本文主要是介绍大模型推理优化实践:KV cache 复用与投机采样,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:米基
一、背景
RTP-LLM 是阿里巴巴大模型预测团队开发的大模型推理加速引擎,作为一个高性能的大模型推理解决方案,它已被广泛应用于阿里内部。该引擎与当前广泛使用的多种主流模型兼容,并通过采用高性能的 CUDA 算子来实现了如 PagedAttention 和 Continuous Batching 等多项优化措施。RTP-LLM 还支持包括多模态、LoRA、P-Tuning、以及 WeightOnly 动态量化等先进功能。
随着大模型的广泛应用,如何降低推理延迟并优化成本已成为业界关注的焦点。我们不断地在这一领域内探索和挖掘新方法。在本文中,我们将详细介绍两种在业务中实践的优化策略:多轮对话间的 KV cache 复用技术和投机采样方法。我们会细致探讨这些策略的应用场景、框架实现,并分享一些实现时的关键技巧。
二、多轮对话复用 KV cache
在淘宝问问中,有两类多轮对话的场景:一是问答类的场景,它每次请求模型时会拼接之前的问答;二是 LangChain 应用,它在模型生成结束后会调用外部插件,拼接插件返回的结果再次请求模型。这两类场景共同的问题是:随着对话轮数的增加,请求长度变长,导致模型的 First Token Time(下称 FTT)不断变长。
模型的 FTT 变长,本质上是因为第一次进入模型时,越来越多的 token 需要生成 KV cache。考虑到这两种多轮对话场景存在一个共同点:前一轮对话的输出构成后一轮对话输入的一部分,或者存在较长的公共前缀。且大部分自回归模型(除了 chatglm-6b)的 Attention Mask 都是下三角矩阵:即某一位置 token 的注意力与后续 token 无关,因此两轮对话公共前缀部分的 KV cache 是一致的。进而能够想到的解决办法是:保存上一轮对话产生的 KV cache,供下一轮对话时复用,就能减少下一轮需要生成 KV cache 的 token 数,从而减少 FTT。根据这个思路改进前后的模型如下:

2.1 框架设计
用户请求对应的 KV cache 存放在机器显存中,因此不同轮次的对话需要请求同一台机器,才能复用 KV cache。但是在生产环境中,模型部署在由多台机器组成的机器集群,用户层的请求由统一域名服务转发到机器集群中某一台机器上,这样的架构设计导致不同轮对话命中同一台机器的概率微乎其微。
最直观的解决办法是让用户去记录首次请求的机器信息,并将后续请求同一台机器。这个方法可行但是不合理,用户不仅需要感知机器集群的具体信息,还需要对自己链路做大量改造;进而能想到的办法是增加一层转发层,用户将多轮请求携带同样的标识 id 并发送给转发层,转发层感知集群信息并匹配标识 id 和下游机器。这样不同轮对话就能打到同一台存有 KV cache 的下游机器。至于如何在转发机器间同步匹配信息,可以使用分布式数据库记录,我们采样的方法是使用统一的哈希算法,将相同 id 哈希到固定的机器。只要选择合适的哈希算法,就能在机器集群负载均衡的同时让多轮对话命中同一台机器。
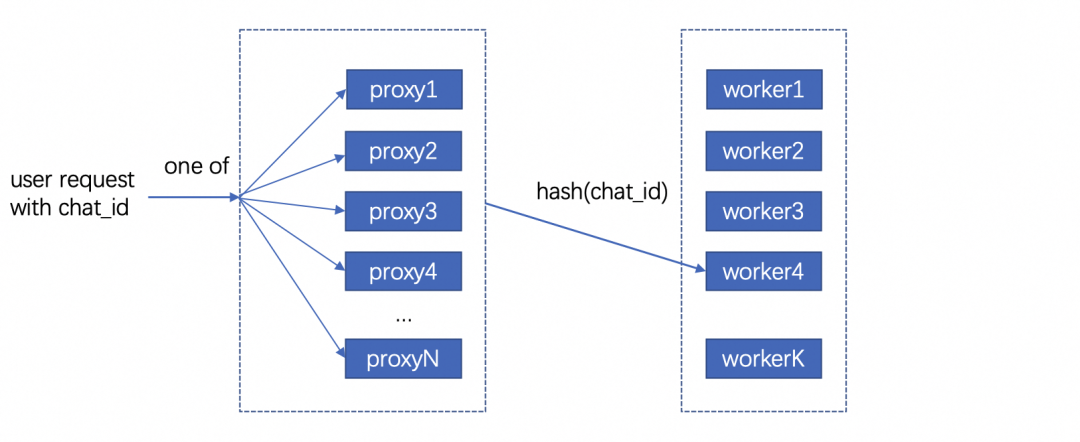
在底层实现上,复用 KV cache 的逻辑和 P-Tuning v2 在实现上非常相似,通过复用参数,我们使用 PTuning 的算子支持了 KV cache 复用。
2.2 总结与反思
我们在 Qwen13B/int8 量化/A10 机器的条件下,对不同输入和前缀长度的请求进行了测试:

可以看到在复用 KV cache 功能极大程度的减少了 FTT,并且历史长度的变化对 FTT 的影响较小,FTT 更多的取决于本次请求的输入长度。并且除了多轮对话场景外,KV cache 复用功能也扩展到复用 Ptuning 前缀和长 System Prompt 的场景,降低 FTT 和显存占用。
虽然复用 KV cache 的功能能够显著减少多轮对话场景下的 FTT,但是在服务压力过大时,存放历史 KV cache 的显存可能被新请求占用,导致后续请求出现 cache miss 请求时间变长,加剧服务压力最后导致雪崩。目前我们已实现的解决方案是使用 LRU 算法优先移除较旧请求的 KV cache。未来进一步的策略是参照 vllm 的思路,将过期的 KV cache 转移到内存,必要时重新加载至显存。这种策略比重新计算快,有助于减轻极端情况下的请求延迟,防止服务雪崩。
三、投机采样
3.1 介绍
投机采样最早在 2022 年的 Fast Inference from Transformers via Speculative Decoding 提出,因为不久前的 gpt4 泄密而被更多人知道。投机采样的设计基于两点认知:在模型推理中,token 生成的难度有差别,有部分 token 生成难度低,用小参数草稿模型(下简称小模型)也能够比较好的生成;在小批次情况下,原始模型(下简称大模型)在前向推理的主要时间在加载模型权重而非计算,因此批次数量对推理时间的影响非常小。
基于以上两点认知,投机推理的每一轮的推理变成如下步骤: 1. 使用小模型自回归的生成 N 个 token 2. 使用大模型并行验证 N 个 token 出现的概率,接受一部分或者全部 token。由于小模型推理时间远小于大模型,因此投机采样在理想的情况下能够实现数倍的推理速度提升。同时,投机采样使用了特殊的采样方法,来保证投机采样获得的 token 分布符合原模型的分布,即使用投机采样对效果是无损的。

上图是投机采样的运行过程,每一行的绿色 token 代表小模型生成并被大模型接受的部分,红色 token 是小模型生成但被大模型拒绝的部分,蓝色 token 是大模型根据最后接受 token 的 logits 重新采样出来的部分。由上可以看到使用投机采样,在合适的场景下能够大幅提高每轮生成的 token 数,降低平均单个 token 生成时间。
3.2 设计思路
我们在 RTP-LLM 中基于论文的思路,使用大小模型进行了投机采样的实践。在代码设计上我们一方面考虑系统的可维护性,希望这部分能够和原始流程解耦;其次投机采样优化需要与其他优化正交,使投机采样时两个模型都能够用上 FT 的其他优化。最后我们的设计是为投机采样封装了一层编排层,对外提供统一的 API,在内部组织参数顺序调用正常流程。

3.3 性能评估
在实现过程中,我们着重关注投机采样引入的额外负担。我们希望做到在系统每轮接受 token 数较少的情况下,也能有与原始模型相近的表现。在实践中,我们测得额外时间消耗主要有两块:小模型顺序生成 token 引入时间和采样。
首先最直观的额外消耗,就是小模型推理所占用的时间。在小模型顺序生成 N 个 token 时,会有 N*T_{small\_model}的时间,在 N 较大且接受 token 数少的情况下,这部分开销会非常大。值得一提的时最初我们假设模型消耗时间和参数规模成正比,而实际上这个猜测是错误的。我们测试得到在参数规模减少的情况下, lm_head 在模型调用的占比会显著增加。以下是 Qwen1.8B 和 Qwen13B 在 A10/half 条件下,单个 token 在 Transformer 网络(transformer_layer)和输出层(lm_head)的时间对比:

造成上述比例不一致原因在于:模型参数规模从 13B 变成 1.8B 时, Transformer 网络在层数(40 -> 24)和权重大小(5120 -> 2048)两个维度减少,而输出层的参数仅从[5120, 152064]变成[2048, 152064] 。同时因为模型词表通常很大,因此输出层的时间通常也比较长。除了输出层的影响以外,在一些情况下小模型矩阵乘对硬件的利用率并没有大模型这么高,因此在选择小模型时需要对这部分开销进行更谨慎的估计。
其次重复多次的采样也引入了巨大的开销。从上面流程图可以看到,在一轮投机采样流程中,需要进行 N 次小 batch 采样和 1 次大 batch 采样。我们以 a10/half/vocab_size=152064/top_k=0.5/top_p=0.95 的情况下用 huggingface 采样逻辑进行了测试:
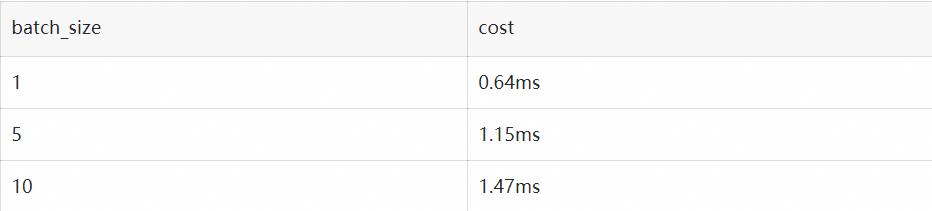
假设在原始请求 batch 为 2, 投机采样每次出 5 个 token 的条件下,需要 1.15*5+1.47=7.221.15∗5+1.47=7.22 毫秒的时间,这接近上述 1.8B 小模型一次推理的总时长。
好在 FT 的采样流程针对存在 top_k 参数的情况,通过融合算子对原版(Huggingface 流程)进行了优化,改进后的流程分成两步:对维度是[batch, vocab]的输入进行 TopK 采样后,使用输出维度是[batch, k]的 tensor 进行后续流程;省略 TopP 步骤,直接在采样过程中对 TopP 进行判断。改进前后的流程对比如下:
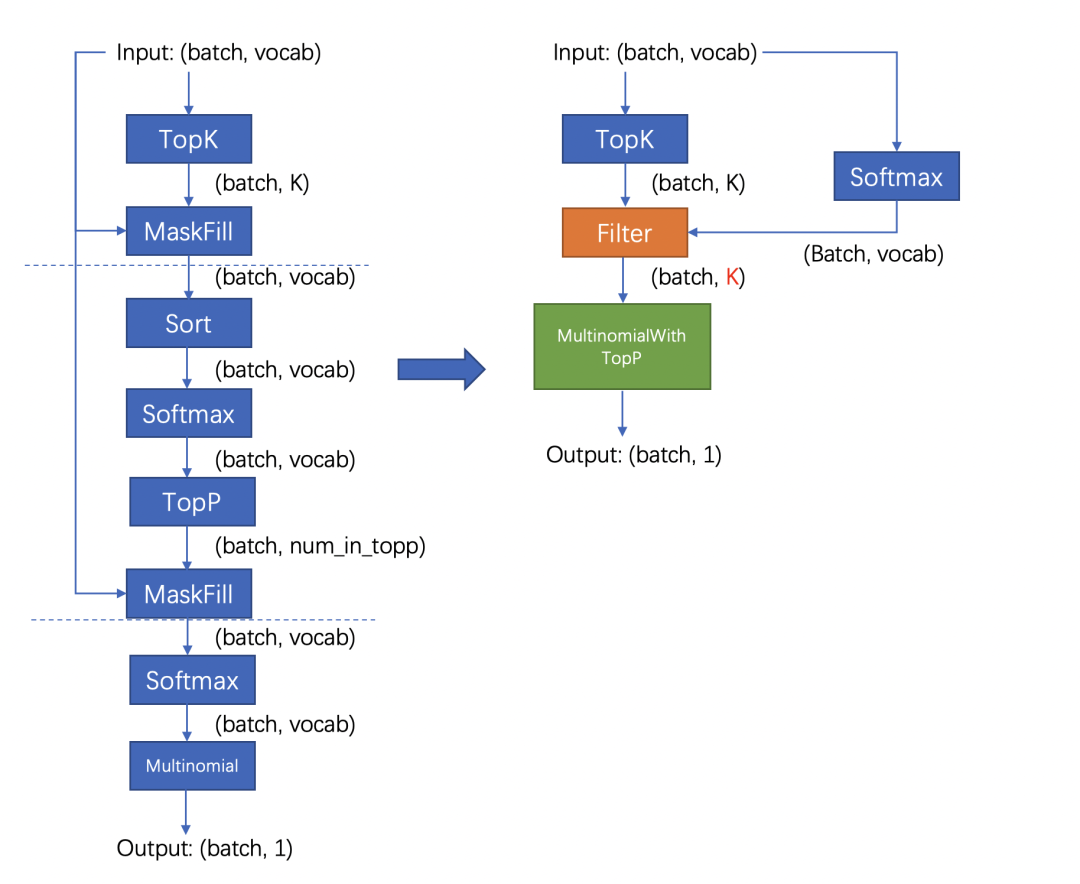
改进后的流程不影响结果分布,且大幅度减少了计算量和 kernel 数量,极大程度减少了采样需要的时间。我们测试优化后的采样流程需要的时间是原来的 1/10。
3.4 总结
我们在店铺起名和文案生成两类任务,对原模型和投机采样模型进行了性能对比。其中原模型是 int8 量化的 Qwen13B 模型,投机采样使用量化后的 Qwen13B 和 Qwen1.8B 模型,在 A10 机器测试结果如下:
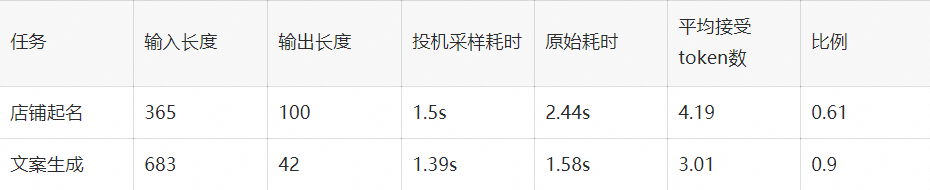
在两类任务下投机采样对模型均有加速,效果随接受 token 数和输入 token 长度变化。我们测得在使用上述条件每轮生成 5 个 token 的情况下,短序列跑一轮需要 60ms,长序列跑一轮需要 70ms。而原模型跑一轮需要 30ms,因此长/短序列只有在拒绝全部 token 的情况下会劣于原模型,其他情况则是与原模型平均 token 时间相近或者优于原模型。由于测试条件限制,相比原论文的大小模型比例(70B:6B),我们大模型和小模型的规模(7B:1.8B)更接近,并且 Qwen 中文模型的词表大小是 152064,相比其他模型(如 Llama 词表大小是 32000)大了数倍,这也额外开销时间变大,因此在其他测试场景下应该还能有更好的表现。
四、存在的问题
上文我们着重介绍了两个优化对推理速度的影响,但除了推理速度外,并行度也是影响大模型吞吐的重要因素。影响并行度的主要因素是显存,大模型的显存占用分三块:模型权重占用显存、运行时显存和 KV cache 显存,KV cache 显存越多,模型能够同时承载的请求数越多,并行度越大。
序列长度较长时,对运行时显存运行最大的是 Softmax Buffer,它的大小和序列的平方成正比,知名优化 FlashAttention 除了能降低模型第一次运行时间外,更重要的作用是消除了 Softmax Buffer 对显存的占用。但比较遗憾的是,FlashAttention 优化的开源实现要求 Attention 计算的 QKV 维度一致,而 KV csache 复用和投机采样都未满足这个条件,导致对显存有额外的占用。除此之外,投机采样因为要额外加载小模型的权重,且运行时需要多保存一份小模型的 KV cache,还需要额外的显存。
五、总结与致谢
以上是我们在大模型推理上做的一些优化尝试,有根据业务场景和实际问题的,也有参考论文实现的,并且都取得了一定的加速效果。但是从极致性能的角度,我们做的还远远不算完美,这些功能在算子层和框架层都还有优化空间,这些是我们后续需要改进的。
除了上述介绍的功能外,RTP-LLM 还支持了非常多的功能,和上文相关的对 System Prompt 进行缓存的 Multi Task Prompt 复用 Medusa 投机采样,以及动态 LoRA 和不规则剪枝模型支持。未来我们也会持续的添加新功能,优化底层算子性能,打造更好的大模型推理框架。
我们的项目主要基于 FasterTransformer,并在此基础上集成了 TensorRT-LLM 的部分 kernel 实现。FasterTransformer 和 TensorRT-LLM 为我们提供了可靠的性能保障。Flash-Attention2 和 cutlass 也在我们持续的性能优化过程中提供了大量帮助。我们的 continuous batching 和 increment decoding 参考了 vllm 的实现;采样参考了 hf transformers,投机采样部分集成了 Medusa 的实现,多模态部分集成了 llava 和 qwen-vl 的实现。感谢这些项目对我们的启发和帮助。
相关资料
[01] FasterTransformer
https://github.com/NVIDIA/FasterTransformer
[02] TensorRT-LLM
https://github.com/NVIDIA/TensorRT-LLM
[03] Flash-Attention2
https://github.com/Dao-AILab/flash-attention
[04] cutlass
https://github.com/NVIDIA/cutlass
[05] vllm
https://github.com/vllm-project/vllm
[06] hf transformers
https://github.com/huggingface/transformers
[07] Medusa
https://github.com/FasterDecoding/Medusa
[08] llava
https://github.com/haotian-liu/LLaVA
[09] qwen-vl
https://github.com/QwenLM/Qwen-VL
这篇关于大模型推理优化实践:KV cache 复用与投机采样的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


