本文主要是介绍《Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks》论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 文章介绍
- 文章模型
- 通过依赖树构建图
- 学习特定方面实体的表示
- 总结
文章地址: https://www.sciencedirect.com/science/article/pii/S0950705121009059
文章介绍
最近,图卷积神经网络因为其优越的性能(能很好的考虑词语间的依赖)被广泛的应用在自然语言处理任务当中。其一般方式为首先将文本转化为邻接矩阵的形似,然后结合文本的特征表示即可输入到GCN中,但是现有的研究大多针对于如何更好的表示词语间的依赖,而忽略了上下文的情感知识。因此这篇文章在结合SenticNet的基础上构建词语间的依赖,提出了Sentic GCN。
文章模型
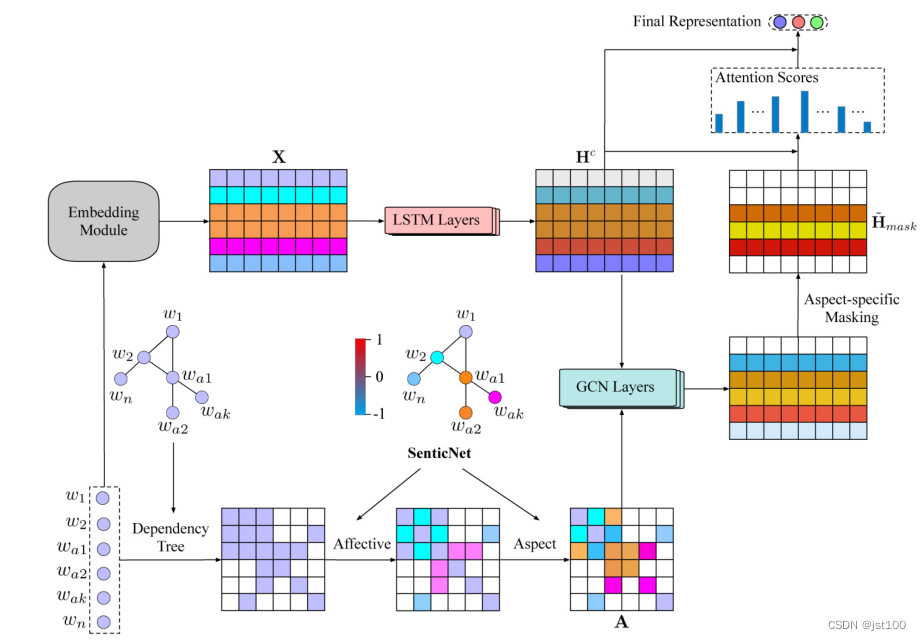
文章提出模型框架如上图所示,嵌入层可选用glove或者BERT,然后通过双向LSTM或者文本的特征向量表示。在另一方面通过spacy工具,在结合SenticNet的基础上生成词语之间的依赖最后输入到GCN中完成分类。
通过依赖树构建图
对于每一句话作者首先采用了最基本的spacy工具生成词语间的邻接矩阵,


然后通过SenticNet(开源的)获取每个单词的情感评分,并与邻接矩阵相加
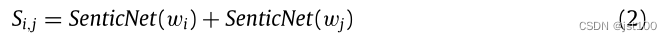
此外,现有的基于GCN的方面情感分析模型在构建图时通常忽略了对给定方面的重要关注。因此,在这项工作中,作者 基于SenticNet进一步增强了上下文词和体词之间的情感依赖性,最终表示如下

对于GCN的使用,作者是直接借鉴了2017年那一篇的经典文章这里赘述。
学习特定方面实体的表示
这里作者对不属于特定实体的表示直接处理为0

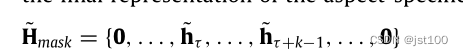
除此之外作者还应用了检索注意力机制等方式进一步提高模型的得分。
总结
目前对于模型的学习越发的依赖于各种复杂的对于文本的处理,也就越要求我们能细致的理解模型本身。对于外部知识的借鉴肯定是非常正确的,但直接将情感分数和邻接矩阵的0-1表示相加的意义确实有待商榷。
这篇关于《Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks》论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)