本文主要是介绍Python批量爬取高德AOI边界数据+GIS可视化(超详细),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、需求
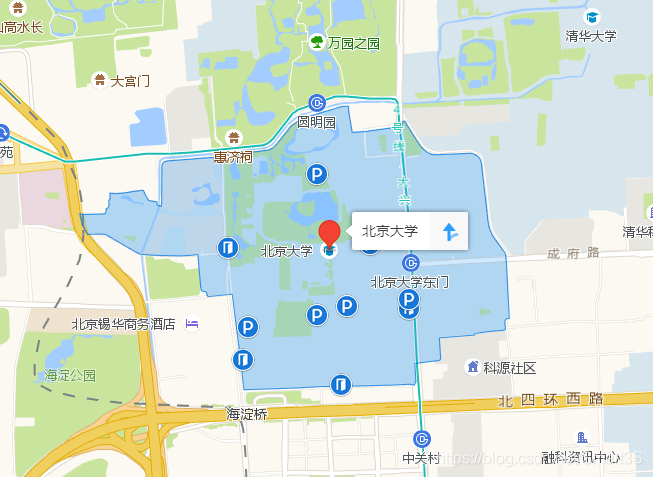
爬取高德地图的AOI区域(如下)并进行可视化存储,且保留AOI的属性信息。
二、使用的工具:
Python IDLE、记事本编辑器、ArcGIS 10.2、申请的高德开发者KEY(免费)。
三、实现分析及思路
博主在浏览博客时得到了一个链接,能够根据aoi编号检索aoi信息:
https://ditu.amap.com/detail/get/detail?id=XXXX
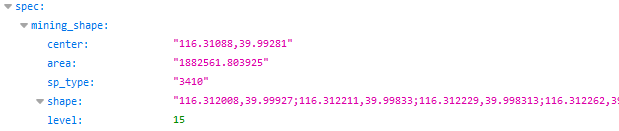
感谢“万里写入胸怀间”大神的博客:https://blog.csdn.net/qq_37696858/article/details/81351725该链接能够返回丰富的AOI信息:
AOI编号有两种途径获得:
(1)使用API检索POI时,返回的POI编号(经验证,AOI编号与POI编号是一致的)如下图。

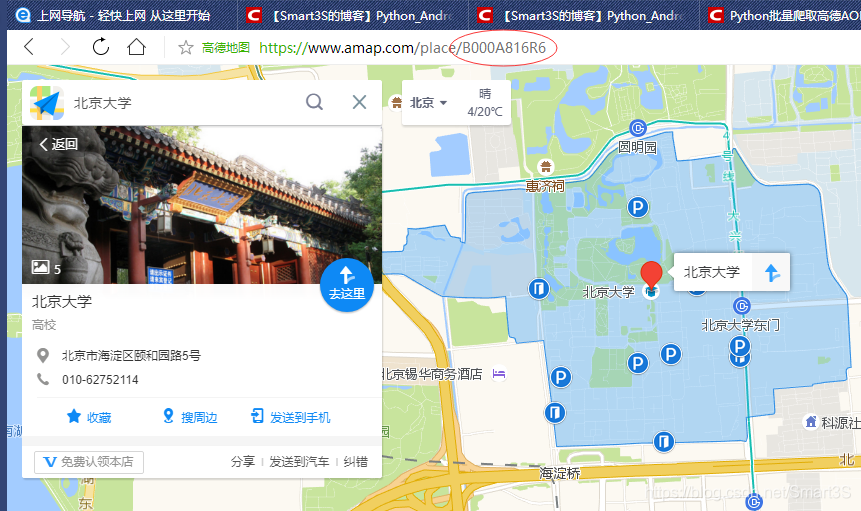
(2)使用高德地图web版进行地点搜索时,点击单个POI,从当前网页的Url中提取,如下图。
第二种方式最为简单便捷,但是无法实现批量的AOI提取,因此本文采用第一种方式进行AOI爬取。使用该方式会带来一些问题,例如,有些POI是不存在AOI区域的,比如厕所、大门等一些附属设施POI,但是AOI链接仍然会检索出信息来,只是不含有图形信息罢了,因此对是否含有AOI信息进行判断也十分重要。
四、编写代码:
import requests
import pandas as pd
import json
import time#检索POI的URL
poiUrl="https://restapi.amap.com/v3/place/text?keywords=大学&city=青岛&output=JSON&offset=20&key={你的Key,不含大括号}&extensions=all&page="
#检索AOI的URL
aoiUrl="https://ditu.amap.com/detail/get/detail?id="
#用于储存POI数据
x=[]
#用于储存AOI数据
y=[]
#计数
num=0
#逐页POI检索,注意API限制
for page in range(1,7):#构造URLthisUrl1=poiUrl+str(page)#获取POI数据data1=requests.get(thisUrl1)#转为JSON格式s=data1.json()#解析JSONaa=s["pois"]#对每条POI进行读取for k in range(0,len(aa)):poiid=str(aa[k]["id"])#构造AOI的URLthisUrl2=aoiUrl+poiid#获取AOI数据data2=requests.get(thisUrl2)#转为JSON格式ss=data2.json()#解析JSONaaa=ss["data"]key=aaa["spec"]#判断AOI检索是否包含形状信息haveShp=0for item in key:if item=="mining_shape": #有形状信息haveShp=1if haveShp==0:continue #若无则跳出本条POI检索#获取POI信息并存储pois1=aa[k]["name"]pois2=aa[k]["type"]pois3=aa[k]["address"]pois4=aa[k]["adname"]pois5=aa[k]["location"].split(",")x.append([poiid,pois1,pois2,pois3,pois4,float(pois5[0]),float(pois5[1])])#获取AOI信息并存储aoilocs=str(key["mining_shape"]["shape"])locs=aoilocs.split(';')order=0for i in range(0,len(locs)):loc=locs[i].split(',')lon=loc[0]lat=loc[1]y.append([poiid,pois1,pois2,pois3,pois4,order,lon,lat])order+=1num+=1print("爬取了 "+str(num)+" AOI数据")time.sleep(random.randint(0,5)) # 暂停0~3秒的整数秒,时间区间:[0,5]
#将数据结构化存储至规定目录的CSV文件中
c1 = pd.DataFrame(x)
c1.to_csv('E:/poi.csv',encoding='utf-8-sig')
c2 = pd.DataFrame(y)
c2.to_csv('E:/aoi.csv',encoding='utf-8-sig')注意:
(1)aoi信息获取链接官方并没有完全开放,需谨慎使用,因此博主在代码里增加了较长的暂停时间,但可能仍然无法有效避免封IP的情况,需小心谨慎使用。
(2)注意POI的检索是有限制的,可参考博主的另一篇博文:Python突破高德API限制完全爬取POI兴趣点数据
(2)最终爬取下来的坐标是GCJ-02坐标系,若要对数据进行应用,需转换为WGS84坐标系,本文省略了该步骤。
运行结果:
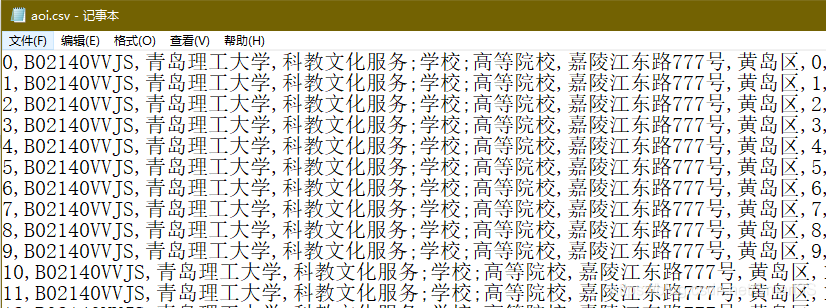
即可在目标目录看到生成了两个文件poi.csv和aoi.csv,将它们的首行数据删除,如下:

五、数据可视化
1、打开Arcmap,将生成的poi.csv和aoi.csv加入:
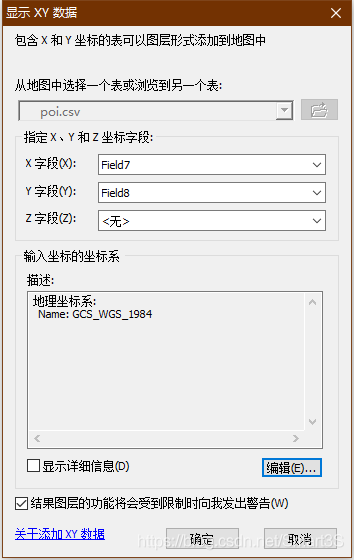
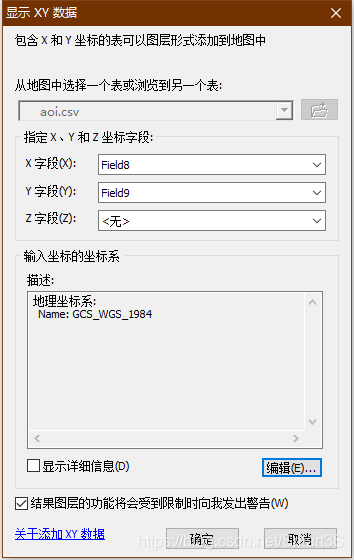
2、对poi表右键,显示XY数据,并进行下图设置点击确定,并对aoi表也进行相似的操作如下图。
3、之后可以看到生成了一堆poi和aoi点:

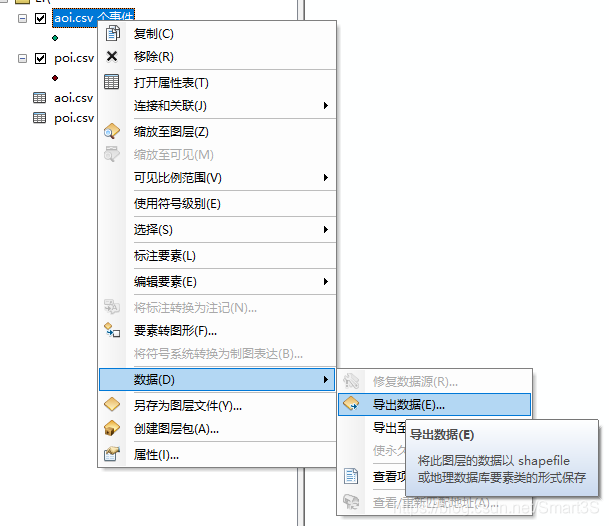
4、之后对生成的两个要素点击右键,数据→导出数据,设置相关路径,保存为shp文件,如下图:
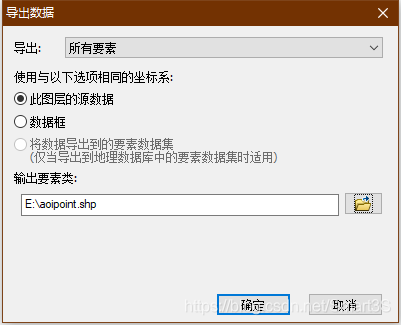
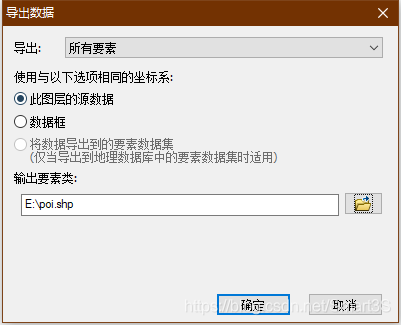
5、打开ArcToolbox,找到数据管理工具→要素→点集转线,打开点集转线工具,将aoi点数据输入并进行以下设置:
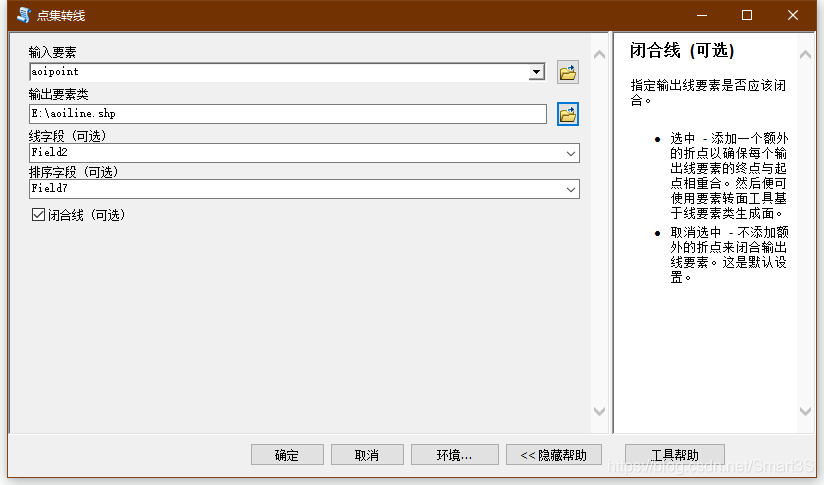
点击确定,发现AOI边界已见雏形:

6、接下来将边界线转换为面文件,打开ArcToolbox,找到数据管理工具→要素→要素转面,打开要素转面工具,将aoi线数据输入并进行以下设置:
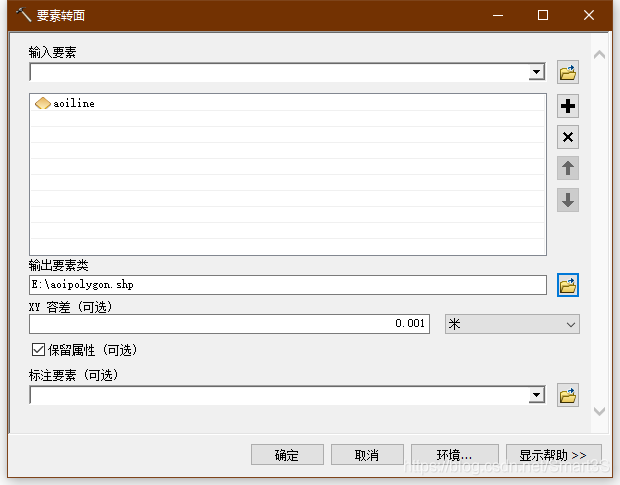
点击确定,即可发现AOI区域已经生成。

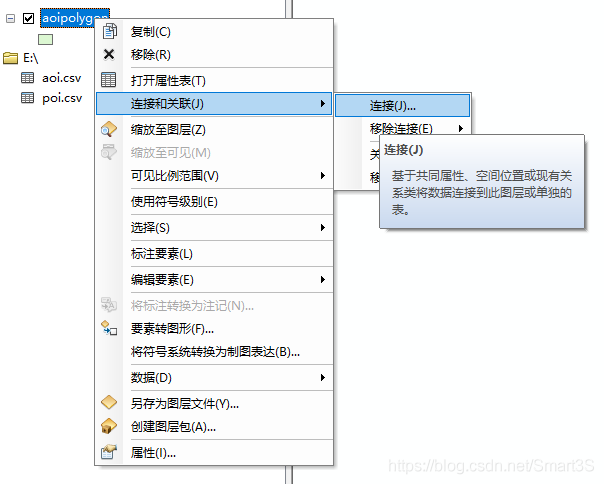
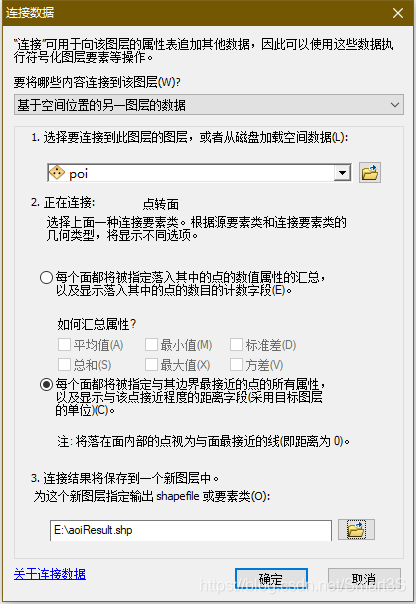
7、打开生成的面要素的属性表,发现属性信息已完全消失。接下来是使用上面生成的POI数据进行属性信息的找回,右键AOI面要素,点击连接和关联→连接,并进行如下设置:
8、点击确定,在生成的要素中打开属性表,可以发现属性信息已找回:

关于GIS可视化的步骤,博主觉得还是有些繁琐,如果大神们有更简单的方法欢迎交流~
这篇关于Python批量爬取高德AOI边界数据+GIS可视化(超详细)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





