本文主要是介绍正确率、召回率、F1-Score,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
评估指标
我们希望参赛队的预测, 预测的品牌准确率越高越好,也希望覆盖的用户和品牌越多越好,所以用最常用的准确率与召回率作为排行榜的指标。
准确率:
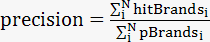
注:
N 为参赛队预测的用户数
pBrandsi为对用户i 预测他(她)会购买的品牌列表个数
hitBrandsi对用户i预测的品牌列表与用户i真实购买的品牌交集的个数
召回率:
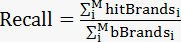
注:
M 为实际产生成交的用户数量
bBrandsi为用户i 真实购买的品牌个数
hitBrandsi预测的品牌列表与用户i真实购买的品牌交集的个数
最后我们用F1-Score 来拟合准确率与召回率,并且大赛最终的比赛成绩排名以F1得分为准。
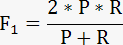
这篇关于正确率、召回率、F1-Score的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









