽象,是这一进步的核心。然而,在人工智能的持续复兴中,神经网络获得了几乎是神话般的地位,传播了它们更像艺术而非科学的误解。驱散这种观念是重要的。虽然神经网络的应用可能令人敬畏,但它们坚实地植根于数学原理中。在这种背景下,深度学习理论的重要性变得显而易见。几个关键点强调了其重要性。
1.1 为什么理论很重要?
在这一小节中,我们旨在强调在数学和统计框架内理解深度学习的重要性。以下是一些需要考虑的关键点:
-
深度学习是一个动态且快速发展的领域,在线上产生了成千上万的出版物。当今的模型特点是高度复杂的网络架构,包含许多复杂的子组件。在这种复杂性中,理解这些模型背后的基本原则变得至关重要。为了实现这种理解,将这些模型置于统一的数学框架中是必不可少的。这样的框架是一个宝贵的工具,可以从这些复杂模型中提取核心概念,使我们能够提取和理解推动其功能的关键原则。
-
将统计框架应用于深度学习模型,允许与其他统计方法进行有意义的比较。例如,像小波或核方法这样广泛使用的统计估计器可以引发关于深度神经网络何时何故可能表现更好的问题。这种分析帮助我们理解深度学习相比传统统计方法何时表现出色,从而使理论和实践受益。
-
超参数,如学习率、权重初始化、网络架构选择、激活函数和批量大小,显著影响估计模型的质量。理解这些超参数的适当范围对于理论家和实践者都是必要的。例如,在大数据时代,当一个数据集中有数百万个样本时,理论智慧告诉我们网络的深度应该在样本大小的对数中进行缩放,以便良好地估计组合函数 [Schmidt-Hieber, 2020]。
在这篇综述中,我们提供了深入这些概念的论文概述,并在精确的数学设置中为读者提供了上述话题的具体见解。在这里,我们试图避免过多的技术性内容,并使介绍尽可能对各个领域的统计学家都易于理解。
1.2 论文概览
我们将神经网络的统计理论现有文献分类为三类。
-
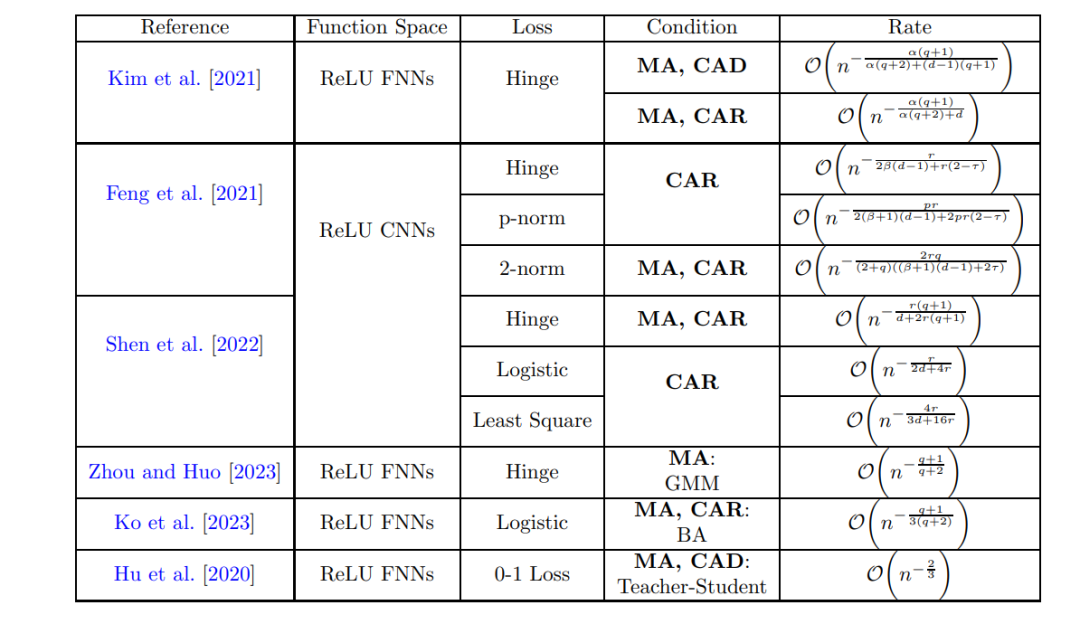
近似理论视角。最近,出现了大量工作,这些工作将神经网络模型的近似理论 [Yarotsky, 2017, Mhaskar, 1996, Petersen and Voigtlaender, 2018, Schmidt-Hieber, 2020, Montanelli and Du, 2019, Blanchard and Bennouna, 2022, Hornik et al., 1989, Hanin, 2019] 与实证过程中的工具 [Van de Geer, 2000] 结合起来,以获得在非参数设置下回归 [Schmidt-Hieber, 2020, Hu et al., 2021] 和分类 [Hu et al., 2020, Kim et al., 2021] 任务中过度风险的快速收敛率。近似理论在测量神经网络在某些类别中近似函数的基本复杂性方面提供了有用的视角。具体来说,它使得神经网络的显式构造成为可能,以便我们知道为了获得良好的收敛率,网络的宽度、深度和活跃参数的数量应该如何根据样本大小、数据维度和函数平滑度指标来缩放。为了简单起见,我们主要考虑将全连接神经网络用作函数估计器的工作。这些工作包括 Schmidt-Hieber [2020], Kim et al. [2021], Shen et al. [2021], Jiao et al. [2021], Lu et al. [2021], Imaizumi and Fukumizu [2019, 2022], Suzuki [2018], Chen et al. [2019b], Suzuki and Nitanda [2021], Suh et al. [2022] 等,在不同的问题设置下进行研究。然而,这些工作假设损失函数的全局最小值是可获得的,并且主要关注这些最小值的统计属性,而不考虑任何优化问题。但鉴于损失函数的非凸性以及隐藏层中激活函数的非线性,这是一个强假设。
-
训练动力学视角。在这个背景下,理解神经网络模型的非凸损失函数景观及其对神经网络泛化能力的影响成为文献中的下一个步骤。例如,一个开创性的实证发现 [Zhang et al., 2021] 揭示了通过随机梯度下降训练的足够过参数化的神经网络模型可以完美拟合(嘈杂的)数据甚至随机噪声,但同时它们仍然可以很好地泛化。在许多关于过参数化的重要发现中,如 Arora et al. [2019b], Jacot et al. [2018] 揭示,通过梯度下降(GD)在 ℓ2-损失下训练的足够宽度的深度神经网络的动力学,表现与在再生核希尔伯特空间(RKHS)中的函数类似,其中的核与特定网络架构相关联。许多后续工作研究了在内核范式下神经网络的训练动力学和泛化能力 [Suh et al., 2021, Hu et al., 2021, Nitanda and Suzuki, 2020]。尽管如此,神经网络表现出的不仅仅是内核回归,例如特征学习 [Yang and Hu, 2020]。这种能力是通过允许网络参数显著偏离其初始值来实现的,这是内核范式所不允许的。许多研究者试图填补这一差距 [Ghorbani et al., 2020b, Wei et al., 2019],证明了神经网络相对于内核范式网络的统计优势,但仍然限制了网络参数可能的可行距离。另一重要的研究方向试图解释神经网络在不同范式下的学习动力学,被称为平均场(MF)范式。在这个范式下,网络参数有显著偏离其初始值的灵活性,尽管这需要无限的宽度。最后,我们通过介绍一个统一的框架 Yang and Hu [2020] 来结束这一部分,该框架使我们全面理解基于梯度的方法中权重初始化和学习率缩放的选择如何影响神经网络在其无限宽度极限下的动力学。
-
生成模型。在这一部分中,我们回顾了最新的生成模型理论进展,包括生成对抗网络(GANs),扩散模型,以及大型语言模型(LLMs)中的上下文内学习。在过去的十年中,GANs [Goodfellow et al., 2014] 作为一种显著的无监督学习方法脱颖而出,以其学习数据分布和高效采样数据的能力而闻名。在这篇综述中,我们将介绍研究GANs统计属性的论文 [Arora et al., 2017, Liang, 2021, Chen et al., 2020a, Bai et al., 2018, Zhang et al., 2017, Schreuder et al., 2021]。最近,另一组生成模型,即扩散模型,在生成各种数据模态的高质量合成数据方面表现出色,包括图像 [Song et al., 2020, Dhariwal and Nichol, 2021],表格数据 [Kim et al., 2022, Suh et al., 2023],医学成像 [M¨uller-Franzes et al., 2022] 等,大幅度超过基于GAN的模型。然而,鉴于模型的复杂性和它在社区中的最近引入,为什么它表现如此出色的理论原因仍然不明确。最后,我们将回顾在大型语言模型中观察到的一个有趣现象,即上下文内学习(ICL)。它指的是LLMs在输入-输出对的任务示例(输入-输出对)和新查询输入的提示序列条件下,可以准确地生成相应的输出。读者可以参考 Gui et al. [2021], Yang et al. [2022] 的综述论文,了解GANs和扩散模型在各个领域的方法论和应用的详细描述。关于ICL的概述,请参阅 Dong et al. [2022] 的综述,其中突出了这个方向的一些关键发现和进展。
1.3 深度学习理论现有综述
据我们所知,目前有三篇关于深度学习理论的综述论文 [Bartlett et al., 2021; Fan et al., 2021; Belkin, 2021]。这些论文在某些主题上存在重叠,但它们的主要焦点各不相同。Bartlett et al. [2021] 提供了一个全面而技术性的综述,专注于深度神经网络的统计理解。特别是,作者着重考察了神经网络中超参数化的显著影响,这在使基于梯度的方法发现插值解方面起着关键作用。这些方法引入了隐式正则化,如Neyshabur [2017]讨论的,或导致了一种称为良性过拟合的现象 Bartlett et al. [2020]。Fan et al. [2021] 介绍了实践中最常用的神经网络架构,如卷积神经网络(CNN)、循环神经网络(RNN),以及从统计角度出发的训练技术,如批量标准化、dropout等。同时,也简要介绍了神经网络的近似理论。
与Bartlett et al. [2021]类似,Belkin [2021] 回顾了超参数化在隐式正则化和良性过拟合方面的作用,这不仅观察于神经网络模型,也观察于经典的统计模型,如加权最近邻预测器。最值得注意的是,他们通过优化的视角提供了对神经网络非凸损失景观的超参数化角色的直观理解。
这篇关于如何探究大模型理论?UCLA最新《深度学习统计理论》综述,详述近似、训练动力学和生成模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






