正确率专题

【YOLO学习】召回率(Recall),精确率(Precision),平均正确率(Average_precision(AP) ),交除并(Intersection-over-Union(IoU))
摘要 在训练YOLO v2的过程中,系统会显示出一些评价训练效果的值,如Recall,IoU等等。为了怕以后忘了,现在把自己对这几种度量方式的理解记录一下。 这一文章首先假设一个测试集,然后围绕这一测试集来介绍这几种度量方式的计算方法。 大雁与飞机 假设现在有这样一个测试集,测试集中的图片只由大雁和飞机两种图片组成,如下图所示: 假设你的分类系统最终的目的是:能取出测试集中所有飞机的

Kimi GPT4专业问题正确率大比拼
最近Kimi很火,我测试了他在ArcGIS Pro这个软件的使用问题上的专业度,发现还差的比较远。 问题:arcgis 在操作过程中, For the Vegsoil layer, set the Symbology to Unique Values using the VEG_CLASS attribute这个步骤我不懂,能解释下吗? GPT4回答:非常完美的标准答案 Kimi回答:完全是

【机器学习】分类性能度量指标 : ROC曲线、AUC值、正确率、召回率、敏感度、特异度
本文转自 http://zhwhong.ml/2017/04/14/ROC-AUC-Precision-Recall-analysis/ 在分类任务中,人们总是喜欢基于错误率来衡量分类器任务的成功程度。错误率指的是在所有测试样例中错分的样例比例。实际上,这样的度量错误掩盖了样例如何被分错的事实。在机器学习中,有一个普遍适用的称为混淆矩阵(confusion matrix)的工具,它可以帮助人们更

java计算正确率或百分比
//方法1public static String accuracy(double num, double total, int scale){DecimalFormat df = (DecimalFormat)NumberFormat.getInstance();//可以设置精确几位小数df.setMaximumFractionDigits(scale);//模式 例如四舍五入df.setR
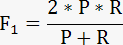
正确率、召回率、F1-Score
评估指标 我们希望参赛队的预测, 预测的品牌准确率越高越好,也希望覆盖的用户和品牌越多越好,所以用最常用的准确率与召回率作为排行榜的指标。 准确率: 注: N 为参赛队预测的用户数 pBrandsi为对用户i 预测他(她)会购买的品牌列表个数 hitBrandsi对用户i预测的品牌列表与用户i真实购买的品牌交集的个数 召回率: 注: M 为实际产生成交的用户数量

通义千问关于网络模块的专业知识能力正确率测试
闲着无聊,就用问答区的一个问题,去考验了通义千问,结果优点出乎意料。 我们来看一下具体的问题,这里,我准备了三个问题: 第一个问题:11.192.0.x 注意,这里我并没有增加任何的辅助提示词,而是直接问:11.192.0.x。这是一个开放式的提问。接着看一下通义千问的回答: 通义千问显示回答:11.192.0.x是一个IPv4地址段,这个是对的。属于私有IP地址范围。???着属于私有IP地
话说正确率、召回率和F值
正确率、召回率和F值是在鱼龙混杂的环境中,选出目标的重要评价指标,本文就针对这三个指标得瑟得瑟。 不妨看看这些指标的定义先: 正确率 = 正确识别的个体总数 / 识别出的个体总数 召回率 = 正确识别的个体总数 / 测试集中存在的个体总数 F值 = 正确率 * 召回率 * 2 / (正确率 + 召回率) 不妨举这样一个例子:某池塘有1400条鲤鱼,3
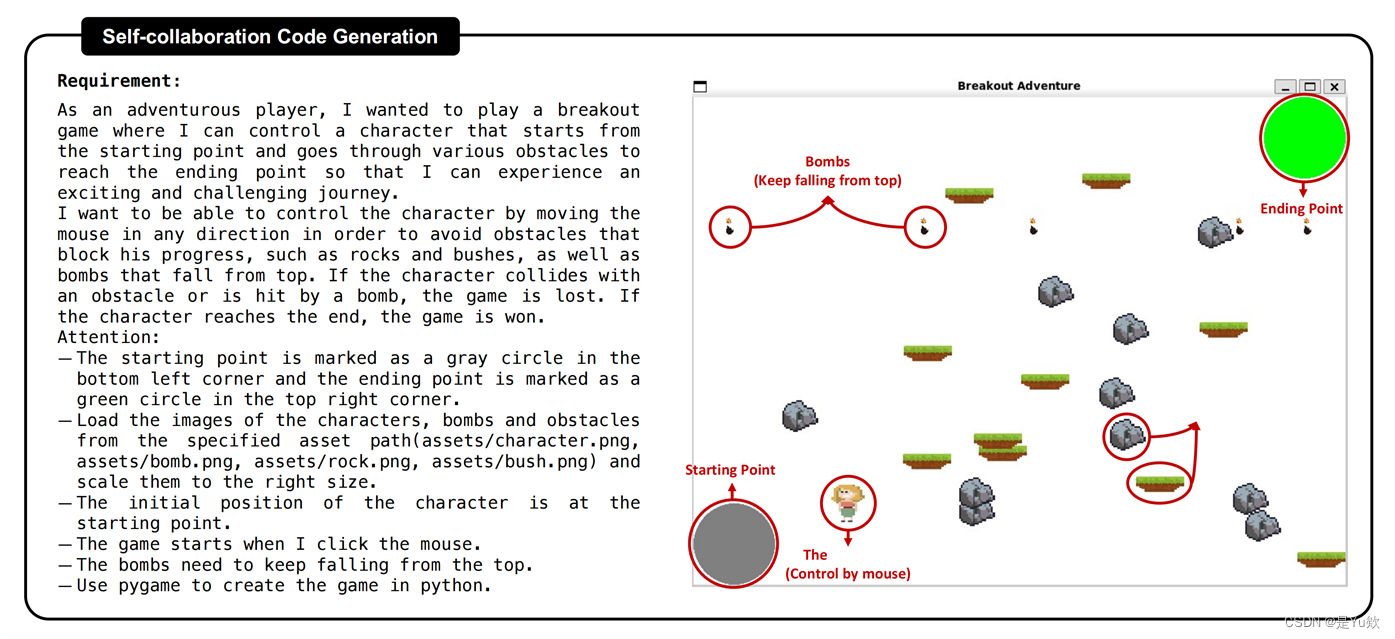
AI与Prompt:解锁软件开发团队的魔法咒语,在复杂任务上生成正确率更高的代码
AI与Prompt:解锁软件开发团队的魔法咒语 写在最前面论文:基于ChatGPT的自协作代码生成将团队协作理论应用于代码生成的研究自协作框架原理1、DOL任务分配2、共享黑板协作3、Instance实例化 案例说明简单任务:基本操作,生成的结果1)分析员:分解任务+制定high-level计划2)程序员:按照计划生成对应代码3)测试员:检验代码的功能性和边缘测试情况,反馈错误让程序员修改

分类模型的评估方法-正确率(Accuracy)
我们知道,机器学习的一大任务是”分类”。我们构建了一个分类模型,通过训练集训练好后,那么这个分类模型到底预测效果怎么样呢?那就需要进行评估验证。 评估验证当然是在测试集上。问题是,我通过什么评估这个分类模型呢?也就是说我们怎么给这个模型打分呢? 想想我们上学时的考试,总分100分,总共100道题,作对1题给1分,最后会有一个得分,例如80分,90分,换算成百分比就是80%,90%,这是我们自然
英语阅读太难?掌握6大技巧让正确率达到90%
参加过英语(精品课)考试的人应该都知道,在英语考试中,阅读理解部分的分值占整个试卷分值的很重,但又很容易丢分。150分题要想上100分,阅读理解就一定不可以丢分太多。 所以做阅读速度的快慢、对文章内容理解掌握的程度,往往直接影响到英语考试的成绩高低。但我的学生普遍给我反应,说现在英语考试的时间太紧张了,几乎没有时间慢慢琢磨,这就必须要实现英语快速阅读。有没有一个好的解决办法呢? 其实,是

Mnist模型识别自己手写数字正确率低的原因
做老板的助教,大三学生问的比较多的问题,记录一下。 问题背景: 有的同学用官方的训练数据mnist训练好自己的模型后,自己制作数字图片给训练好的模型识别,结果正确率只有40%多,甚至用原来训练的数据集识别正确率都低于50%. 解决方法: 可以从下面几个方面入手,把自己手写的数字识别率提高到80%不难: 原因1:西方手写体和东方手写体造成的样本差异