本文主要是介绍AAAI 2021 Structured Co-reference Graph Attention for Video-grounded Dialogue,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
动机
- 基于视频的对话系统(VGDS)允许AI引擎“观察”((即理解一个视频)和“对话”(即,在一个对话中交流理解)。具体地说,给定一个视频,由一系列QA对组成的对话历史,以及一个关于视频的后续问题,目标是推断一个自由形式的自然语言回答问题。近年来,基于视频的对话系统被提出来推进VQA以基于视频与人类进行有意义的对话。
- 虽然最近的努力在提高反应的质量方面取得了很大的进展,但业绩仍然远远不能令人满意。目前的VGDS仍然面临以下两个挑战:(1)如何推导多模态间的指代关系;(2)如何在具有复杂时空动态的视频丰富的底层语义结构上推理。
- SCGA将指代消解从单纯的视觉指代提升到另一个层次,通过结构化的指代图实现文本和视觉的指代。
- 之前的基于视觉的关系推理方法通过全连通图来将不同目标按照关系联系起来。相反,作者构造多模态之间的二分图,形成结构化的指代图。在此基础上,作者不仅在空间轴上建立视频图,而且在时间轴上也建立视频图。在渐进邻域图attention中,作者还为每个头部提供了不同的角色,预先学习冗余特征。
方法
简介

第一个具有挑战性的多模态间的指代问题如图1所示:Q6: “Do he play with it?”包含必须识别名词所指或先行词的代词。从现在起,这一确定代词先行词的任务就被称为“去引用”(dereferencing)。作者的研究表明,在视听场景感知对话(AVSD)数据集中,几乎所有的对话和61%的问题都包含至少一个代词(如“it”、“they”),这使得“去引用”变得不可或缺。现有的VGDS将对话历史作为任何其他输入模态来处理,但是通过识别和解决其关于代词引用的独特问题,可以显著提高输出响应的质量。本文首次提出了一种通过结构化指代图实现文本和视觉指代的VGDS,该指代图将代词的先行词与前面对话中的名词以及视频中检测到的目标进行识别。这种方法可以被认为是先前在视觉对话(VisDial)方面所做努力的延伸,通过attention memory、引用池(是用于任意引用类型(除GameObject)的目标池,可以复用任意引用类型目标,以达到减少系统在频繁创建和删除目标时的开销。)和递归attention来解决视觉指代问题。
第二个具有挑战性的问题是对具有复杂时空动态的视频的丰富的底层语义结构进行推理。基于视频对话任务的大多数先前努力利用了来自I3D模型的整体视频特征,该模型已经在动作识别数据集上进行了预训练,并且它们依赖于完全连接的Transformer架构来隐式学习推断答案。这些努力低估了探测器细粒度视觉表示的价值,因此缺乏捕获相关物体及其关系和时间演化。作者设计了一种基于目标级表示的时空视频图,并对其进行图attention,以实现对视频的全面理解。
本文利用结构化指代图attention(SCGA)来解决上述问题。SCGA包括:(1)结构化指代消解器,通过建立结构化指代图来执行去引用;(2)时空视频推理器,通过梯度相邻图attention来捕获视频的局部到全局动态(GN-GAT)。作者首先选择一个关键的对话历史,可以解决代词在后续问句中的先行词。Gumbel-Softmax使作者能够对对话历史执行离散的attention。作者提出了一个多模态的两部分结构的指代图,并执行图attention,以集成从关键对话历史到问题和视频的信息语义,如图1所示。在此基础上,作者构建了时空视频图,表示目标之间的时空关系。基于最近研究表明每个头部在self-attention中独立地观察相同的全局上下文,学习冗余特征,作者提出了一种由构建的视频图引导的渐进相邻图attention(GN-GAT)。而不是重复计算自己对共同邻域的attention,每个头部查看由其唯一邻接矩阵定义的一种不同邻域。每个邻接矩阵将具有一种唯一的连通性,链路节点在固定的跳数内到达该连通性。因此,与较小数目的跳相关联的头将考虑局部上下文,而与较大数目的跳相关联的头将查看全局上下文。最后,根据观察,回答时所用的词语来自于提问时所用的词语(例如,回答问题“What did he do after closing the window?(他关窗后做了什么?)“He [context verb] after closing the window”),指针网络(主要用在解决组合优化类问题(凸包问题,三角剖分等等),实际上是Seq2Sequence learning中encoder RNN和decoder RNN的扩展,主要解决的问题是输出的字典长度不固定问题(输出字典的长度等于encoder输入序列的长度)。)被结合到响应序列解码器中,以从一种固定的词汇表集合或从在问题中使用的单词进行解码。在AVSD@DSTC7和AVSD@DSTC8数据集(一个具有挑战性的基于视频的对话基准)和TVQA数据集(一个大规模视频QA基准)上验证了所提出的SCGA的有效性。作者的实验结果表明,SCGA在两个基准指标上都优于其他现有的对话系统,同时广泛的消融研究和定性分析揭示了性能的提高和改进的可解释性。
架构

如图2所示,结构化指代图attention(SCGA)是由:(1)输入编码器,(2)结构化指代消解器,(3)时空视频推理器,(4)指针增强Transformer解码器组成。
模型
基于视频的对话任务的正式定义。本文给出了(v, h, qr)的三元组,由视频v,对话h={c,(q1,a1), …, (qr-1, ar-1)}和在当前轮次r∈{1, …, R}询问的一个问题qr组成。对话历史本身就是一组前几轮的问答对,以一个caption c起始。基于视频的对话的目标是生成问题的自由形式的自然语言答案ar。
图2显示了结构化指代图attention(SGGA)原理图,由输入编码器、结构化指代解析器、时空视频推理器和指针增强Transformer解码器组成。对于视频编码器,使用Faster R-CNN提取每一帧t∈{1, ··· ,t}的目标集合vt={vot}o=1O,其中在作者的实验中每个目标vot用一种外观特征向量vot∈Rdv与位置特征bott∈Rdb(t=15,O=6,dv=2048,db=4)。每个位置特征bt=[x, y, w, h]表示一个空间坐标,其中[x, y]表示相对边界框左上点的坐标,[w,h]表示框的宽度和高度。对于文本编码器,作者使用一个可训练的token级嵌入层来映射token索引序列为d维特征表示。为了合并源token的排序信息,作者在嵌入层顶部应用位置编码和层归一化。编码的问题(qr)和每一个对话历史({hi}i=1r-1)定义为:
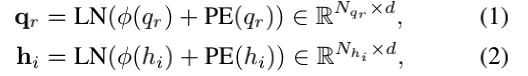
其中Nx表示序列x的token数。
具体来说,模型包括以下几部分:
-
结构化指代消解器。
1)文本指代消解。作者观察到存在一个关键的对话历史可以解决当前问题中的指代。为了将来自对话历史的语义信息注入到文本指代消解的问题token表示中,作者首先确定一个关键对话历史,然后让问题token去关注关键对话历史token。在作者的框架中,作者通过Gumbel-Softmax实现这些功能,以对对话历史执行离散attention,并对连接所有问题token到所有对话token的二分图执行图attention。通过这种方式,问题token学会将关键对话历史的信息语义隐式地集成到其表示中。
人们可以很容易地认为,当前的问题只是从最近的对话历史中得出的。然而,有时候问题需要在一个更早的对话上进行回顾。这意味着当前的问题和最近的对话历史间是没有关系的。灵感来自Gumbel-Max的技巧和持续的softmax relaxations,作者选取一个对于当前问题qr的最相关的对话历史hrd。多亏了Gumbel-Softmax,作者的方法可以在进行离散决策时进行端到端训练。作者首先计算问题特征qr和各个对话历史特征{h0, ··· , hr−1}之间的匹配分数sr,i。
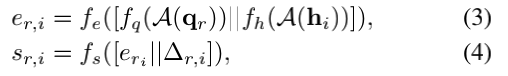
其中[·||·]表示拼接操作,A表示单词轴上的平均操作,fx是输入x的全连接层。在这里,∆r,i=r-i提供了对话历史中qr和hi之间的距离信息。Gumbel-Softmax生成对于对话历史的离散attention的r维独热向量gr:
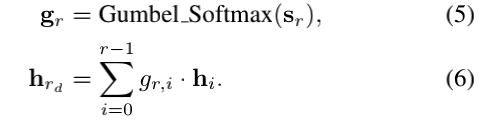
作者通过处理来自问题qr和相关对话历史hrd作为图节点,形式化地定义了文本指代图Gtxt=(Vtxt,Etxt)。在设计一个指代消解器中,作者构造了一个二分图和执行图attention,将相关对话历史中有用的语义信息注入到查询表示中。首先将qr和hrd沿单词轴拼接,得到一个异构节点矩阵:
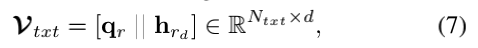
其中Ntxt=Nqr+Nhrd为节点数。然后进行多头self-attention来建模每个节点与其相邻节点之间的关系。对于每个头部k,attention系数ai,jk表示两个链接的节点Vi和Vj之间的相关性,它被计算如下:
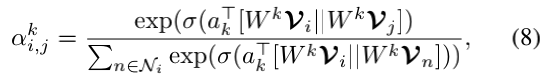
其中σ(·)是一个非线性函数,如LeakyReLU,ak∈R2d是attention权重向量,wk∈Rd×d是共享投影矩阵,Ni是的邻域节点i。图节点特征通过K更新独立的attention机制,并将它们输出特征:
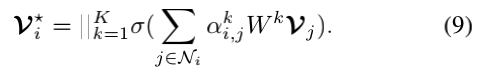
最后,作者将原始Vi添加到更新的Vi*和采用对应于问题token的节点作为最终的指代消解的问题表示:
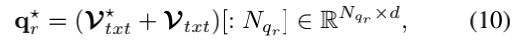
其中[: i]表示沿着节点轴切片操作。2)视频指代消解。视觉指代消解的流程线是类似于文本指代消解。视频目标学习从指代消解的问题到其表示的形式语义的隐式集成。作者首先通过线性变换将每个外观特征vkt投影到d维空间(其中d与文本嵌入中的d相同)。作者还在线性变换的基础上添加了层归一化,以确保外观特征具有与文本表示相同的尺度vot:=LN(Wvot)。再一次,作者将视频中的每一个目标和指代消解问题中的token作为图节点,构造了二分部视觉指代图Gvid=(Vvid,Evid):
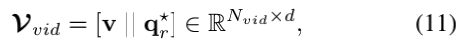
其中,Nvid=Nv+Nqr,Nv=T×O。作者执行图Gvid上的图attention并获得更新的图节点。最后,作者选取与目标相对应的节点作为最终的指代解析视频表示:
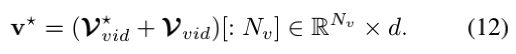
-
时空视频推理器。作者首先构造了一个时空视频图Gst=(Vst, Est),它代表了检测到的目标间的时空,并利用作者提出的渐进邻图注意(GN-GAT)对视频丰富的语义结构进行推理,具有复杂的时空动态。最近的研究显示多头self-attention由于对每个attention头重复使用相同的输入上下文,因此在学习冗余特征方面受到了限制。本文提出的GN-GAT不是重复计算同一邻域上的self-attention,而是每个头对应不同的邻接矩阵,其连通度随图节点的距离而渐进增加。作者可以有效地对视频的时空动态进行局部到全局的建模和推理。当使用指代消解视频表示V*∈RNv×d作为图节点Vst,作者定义了两组边缘矩阵,{Et}t=1T{Et+1}t-1捕获每个帧内的空间关系,{Ett+1}t=1T-1捕获在相邻帧之间时间关系,建立图边Est。这里,作者使用位置特征bot以获得Et和Ett+1。对于空间关系矩阵Et∈RO×O的标准是被定义为max(∆x,∆y)<τs。具体地说,Et[i, j]=1,如果在第t帧中第i个目标和第j个目标足够接近以匹配上面的标准。对于时间关系矩阵Ett+1的标准是被定义为具有相同目标标签的max(∆x,∆y)<τt。同样,如果第t帧中的第i个目标和第t+1帧中的第j个目标是足够接近并且具有相同的目标标签,则Ett+1[i, j]=1。最后,将图边Est∈RNv×Nv是被构造为如下所示:

GN-GAT对构造的时空视频图Gst进行推理。对于图节点间距离n的邻接矩阵可以被计算为Est的第n次方的布尔值:
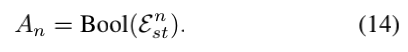
这样,作者就可以在一个单一的图attention层内,有效地从视频的局部(即较低距离n)逐步学习到全局(即较高距离n)。作者将更多的头分配给更高的n,因为全局上下文包含比局部上下文更密集的邻域。最后,作者通过执行GN-GAT得到Vst*:
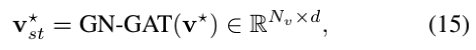
其中GN-GAT被表述作为公式8、9,其中每个头部的邻接矩阵定义不同的邻域。 -
指针扩展解码器
通过合并问题来解码答案响应和视频表示。根据先前的工作,作者以自回归方式解码答案token。作者设计了一个由四个attention层组成的Transformer解码器:对迄今部分生成答案的masked self-attention(arin),用于选择历史(hrd)的引导attention,用于来自结构化指代消解器的问题(qr*)的引导attention,用于来自时空视频推理器的视频(vst*)的引导attention。
transformer解码器上的每个attention都是关于查询、键和值张量的多头attention:Attention(Q, K, V)。作者的Transformer解码器可以制定为:
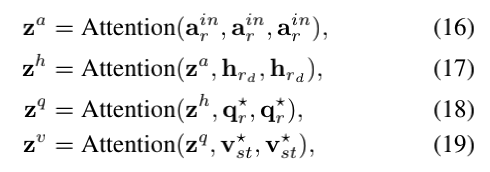
其中arin∈Rj×d是嵌入文本编码器的第j解码步骤部分生成的答案。注意,作者mask了第一个self-attention层,以确保答案解码中的因果关系。在第j个解码步骤中,作者从固定的词汇分布pjvoc中或者从动态指针分布pjptr通过argmax操作,在pj=[pjvoc||pjptr]上选择单词索引:
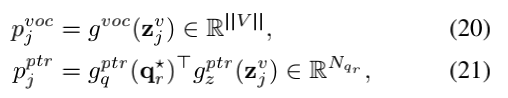
其中gvoc是用于词汇表大小为||V||维的线性层,而gxptr是用于d维度的一个线性层。通过问题token表示(即gqptr(qr*))和解码器输出(即gzptr(zjv))间的双线性交互获得来自动态指针网络的对数。
-
优化。
在训练过程中,作者使用教师强制(Lamb et al.2016)来监督每个解码步骤,即使用ground-truth token作为解码器输入。由于答案token既可以出现在固定词汇表上,也可以出现在问题token上,作者在连接token分布pj上用多标签二进制交叉熵损失训练模型。作者将两个特殊的token和添加到作者的固定答案词汇表中,其中作为解码器的第一步,表示句子的开始,表示句子的结束,以停止解码过程。
实验




作者在最近的两个数据集AVSD和TVQA上验证了作者提出的SCGA。
除了AVSD的结果,作者还在作者修改的设置上向TVQA基准报告结果。作者把每段视频对应的字幕作为作者在电视问答中的对话历史。作者将SCGA与使用公共代码库复制的两种基线方法进行了比较。表3显示SCGA在CIDEr度量上优于基线方法。字幕在回答问题时起着提供线索的重要作用。以往的多择设置中的TVQA倾向于通过时间注意或时间定位来定位关键句子。作者在TVQA上的实验结果表明,SCGA在优于其他现有的对话系统SCGA,不仅能够解决指代问题,而且能够从字幕中定位关键句子。
小结
提出了一种基于视频的对话系统,称为结构化指代图 Attention(SCGA)来解码关于给定视频的问题的回答序列,同时跟踪对话上下文。SCGA是基于(1)通过在多模态上构建结构化图来执行去引用的结构化指代消解器;(2)通过渐进相邻的图attention来捕获视频的局部到全局动态的时空视频推理器。SCGA利用指针网络动态复制部分问题,对答案序列进行解码。在AVSD@DSTC7和AVSD@DSTC8数据集和TVQA数据集上验证了所提出的SCGA的有效性。作者的实验结果表明,SCGA在两个基准指标上都优于其他现有的对话系统,同时广泛的消融研究和定性分析揭示了性能的提高和改进的可解释性。
这篇关于AAAI 2021 Structured Co-reference Graph Attention for Video-grounded Dialogue的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








