本文主要是介绍【数据分析实战】冰雪大世界携程景区游客客源分布pyecharts地图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 引言
- 数据集展示
- Python代码
- 可视化展示
- 本人浅薄分析
- 写在最后
今年冬天,哈尔滨冰雪旅游"杀疯了",在元旦假期更是被南方游客"包场"。据哈尔滨市文化广电和旅游局提供大数据测算,截至元旦假日第3天,哈尔滨市累计接待游客304.79万人次,实现旅游总收入59.14亿元。游客接待量与旅游总收入达到历史峰值。
“不是北欧去不起,而是哈尔滨更有性价比。”
“零下二十摄氏度,我在哈尔滨当‘俄式公主’。”
引言
上一期我们分享了景区用户评价数据可以从哪些维度去分析,如词云、情感等;
【数据分析实战】冰雪大世界携程景区评价信息情感分析采集词云
今天我们通过之前采到的评价数据,了解一下哈尔滨的客源是从哪个省市来的。顺便分享一下pyecharts中地图的用法。
注:该分析只包括有ip地的数据
数据集展示
| _id | publishTime | score | content | publishTypeTag | ipLocatedName | touristTypeDisplay | |
|---|---|---|---|---|---|---|---|
| 0 | 180204656 | /Date(1703671819000+0800)/ | 5 | 太壮观啦,上一次是10年前来的,变化很大… | 2023-12-27 发布点评 | 上海 | 情侣夫妻 |
Python代码
# 城市名一定要和地图上显示的对应,不然出不来city_data = [('台湾省', 1)] # 示例数据
special_cases = {'上海': '上海市','北京': '北京市','重庆': '重庆市','内蒙古': '内蒙古自治区','西藏': '西藏自治区','广西': '广西壮族自治区','宁夏': '宁夏回族自治区','新疆': '新疆维吾尔自治区'
}for k, v in pd.value_counts(df['ipLocatedName']).to_dict().items():k = special_cases.get(k, f'{k}省')city_data.append((k, v))
from pyecharts import options as opts
from pyecharts.charts import Map
from pyecharts.globals import ThemeType# 创建地图对象
map = Map(init_opts=opts.InitOpts(theme=ThemeType.ESSOS, height="800px"))# 添加数据到地图
map.add("", city_data, "china")# 设置全局配置
map.set_global_opts(title_opts=opts.TitleOpts(title="【冰雪大世界】接待省域游客分布图",subtitle="数据来源:该统计分析仅包含显示ip所属地的评价数据",pos_right="center",pos_top="5%"),visualmap_opts=opts.VisualMapOpts(max_=139),
)# 在Jupyter Notebook中显示地图
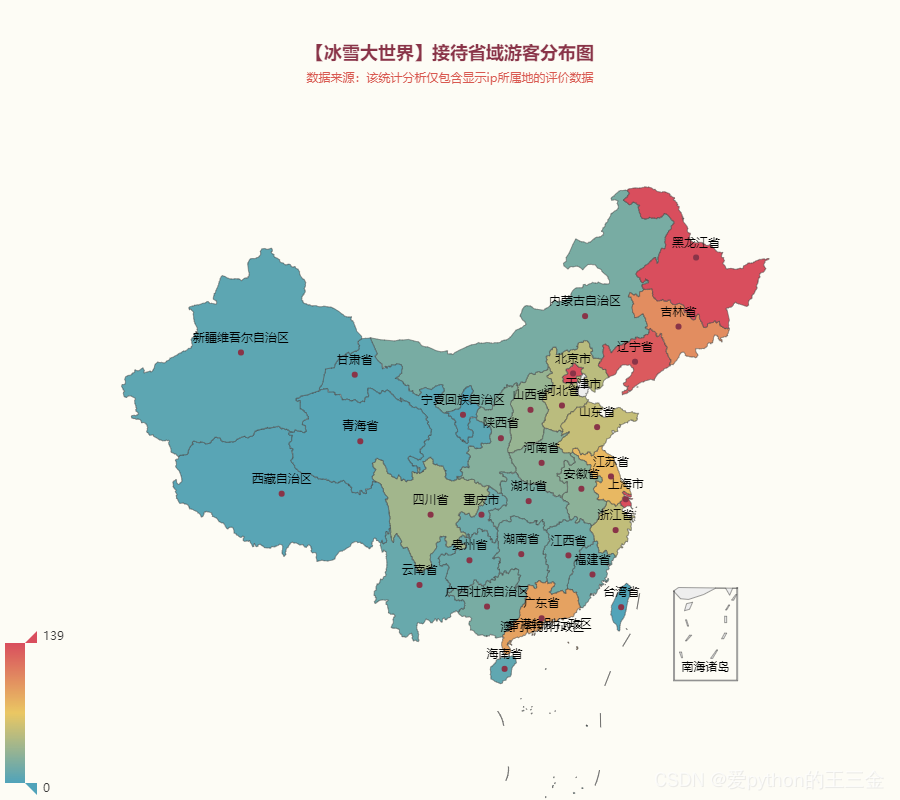
map.render_notebook()可视化展示
本人浅薄分析
通过评论的ip地我们知道了各省市前往哈尔滨冰雪大世界旅游的客源数据,分享下我观察到的点:
-
本地游客主导:
- 黑龙江省作为哈尔滨冰雪大世界所在地,也是主要的客源省份,有802人次。可以看出本地居民对于冰雪大世界的强烈兴趣和持续关注。
-
大城市客源显著:
- 上海市和北京市依然居高不下,分别为139人次。这可能受到这两个大城市居民对于冰雪活动的热爱以及便捷的交通条件的影响。
-
地域分布广泛:
- 游客依然来自全国各地,表明哈尔滨冰雪大世界在全国范围内都有较强的吸引力。虽然黑龙江省的游客最多,但其他省市的游客数量也不可忽视。
-
地方性游客集中现象:
- 一些省市的客源较为集中,如吉林省、辽宁省、广东省、江苏省等。这可能与这些地区的宣传力度、旅游市场发展和地理位置有关,有些南方小土豆没见过雪等。
-
一些地区游客较少:
- 一些省份和自治区的客源相对较少,这可能受到地理位置偏远、交通不便等因素的影响。对于这些地区,哈尔滨冰雪大世界可以考虑加强宣传和推广,吸引更多游客。
需要采集数据的可以联系我~
写在最后
通过对冰雪大世界5528条携程用户公开评价的深入分析,我们深入了解了客源的情况,以及景区在哪些地区推广较弱等。
该分析仅供学习交流使用,禁止用于商业用途,不构成任何投资建议。
大数据分析为运营和各行业带来了前所未有的机会,使企业能够更敏锐地洞察市场、优化运营,并更有效地应对竞争和变革。在信息时代,充分利用大数据分析,将成为企业取得竞争优势的不可忽视的关键要素。
本人数据分析领域的从业者,拥有专业背景和能力,可以为您的数据挖掘和分析需求提供支持。期待着能够与您共同探索更多有意义的数据洞见,为您的项目和业务提供数据分析方面的帮助。
创作不易,如果你觉得有帮助,请点个赞支持一下。你的鼓励是我创作的最大动力,期待未来能为大家带来更多有趣的分析文章。感谢大家的阅读和支持!
这篇关于【数据分析实战】冰雪大世界携程景区游客客源分布pyecharts地图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









